
[TOC] 序言:這一章我們學習字元串、列表、元組、字典 等常用存儲結構 1. 字元串 所謂 字元串 ,就是由零個或多個字元組成的有限序列 ,簡單來說:雙引號或者單引號中的數據,就是字元串 通過下麵代碼,我們來瞭解一下字元串的使用 輸出結果 str = "helloworld" | 方 ...
目錄
序言:這一章我們學習字元串、列表、元組、字典 等常用存儲結構
1. 字元串
所謂字元串,就是由零個或多個字元組成的有限序列 ,簡單來說:雙引號或者單引號中的數據,就是字元串
通過下麵代碼,我們來瞭解一下字元串的使用
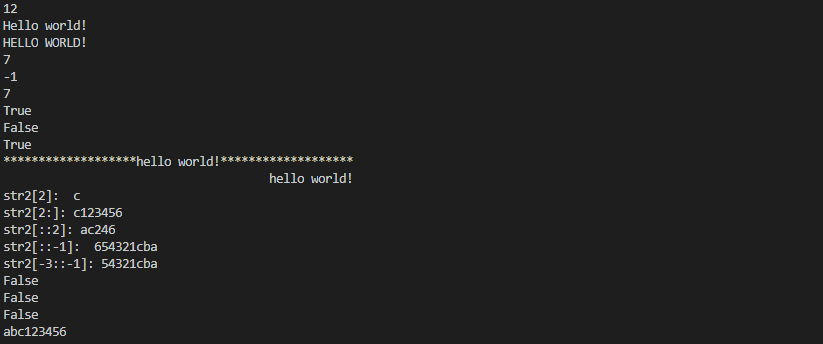
# -*- coding:utf-8 -*-
def main():
str1 = 'hello world!'
#通過len 計算函數字元串的長度
print(len(str1))
#獲得字元串首字母大寫的拷貝
print(str1.capitalize())
#獲得字元串全大寫的拷貝
print(str1.upper())
#查詢or 是否被包含str1中 包含返回索引值
print(str1.find("or"))
#查詢and 是否被包含str1
print(str1.find("and"))
#index 與find類似 但是找不到會拋異常
print(str1.index("or"))
#print(str1.index("or"))
#檢查字元串是否以指定的字元串開頭
print(str1.startswith("he"))
print(str1.startswith("1he"))
#檢查字元串是否以指定的字元串結尾
print(str1.endswith("!"))
#將字元串以指定的寬度居中 併在兩邊添加指定的字元
print(str1.center(50,"*"))
print(str1.rjust(50," "))
str2 = "abc123456 ";
# 字元串切片:從字元串中取出指定位置的字元
print("str2[2]: ",str2[2])
print("str2[2:]:",str2[2:])
print("str2[::2]:",str2[::2])
print("str2[::-1]:",str2[::-1])
print("str2[-3::-1]:",str2[-3::-1])
# 檢查字元串是否由數字構成
print(str2.isdigit())
# 檢查字元串是否由字母構成
print(str2.isalpha())
# 檢查字元串是否由數字字母組成
print(str2.isalnum())
#去除兩側空格
print(str2.strip())
if __name__ == '__main__':
main()輸出結果
str = "helloworld"
| 方法 | 說明 | 結果 |
|---|---|---|
| len(str) | 字元串長度 | 10 |
| str.capitalize() | 字元串首字母大寫 | Helloworld |
| str.upper() | 字元串全大寫 | HELLOWORLD |
| str.find("or") | 檢測 "or" 是否包含在 str 中,如果是返回開始的索引值,否則返回-1 | 6 |
| str.startswith("h") | 檢查字元串是否以指定的字元串開頭 | True |
| str.endswith("!") | 檢查字元串是否以指定的字元串結尾 | False |
| str.center(20,"*") | 將字元串以指定的寬度居中 併在兩邊添加指定的字元 | *****helloworld***** |
| str.isdigit() | 檢查字元串是否由數字構成 | False |
| str.isalpha() | 檢查字元串是否由字母構成 | True |
| str.strip() | 去除兩側空格 | helloworld |
2. 列表
列表是Python中內置有序、可變序列,列表的所有元素放在一對中括弧“[]”中,並使用逗號分隔開
列表常用方法
| 方法 | 說明 |
|---|---|
| lst.append(x) | 將元素x添加至列表lst尾部 |
| lst.extend(L) | 將列表L中所有元素添加至列表lst尾部 |
| lst.insert(index, x) | 在列表lst指定位置index處添加元素x,該位置後面的所有元素後移一個位置 |
| lst.remove(x) | 在列表lst中刪除首次出現的指定元素,該元素之後的所有元素前移一個位置 |
| lst.pop([index]) | 刪除並返回列表lst中下標為index(預設為-1)的元素 |
| lst.clear() | 刪除列表lst中所有元素,但保留列表對象 |
| lst.index(x) | 返回列表lst中第一個值為x的元素的下標,若不存在值為x的元素則拋出異常 |
| lst.count(x) | 返回指定元素x在列表lst中的出現次數 |
| lst.reverse() | 對列表lst所有元素進行逆序 |
| lst.sort(key=None, reverse=False) | 對列表lst中的元素進行排序,key用來指定排序依據,reverse決定升序(False),還是降序(True) |
| lst.copy() | 返回列表lst的淺複製 |
2.1 列表的增刪改查
def main():
list1 = [1,3,5,7,100]
print(list1)
list2 = ['hello'] * 5
print(list2)
# 計算列表的長度
print("列表的長度為:",len(list2))
#下標索引
print("索引為0的元素:",list1[0])
print("索引為3的元素:",list1[3])
print("索引為-1的元素:",list1[-1])
#修改元素
list1[2] = 300
print("修改結果:",list1)
#添加元素
list1.append(121)
print("append添加元素的結果:",list1)
list1.insert(1,676);
print("insert插入元素的結果:",list1)
list1 += [700,800]
print("+=添加元素:",list1)
#刪除元素
list1.remove(700) #移除某個元素
print("remove移除元素:",list1)
list1.pop(); #移除列表最後一位元素
print("pop移除最後一位",list1)
del list1[0] #移除某個下標的元素
print("del移除:",list1)
list1.clear() #清空列表
print("清空後的列表:",list1)
if __name__ == "__main__":
main()輸出結果

2.2 列表的切片和排序
1、列表的切片操作
"""
列表的切片操作
version:0.1
author:coke
"""
def main():
names = ["A","B","C","D"]
names += ["E","F","G"]
# 迴圈遍歷列表元素
for name in names:
print(name,end = " ")
print()
# 列表切片
names2 = names[1:4]
print("names2:",names2)
# 可以完整切片操作來複制列表
names3 = names[:]
print("names3:",names3)
# 可以通過反向切片操作來獲得倒轉後的列表的拷貝
names4 = names[::-1]
print("names4:",names4)
if __name__ == "__main__":
main()輸出結果

2、列表的排序操作
"""
列表的排序操作
version:0.1
author:coke
"""
def main():
list1 = ["A","Be","C","D","E"]
list2 = sorted(list1)
print("list2:",list2)
# sorted函數返回列表排序後的拷貝不會修改傳入的列表
list3 = sorted(list1,reverse=True)
print("list3:",list3)
# 通過key關鍵字參數指定根據字元串長度進行排序 而不是預設的字母表順序
list4 = sorted(list1,key=len)
print("list4:",list4)
if __name__ == "__main__":
main()輸出結果

2.3 生成式語法
我們還可以使用列表的生成式語法來創建列表
"""
生成試語法創建列表
version:0.1
author:coke
"""
import sys
def main():
f = [x for x in range(1,10)]
print("f:",f)
f = [ x + y for x in "ABCDE" for y in "1234567"]
print("f:",f)
#通過列表的生成表達式語法創建列表容器
#用這種語法創建列表之後 元素已經準備就緒所有需要耗費較多的記憶體空間
f = [x ** 2 for x in range(1,1000)]
print("生成試語法:",sys.getsizeof(f)) #9024
#print(f)
#請註意下麵的代碼創建的不是一個列表 而是一個生成器對象
#每次生成器對象可以獲取到數據 但它不占用額外的空間存儲數據
#每次需要數據的時候就通過內部運算得到數據
f = (x ** 2 for x in range(1,1000))
print("生成器對象:",sys.getsizeof(f))
print(f)
"""
for val in f:
print(val)
print(sys.getsizeof(f))
"""
if __name__ == "__main__":
main()輸出結果

除了上面提到的生成器語法,Python中還有另外一種定義生成器的方式,就是通過yield關鍵字將一個普通函數改造成生成器函數。下麵的代碼演示瞭如何實現一個生成斐波拉切數列的生成器。所謂斐波拉切數列可以通過下麵遞歸的方法來進行定義:
"""
定義生成器
version:0.1
author:coke
"""
def fib(n):
a,b = 0,1
for _ in range(n):
a,b = b, a+b
yield a
def main():
for val in fib(20):
print(val)
if __name__ == '__main__':
main()
3. 元組
Python的元組與列表類似,不同之處在於元組的元素不能修改。元組使用小括弧,列表使用方括弧。
def main():
# 定義元組
t = ('駱昊', 38, True, '四川成都')
print(t)
# 獲取元組中的元素
print(t[0])
print(t[3])
# 遍歷元組中的值
for member in t:
print(member)
# 重新給元組賦值
# t[0] = '王大錘' # TypeError
# 變數t重新引用了新的元組原來的元組將被垃圾回收
t = ('王大錘', 20, True, '雲南昆明')
print(t)
# 將元組轉換成列表
person = list(t)
print(person)
# 列表是可以修改它的元素的
person[0] = '李小龍'
person[1] = 25
print(person)
# 將列表轉換成元組
fruits_list = ['apple', 'banana', 'orange']
fruits_tuple = tuple(fruits_list)
print(fruits_tuple)
if __name__ == '__main__':
main()這裡有一個非常值得探討的問題,我們已經有了列表這種數據結構,為什麼還需要元組這樣的類型呢?
- 元組中的元素是無法修改的,事實上我們在項目中尤其是多線程環境(後面會講到)中可能更喜歡使用的是那些不變對象(一方面因為對象狀態不能修改,所以可以避免由此引起的不必要的程式錯誤,簡單的說就是一個不變的對象要比可變的對象更加容易維護;另一方面因為沒有任何一個線程能夠修改不變對象的內部狀態,一個不變對象自動就是線程安全的,這樣就可以省掉處理同步化的開銷。一個不變對象可以方便的被共用訪問)。所以結論就是:如果不需要對元素進行添加、刪除、修改的時候,可以考慮使用元組,當然如果一個方法要返回多個值,使用元組也是不錯的選擇。
- 元組在創建時間和占用的空間上面都優於列表。
4.集合
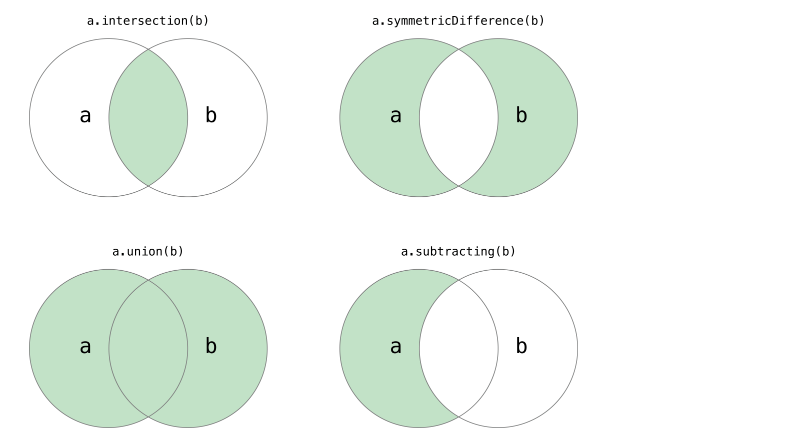
Python中的集合跟數學上的集合是一致的,不允許有重覆元素,而且可以進行交集、並集、差集等運算。
"""
使用集合
version:0.1
author:coke
"""
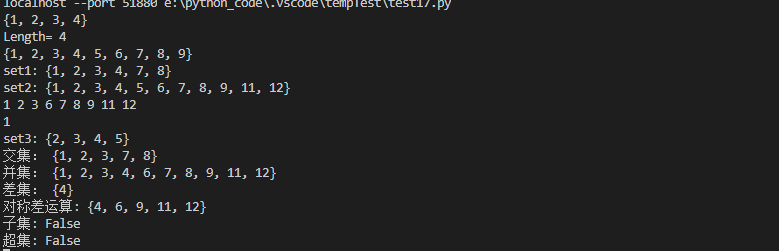
def main():
set1 = {1,2,3,3,2,4}
print(set1)
# len() 求集合的長度
print('Length=',len(set1))
set2 = set(range(1,10))
print(set2)
set1.add(7)
set1.add(8)
set2.update([11,12])
print("set1:",set1)
print("set2:",set2)
# 移除元素5
set2.discard(5)
# remove的元素 如果不存在會引發keyError
if 4 in set2:
set2.remove(4)
#遍歷集合容器
for ele in set2:
print(ele,end=" ")
print(" ")
#將元組轉換成集合
set3 = set((1,2,3,4,5))
print(set3.pop())
print("set3:",set3)
# 集合的交集、並集、差集、對稱差運算
print("交集:",set1 & set2)
print("並集:",set1 | set2)
print("差集:",set1 - set2)
print("對稱差運算:",set1 ^ set2)
#判斷子集和超集
print("子集:",set1 <= set2)
#print(set1.issuperset(set2))
print("超集:",set1 >= set2)
#print(set1.issubset(set2))
if __name__ == "__main__":
main()輸出結果
5. 字典
字典和列表一樣,也能夠存儲多個數據。字典的每個元素由2部分組成,鍵:值。例如 'name':'班長' ,'name'為鍵,'班長'為值
5.1 字典的增刪改查
1、添加元素
info = {'name':'班長', 'sex':'f', 'address':'地球亞洲中國北京'}
# print('id為:%d'%info['id'])#程式會終端運行,因為訪問了不存在的鍵
newId = input('請輸入新的學號:')
info['id'] = newId
print('添加之後的id為:',info['id'])
2、修改元素
info = {'name':'班長', 'id':100, 'sex':'f', 'address':'地球亞洲中國北京'}
newId = input('請輸入新的學號:')
info['id'] = int(newId)
print('修改之後的id為:',info['id'])
3、刪除元素
del刪除指定元素clear()清空整個字典
info = {'name':'班長', 'sex':'f', 'address':'地球亞洲中國北京'}
print("刪除前:",info)
del info['name']
print('刪除後:',info)
info.clear()
print("清空後:",info)
4、查找某個元素
字典在查詢某個元素時,若該字典沒有所查詢的元素會報錯,所以查詢前最好進行判斷
info = {'id':1,'name':'班長', 'sex':'f', 'address':'地球亞洲中國北京'}
print("查詢:",info)
print("查詢存在的元素:",info['id'])
#print("查詢不存在的元素:",info['age']) keyError
print("查詢不存在的元素:",info['age'] if 'age' in info else "元素不存在")
5.2 字典的常見操作
1、len():測量字典鍵值對的個數
dict = {"name":"Jack","age":11}
print(len(dict))
2、 keys():返回一個包含字典所有key的列表
dict = {"name":"Jack","age":11}
print(dict.keys())
3、values():返回一個包含字典所有value的列表
dict = {"name":"Jack","age":11}
print(dict.values())
4、items():返回一個包含所有(鍵,值)元組的列表
dict = {"name":"Jack","age":11}
print(dict.items)
5、字典遍歷
"""
字典測試
version:0.1
author:coke
"""
info = {"name":"coke","age":11,"height":"198"}
print("遍歷字典項--------------------第一種方式")
for item in info.items():
print(item)
print("遍歷字典項--------------------第二種方式")
for key,value in info.items():
print("%s:%s"%(key,value))

