
1. 在主機Macbook上設置HOST 前文書已經把虛擬機的靜態IP地址設置好,以後可以通過ip地址登錄了。不過為了方便,還是設置一下,首先在Mac下修改hosts文件,這樣在ssh時就不用輸入ip地址了。 sudo vim /etc/hosts 或者 sudo vim /private/etc/ ...
1. 在主機Macbook上設置HOST
前文書已經把虛擬機的靜態IP地址設置好,以後可以通過ip地址登錄了。不過為了方便,還是設置一下,首先在Mac下修改hosts文件,這樣在ssh時就不用輸入ip地址了。
sudo vim /etc/hosts
或者
sudo vim /private/etc/hosts
這兩個文件其實是一個,是通過link做的鏈接。註意要加上sudo, 以管理員運行,否則不能存檔。
##
# Host Database
#
# localhost is used to configure the loopback interface
# when the system is booting. Do not change this entry.
##
127.0.0.1 localhost
255.255.255.255 broadcasthost
::1 localhost
50.116.33.29 sublime.wbond.net
127.0.0.1 windows10.microdone.cn
# Added by Docker Desktop
# To allow the same kube context to work on the host and the container:
127.0.0.1 kubernetes.docker.internal192.168.56.100 hadoop100
192.168.56.101 hadoop101
192.168.56.102 hadoop102
192.168.56.103 hadoop103
192.168.56.104 hadoop104
# End of section
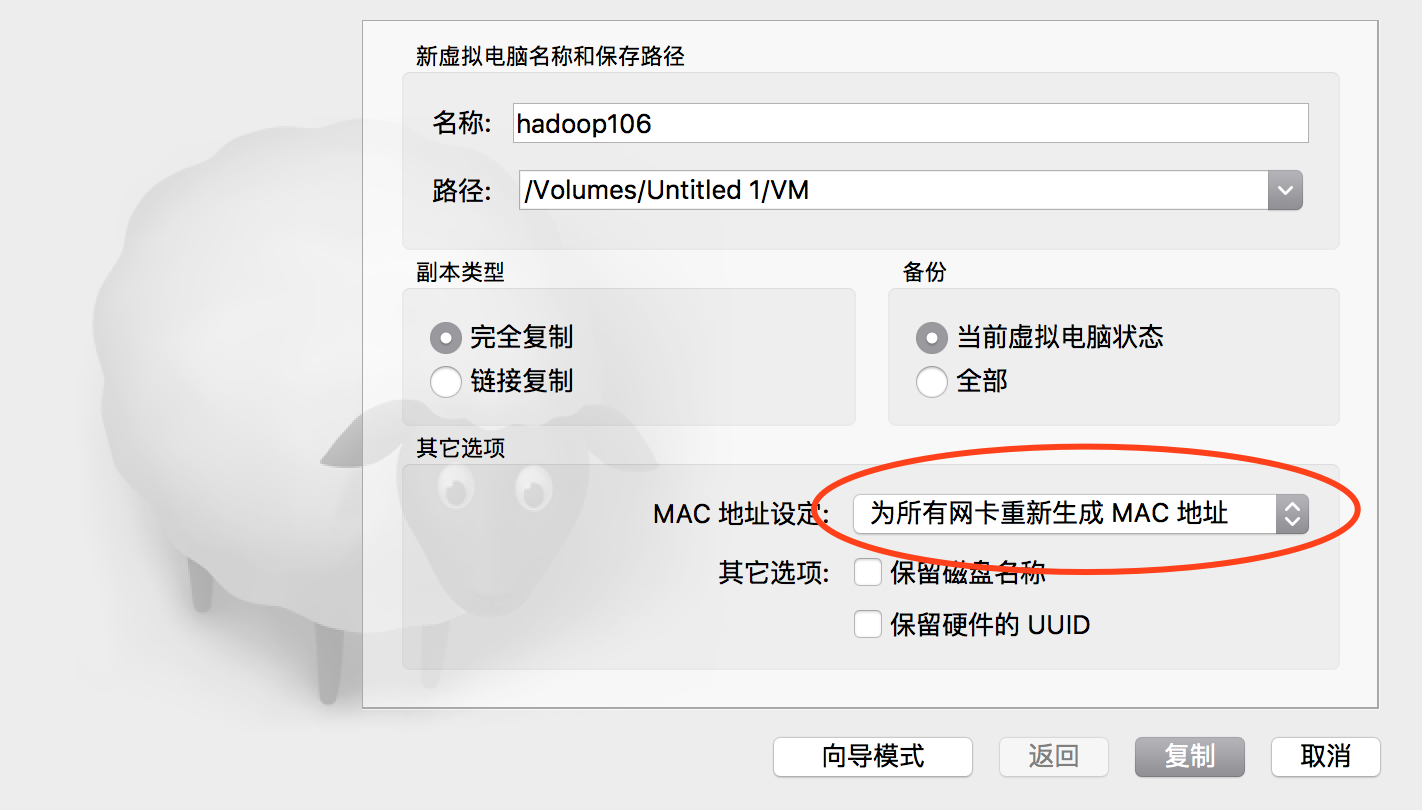
2. 複製虛擬機
然後我們需要由上次配好的這一臺虛擬機,複製出來多台,以便形成一個集群。首先關閉虛擬,在上面點右鍵,選複製,出現如下對話框,我選擇把所有網卡都重新生成Mac地址,以便模擬完全不同的計算器環境。
3. 修改每一臺的HOST, IP地址
複製完畢後,記得登錄到虛擬機,按照前面提到的方法修改一下靜態IP地址,免得IP地址衝突。
vi /etc/sysconfig/network-scripts/ifcfg-enp0s3
vi /etc/sysconfig/network-scripts/ifcfg-enp0s8
另外,最好也在每台Linux 虛擬機里也設置一下HOSTNAME,以便這些虛擬機之前相互通訊時也可以使用hostname。需要依次把幾台機器的hostname都設置好。
[root@hadoop101 ~]# hostnamectl set-hostname hadoop107
[root@hadoop101 ~]# hostname
hadoop107
4. xcall讓伺服器集群同時運行命令
因為我們同時有好幾台機器,如果挨個挨個的登錄上去操作,難免麻煩,可以寫個shell腳本,以後從其中一臺發起命令,讓所有機器都執行就方便多了。下麵是個例子。 我有hadopp100,hadopp101、hadopp102、hadopp103、hadopp104這個五台虛擬機。我希望以hadopp100為堡壘,統一控制所有其他的機器。 在/user/local/bin 下創建一個xcall的文件,內容如下:
touch /user/local/bin/xcall
chmod +x /user/local/bin/xcall
vi /user/local/bin/xcall
#!/bin/bash
pcount=$#
if((pcount==0));then
echo no args;
exit;
fiecho ---------running at localhost--------
$@
for((host=101;host<=104;host++));do
echo ---------running at hadoop$host-------
ssh hadoop$host $@
done
~
比如我用這個xcall腳本在所有機器上調用pwd名稱,查看當前目錄,會依次提示輸入密碼後執行。
[root@hadoop100 ~]# xcall pwd
---------running at localhost--------
/root
---------running at hadoop101-------
root@hadoop101's password:
/root
---------running at hadoop102-------
root@hadoop102's password:
/root
---------running at hadoop103-------
root@hadoop103's password:
/root
---------running at hadoop104-------
root@hadoop104's password:
/root
[root@hadoop100 ~]#
5. scp與rsync
然後我們說一下 scp這個工具。 scp可以在linux間遠程拷貝數據。如果要拷貝整個目錄,加 -r 就可以了。
[root@hadoop100 ~]# ls
anaconda-ks.cfg
[root@hadoop100 ~]# scp anaconda-ks.cfg hadoop104:/root/
root@hadoop104's password:
anaconda-ks.cfg 100% 1233 61.1KB/s 00:00
[root@hadoop100 ~]#
另外還可以用rsync, scp是不管目標機上情況如何,都要拷貝以便。 rsync是先對比一下,有變化的再拷貝。如果要遠程拷貝的東西比較大,用rsync更快一些。 不如rsync在centOS上沒有預設安裝,需要首先安裝一下。在之前的文章中,我們的虛擬機已經可以聯網了,所以線上安裝就可以了。
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
命令 命令參數 要拷貝的文件路徑/名稱 目的用戶@主機:目的路徑
選項
-r 遞歸
-v 顯示覆制過程
-l 拷貝符號連接
[root@hadoop100 ~]# xcall sudo yum install -y rsync
比如,把hadoop100機器上的java sdk同步到102上去:
[root@hadoop100 /]# rsync -r /opt/modules/jdk1.8.0_121/ hadoop102:/opt/modules/jdk1.8.0_121/
然後我們需要一個能把內容自動同步到集群內所有機器的xsync命令;
#!/bin/bash
#1 獲取輸入參數的個數,如果沒有參數則退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi#2 獲取文件名稱
p1=$1
fname=`basename $p1`
echo fname=$fname#3 獲取上級目前的絕對路徑
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir# 獲取當前用戶名
user=`whoami`#5 迴圈
for((host=100;host<105;host++));do
#echo $pdir/$fname $user@hadoop$host:$pdir
echo ---------hadoop$host
rsync -rvl $pdir/$fname $user@hadoop$host:$pdir
done
6. SSH免密登錄設置
在執行上面的命令時,發現每次都要輸入密碼,這個也挺煩的,而且後期hadoop集群在啟動時也會需要各機器之前相互授權,如果每次都輸入密碼,確實太麻煩了,所以需要設置一下ssh免密登錄。
首先用ssh-keygen -t rsa 生成秘鑰對,過程中都按回車介紹預設值即可。然後用ssh-copy-id 其他主機,把公鑰發送給要登錄的目標主機,在這個過程中需要輸入密碼以便授權。成功後就可以按照提示用ssh 遠程登錄到其他主機了,並不要求輸入密碼。
[root@hadoop104 ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:X0I1F6IntPPIJgVHXjmSZ6hmaeWifXa7TmJR9I9YCo8 root@hadoop104
The key's randomart image is:
+---[RSA 2048]----+
| ..+o*.o. |
| ==*== |
| =X+o.o |
| B+.@ + o |
| *S.E * . .|
| . .+o+. |
| o+... |
| . o. |
| .o. |
+----[SHA256]-----+
[root@hadoop104 ~]# ssh-copy-id hadoop100
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@hadoop100's password:Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'hadoop100'"
and check to make sure that only the key(s) you wanted were added.[root@hadoop104 ~]# 當前在hadoop04下
[root@hadoop104 ~]# ssh hadoop100
Last failed login: Mon Sep 16 13:15:35 CST 2019 from hadoop103 on ssh:notty
There were 5 failed login attempts since the last successful login.
Last login: Mon Sep 16 09:37:51 2019 from 192.168.56.1
[root@hadoop100 ~]# 已經在目標主機下了
按照上面的方法,把所有集群之間都設置好免密登錄,也就是每台機器上都ssh-keygen生成一個秘鑰對,然後ssh-copy-id到其他幾台虛擬機。
好了,到現在基本的工具和集群環境搭建起來了,後面就可以開始hadoop的學習了。

