
Python分散式爬蟲必學框架Scrapy打造搜索引擎 部分課程截圖: 點擊鏈接或搜索QQ號直接加群獲取其它資料: 鏈接:https://pan.baidu.com/s/1-wHr4dTAxfd51Mj9DxiJ4Q 提取碼:ik1n 免費分享,如若鏈接失效請加群 其它資源在群里,私聊管理員即可免費 ...
Python分散式爬蟲必學框架Scrapy打造搜索引擎
部分課程截圖:
點擊鏈接或搜索QQ號直接加群獲取其它資料:

鏈接: https://pan.baidu.com/s/1-wHr4dTAxfd51Mj9DxiJ4Q
https://pan.baidu.com/s/1-wHr4dTAxfd51Mj9DxiJ4Q
提取碼:ik1n
免費分享,如若鏈接失效請加群
其它資源在群里,私聊管理員即可免費領取;群——517432778,點擊加群,或掃描二維碼




-
第1章 課程介紹
介紹課程目標、通過課程能學習到的內容、和系統開發前需要具備的知識
- 1-1 python分散式爬蟲打造搜索引擎簡介試看
-
第2章 windows下搭建開發環境
介紹項目開發需要安裝的開發軟體、 python虛擬virtualenv和 virtualenvwrapper的安裝和使用、 最後介紹pycharm和navicat的簡單使用
- 2-1 pycharm的安裝和簡單使用
- 2-2 mysql和navicat的安裝和使用
- 2-3 windows和linux下安裝python2和python3
- 2-4 虛擬環境的安裝和配置
-
第3章 爬蟲基礎知識回顧
介紹爬蟲開發中需要用到的基礎知識包括爬蟲能做什麼,正則表達式,深度優先和廣度優先的演算法及實現、爬蟲url去重的策略、徹底弄清楚unicode和utf8編碼的區別和應用。
- 3-1 技術選型 爬蟲能做什麼
- 3-2 正則表達式-1
- 3-3 正則表達式-2
- 3-4 正則表達式-3
- 3-5 深度優先和廣度優先原理
- 3-6 url去重方法
- 3-7 徹底搞清楚unicode和utf8編碼
-
第4章 scrapy爬取知名技術文章網站
搭建scrapy的開發環境,本章介紹scrapy的常用命令以及工程目錄結構分析,本章中也會詳細的講解xpath和css選擇器的使用。然後通過scrapy提供的spider完成所有文章的爬取。然後詳細講解item以及item loader方式完成具體欄位的提取後使用scrapy提供的pipeline分別將數據保存到json文件以及mysql資料庫中。...
- 4-1 關於文章網站不能訪問的解決辦法(本章學習之前的註意事項)
- 4-2 scrapy安裝以及目錄結構介紹
- 4-3 pycharm 調試scrapy 執行流程
- 4-4 xpath的用法 - 1
- 4-5 xpath的用法 - 2
- 4-6 xpath的用法 - 3
- 4-7 css選擇器實現欄位解析 - 1
- 4-8 css選擇器實現欄位解析 - 2
- 4-9 編寫spider爬取jobbole的所有文章 - 1
- 4-10 編寫spider爬取jobbole的所有文章 - 2
- 4-11 items設計 - 1
- 4-12 items設計 - 2
- 4-13 items設計 - 3
- 4-14 數據表設計和保存item到json文件
- 4-15 通過pipeline保存數據到mysql - 1
- 4-16 通過pipeline保存數據到mysql - 2
- 4-17 scrapy item loader機制 - 1
- 4-18 scrapy item loader機制- 2
-
第5章 scrapy爬取知名問答網站
本章主要完成網站的問題和回答的提取。本章除了分析出問答網站的網路請求以外還會分別通過requests和scrapy的FormRequest兩種方式完成網站的模擬登錄, 本章詳細的分析了網站的網路請求並分別分析出了網站問題回答的api請求介面並將數據提取出來後保存到mysql中。...
- 5-1 session和cookie自動登錄機制試看
- 5-2 . selenium模擬登錄知乎 - 1new
- 5-3 . selenium模擬登錄知乎-2new
- 5-4 . selenium模擬登錄知乎-3new
- 5-5 . 知乎倒立文字識別 new
- 5-6 . selenium自動識別驗證碼完成模擬登錄-1new
- 5-7 . selenium自動識別驗證碼完成模擬登錄 - 2 new
- 5-8 requests模擬登陸知乎 - 1(可選觀看)
- 5-9 requests模擬登陸知乎 - 2(可選觀看)
- 5-10 requests模擬登陸知乎 - 3(可選觀看)
- 5-11 scrapy模擬知乎登錄(可選觀看)
- 5-12 知乎分析以及數據表設計1
- 5-13 知乎分析以及數據表設計 - 2
- 5-14 item loder方式提取question - 1
- 5-15 item loder方式提取question - 2
- 5-16 item loder方式提取question - 3
- 5-17 知乎spider爬蟲邏輯的實現以及answer的提取 - 1
- 5-18 知乎spider爬蟲邏輯的實現以及answer的提取 - 2
- 5-19 保存數據到mysql中 -1
- 5-20 保存數據到mysql中 -2
- 5-21 保存數據到mysql中 -3
-
第6章 通過CrawlSpider對招聘網站進行整站爬取
本章完成招聘網站職位的數據表結構設計,並通過link extractor和rule的形式並配置CrawlSpider完成招聘網站所有職位的爬取,本章也會從源碼的角度來分析CrawlSpider讓大家對CrawlSpider有深入的理解。
- 6-1 數據表結構設計
- 6-2 CrawlSpider源碼分析-新建CrawlSpider與settings配置
- 6-3 CrawlSpider源碼分析
- 6-4 Rule和LinkExtractor使用
- 6-5 拉勾網302之後的模擬登錄和cookie傳遞(網站需要登錄時學習本視頻教程)
- 6-6 item loader方式解析職位
- 6-7 職位數據入庫-1
- 6-8 職位信息入庫-2
-
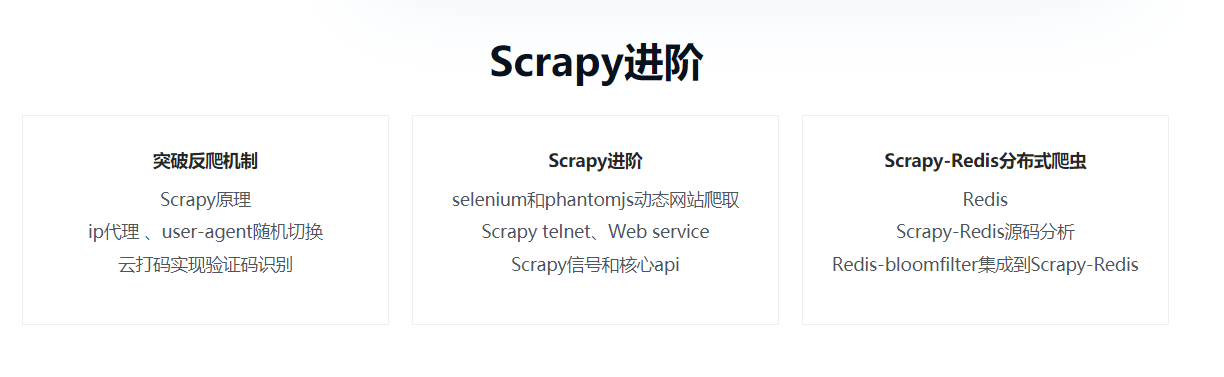
第7章 Scrapy突破反爬蟲的限制
本章會從爬蟲和反爬蟲的鬥爭過程開始講解,然後講解scrapy的原理,然後通過隨機切換user-agent和設置scrapy的ip代理的方式完成突破反爬蟲的各種限制。本章也會詳細介紹httpresponse和httprequest來詳細的分析scrapy的功能,最後會通過雲打碼平臺來完成線上驗證碼識別以及禁用cookie和訪問頻率來降低爬蟲被屏蔽的可能性。...
- 7-1 爬蟲和反爬的對抗過程以及策略試看
- 7-2 scrapy架構源碼分析
- 7-3 Requests和Response介紹
- 7-4 通過downloadmiddleware隨機更換user-agent-1
- 7-5 通過downloadmiddleware隨機更換user-agent - 2
- 7-6 scrapy實現ip代理池 - 1
- 7-7 scrapy實現ip代理池 - 2
- 7-8 scrapy實現ip代理池 - 3
- 7-9 雲打碼實現驗證碼識別
- 7-10 cookie禁用、自動限速、自定義spider的settings
-
第8章 scrapy進階開發
本章將講解scrapy的更多高級特性,這些高級特性包括通過selenium和phantomjs實現動態網站數據的爬取以及將這二者集成到scrapy中、scrapy信號、自定義中間件、暫停和啟動scrapy爬蟲、scrapy的核心api、scrapy的telnet、scrapy的web service和scrapy的log配置和email發送等。 這些特性使得我們不僅只是可以通過scrapy來完成...
- 8-1 selenium動態網頁請求與模擬登錄知乎
- 8-2 selenium模擬登錄微博, 模擬滑鼠下拉
- 8-3 chromedriver不載入圖片、phantomjs獲取動態網頁
- 8-4 selenium集成到scrapy中
- 8-5 其餘動態網頁獲取技術介紹-chrome無界面運行、scrapy-splash、selenium-grid, splinter
- 8-6 scrapy的暫停與重啟
- 8-7 scrapy url去重原理
- 8-8 scrapy telnet服務
- 8-9 spider middleware 詳解
- 8-10 scrapy的數據收集
- 8-11 scrapy信號詳解
- 8-12 scrapy擴展開發
-
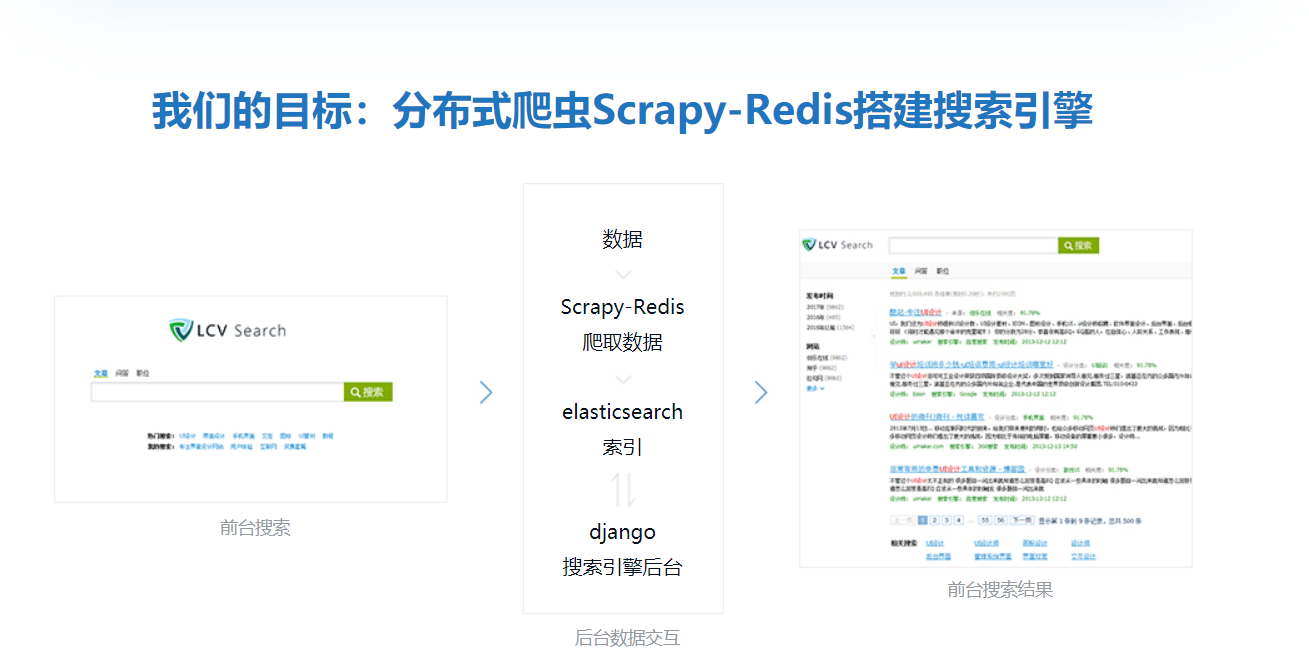
第9章 scrapy-redis分散式爬蟲
Scrapy-redis分散式爬蟲的使用以及scrapy-redis的分散式爬蟲的源碼分析, 讓大家可以根據自己的需求來修改源碼以滿足自己的需求。最後也會講解如何將bloomfilter集成到scrapy-redis中。
- 9-1 分散式爬蟲要點
- 9-2 redis基礎知識 - 1
- 9-3 redis基礎知識 - 2
- 9-4 scrapy-redis編寫分散式爬蟲代碼
- 9-5 scrapy源碼解析-connection.py、defaults.py-
- 9-6 scrapy-redis源碼剖析-dupefilter.py-
- 9-7 scrapy-redis源碼剖析- pipelines.py、 queue.py-
- 9-8 scrapy-redis源碼分析- scheduler.py、spider.py-
- 9-9 集成bloomfilter到scrapy-redis中
-
第10章 elasticsearch搜索引擎的使用
本章將講解elasticsearch的安裝和使用,將講解elasticsearch的基本概念的介紹以及api的使用。本章也會講解搜索引擎的原理並講解elasticsearch-dsl的使用,最後講解如何通過scrapy的pipeline將數據保存到elasticsearch中。
- 10-1 elasticsearch介紹
- 10-2 elasticsearch安裝
- 10-3 elasticsearch-head插件以及kibana的安裝
- 10-4 elasticsearch的基本概念
- 10-5 倒排索引
- 10-6 elasticsearch 基本的索引和文檔CRUD操作
- 10-7 elasticsearch的mget和bulk批量操作
- 10-8 elasticsearch的mapping映射管理
- 10-9 elasticsearch的簡單查詢 - 1
- 10-10 elasticsearch的簡單查詢 - 2
- 10-11 elasticsearch的bool組合查詢
- 10-12 scrapy寫入數據到elasticsearch中 - 1
- 10-13 scrapy寫入數據到elasticsearch中 - 2
-
第11章 django搭建搜索網站
本章講解如何通過django快速搭建搜索網站, 本章也會講解如何完成django與elasticsearch的搜索查詢交互。
- 11-1 es完成搜索建議-搜索建議欄位保存 - 1
- 11-2 es完成搜索建議-搜索建議欄位保存 - 2
- 11-3 django實現elasticsearch的搜索建議 - 1
- 11-4 django實現elasticsearch的搜索建議 - 2
- 11-5 django實現elasticsearch的搜索功能 -1
- 11-6 django實現elasticsearch的搜索功能 -2
- 11-7 django實現搜索結果分頁
- 11-8 搜索記錄、熱門搜索功能實現 - 1
- 11-9 搜索記錄、熱門搜索功能實現 - 2
-
第12章 scrapyd部署scrapy爬蟲
本章主要通過scrapyd完成對scrapy爬蟲的線上部署。
- 12-1 scrapyd部署scrapy項目


