
前提: 搭建好集群環境(zookeeper、hadoop、hbase)。 搭建方法這裡就不進行介紹了,網上有很多博客在介紹這些。 簡單需求: WordCount單詞計數,號稱Hadoop的HelloWorld。所以,我打算通過這個來初體驗一下Hadoop。需求如下: ①、計算文件中出現每個單詞的頻數 ...
====前提:
搭建好集群環境(zookeeper、hadoop、hbase)。
搭建方法這裡就不進行介紹了,網上有很多博客在介紹這些。
====簡單需求:
WordCount單詞計數,號稱Hadoop的HelloWorld。所以,我打算通過這個來初體驗一下Hadoop。需求如下:
①、計算文件中出現每個單詞的頻數
②、輸入結果按照字母順序進行排序

====Map過程:
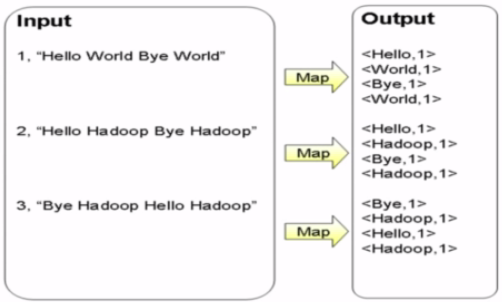
首先將文件進行切分成單詞。將所有單詞的項目都聚到一起。生成key-value的中間結果。
====Reduce過程
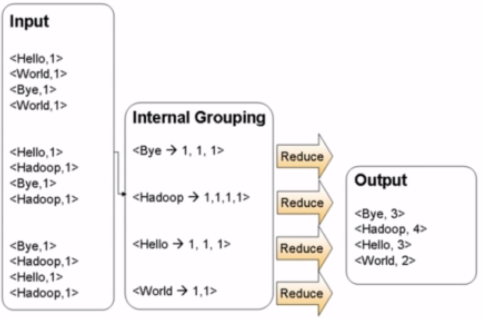
拿到之前Map的中間結果,進行合併(歸約)。
====源代碼
源代碼來自慕課網,由於我自己學習需要,放到了我的Github空間上了。
https://github.com/quchunhui/WordCount
====上傳Jar包
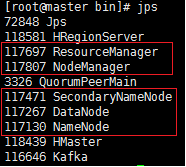
首先需要確認Linux集群運轉是否正常。使用jps命令查看。確保hadoop相關進程的存在。
需要註意一點,不同版本的Hadoop的jps結果可能不一樣。我在看慕課網的視頻的時候,
發現人家裡面還有TaskTracker和JobTracker呢,但是新版本的Hadoop就已經沒有。
並不是集群環境的問題。具體什麼是正確的,可以去查看官網的幫助文檔。
①、在Master端的jps結果
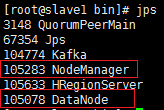
②、在Slave端的jps結果
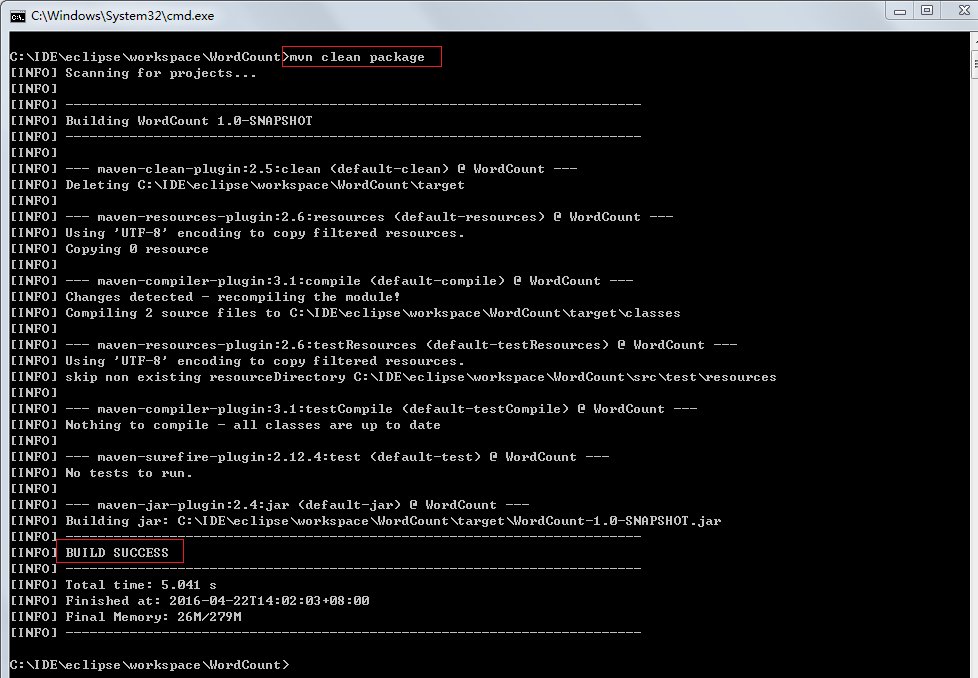
然後,將寫完的代碼達成jar包。由於我使用的是Mave環境,所以在Maven環境下使用mvn package進行打包即可。
====上傳文件至hdfs文件目錄
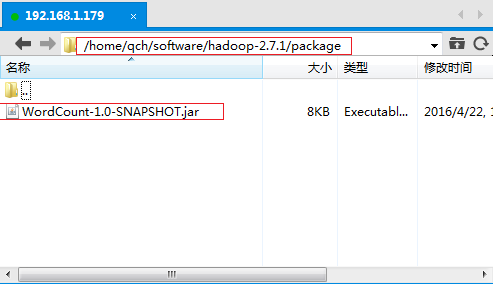
①、將上述步驟中生成的jar包上傳到Linux伺服器上。
我在HDOOP_HOME的根目錄下創建了一個專門用於存放jar包的文件夾package。將生成的jar包上傳到這裡
/home/qch/software/hadoop-2.7.1/package
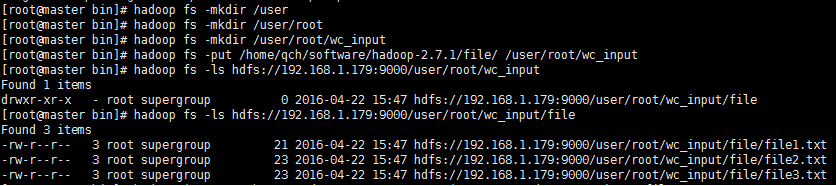
②、使用hadoop fs -put命令將數據源文件到hdfs文件目錄
註意,這裡是hdfs文件目錄,並非是Linux系統上的某個文件夾。如果目錄不存在,需要通過hadoop fs -mkdir命令自己手動去逐層創建。
我這裡將上述3個文件上傳到了hdfs文件目錄[/user/root/wc_input]上了。
====程式運行
①、通過【hadoop jar <jar> [mainClass] args…】命令來運行程式。
命令:hadoop jar ../package/WordCount-1.0-SNAPSHOT.jar test.WordCount wc_input/file wc_output
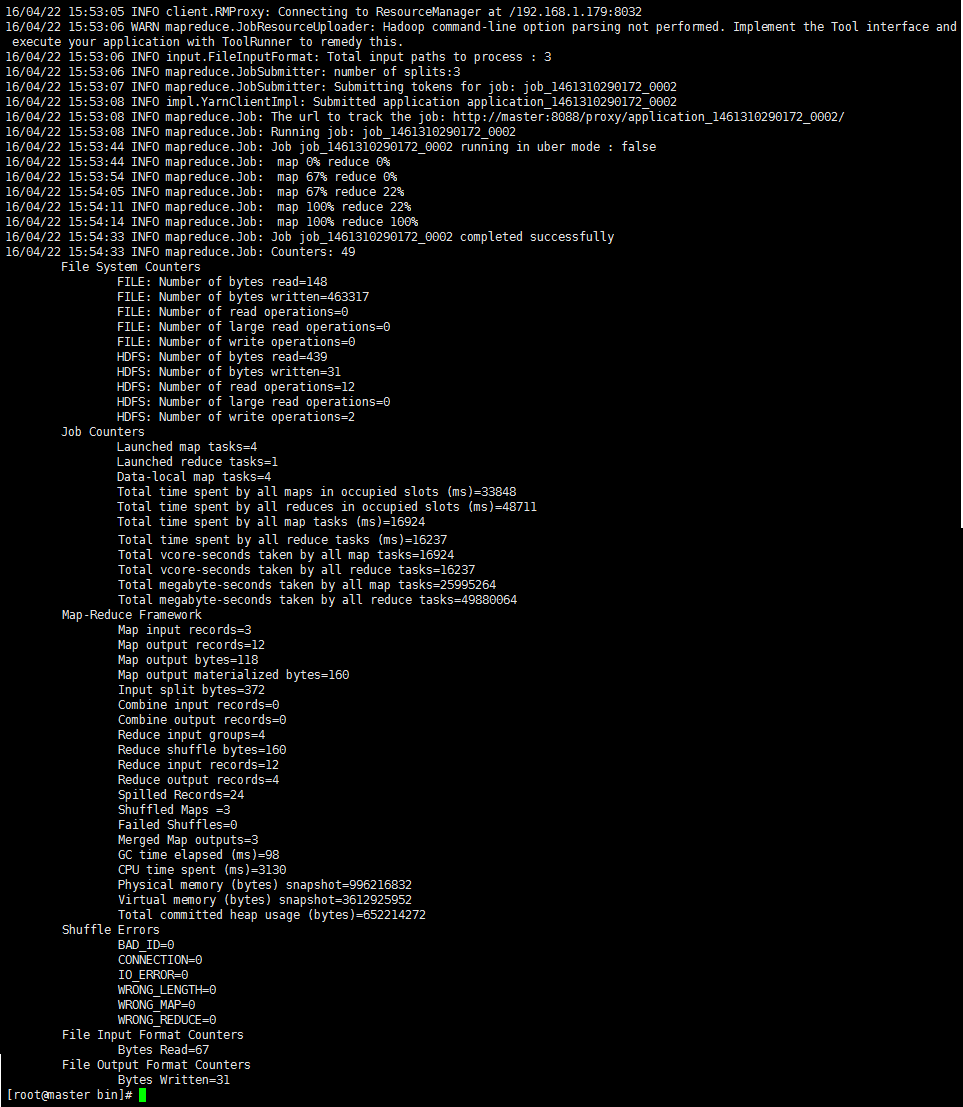
②、運行成功之後,可以通過命令來查看hdfs上的生成結果是否正確。
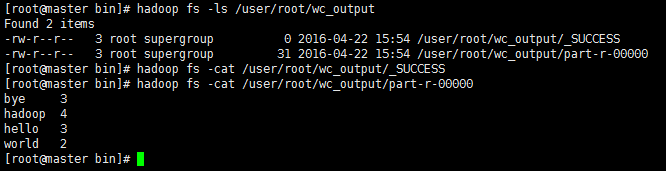
====總結:
我犯的最小白的錯誤就是,不知道需要將文件上傳到hdfs文件目錄下麵。希望以後加深對hdfs的瞭解。
這也就是我今天(2016/4/22。)的第一個mapreduce成果。
下一步需要真正去進行我的MapReduce工作了,需要考慮按照什麼規則進行Map和Reduce。這才是重中之重。
--END--

