
原地址 https://www.cnblogs.com/devilwind/p/6902037.html 今天在新環境里部署tomcat, 剛開始啟動很快,關閉之後再啟動,卻發現啟動日誌列印到 00:25:14.144 [localhost-startStop-1] INFO o.s.web.con ...
原地址 https://www.cnblogs.com/devilwind/p/6902037.html
今天在新環境里部署tomcat, 剛開始啟動很快,關閉之後再啟動,卻發現啟動日誌列印到
00:25:14.144 [localhost-startStop-1] INFO o.s.web.context.ContextLoader - Root WebApplicationContext: initialization completed in 6287 ms
一直hold著,tomcat程式也無法訪問,以為是程式哪裡配置錯了,找了半天,甚至把spring的配置載入完全去掉才能啟動,why, 程式在開發環境可是刷刷刷就跑起來的
後來一直沒管這程式過了幾分鐘去看日誌,發現tomcat 程式才啟動完畢,why?原來不是卡住,而是慢
用jstack 觀察一下啟動線程, 發現 C2 CompilerThread 占用cpu很高, 同時 org.apache.catalina.util.SessionIdGeneratorBase.createSecureRandom這裡讀文件也產生阻塞,占用CPU也很高, 百度一下,以下轉載其他人的兩篇文章
發佈或重啟線上服務時抖動問題解決方案 http://www.cnblogs.com/LBSer/p/3703967.html
一、問題描述
在發佈或重啟某線上某服務時(jetty8作為伺服器),常常發現有些機器的load會飆到非常高(高達70),並持續較長一段時間(5分鐘)後回落(圖1),與此同時響應時間曲線(圖2)也與load曲線一致。註:load飆高的初始時刻是應用服務埠打開,流量打入時(load具體指什麼可參考http://www.cnblogs.com/amsun/p/3155246.html)。
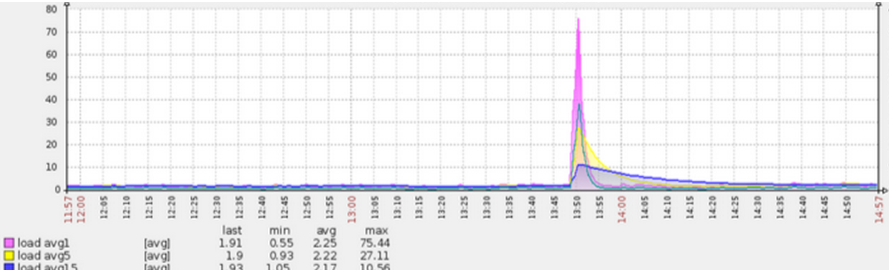
圖1 發佈時候load飆高
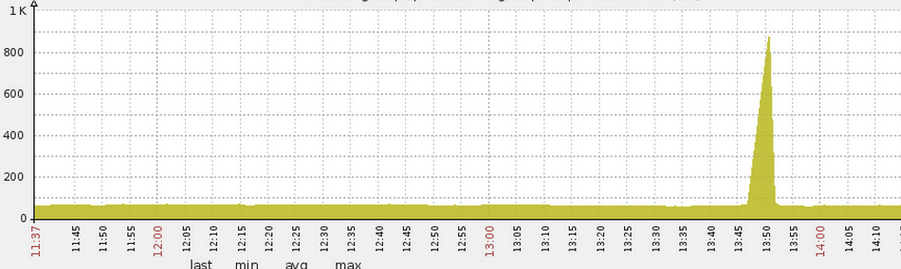
圖2 發佈時候響應時間飆高
二、問題排查方法
發佈時對資源使用情況進行監控。
1)通過top -H -p 查找cpu使用率較高的線程,發現2129和2130這兩個線程cpu使用較高。

圖3 查找cpu使用率較高的線程
2)通過jstack列印棧信息,並將線程號2129和2130轉換成16進位(printf "%x\n" 2129),分別為851和852,發現這兩個線程是編譯線程(表1)。此外當這兩個線程cpu使用率降低後load以及響應時間也馬上恢復了正常,時間點非常吻合。
表1 cpu使用率較高的兩個線程詳細信息
"C2 CompilerThread1" daemon prio=10 tid=0x00007fce48125800 nid=0x852 waiting on condition [0x0000000000000000] java.lang.Thread.State: RUNNABLE Locked ownable synchronizers: - None "C2 CompilerThread0" daemon prio=10 tid=0x00007fce48123000 nid=0x851 waiting on condition [0x0000000000000000] java.lang.Thread.State: RUNNABLE Locked ownable synchronizers: - None
三、現象解釋
C2 CompilerThread線程項目啟動初期cpu使用率那麼高,它在乾什麼呢?
Java程式在啟動的時候所有代碼的執行都處於解釋執行模式,只有在運行了一段時間後,根據代碼方法執行的次數,或代碼里迴圈的執行次數等達到一定的閾值才會編譯成機器碼,編譯成機器碼後執行效率會得到大幅提升,而隨著執行時間進一步拉長,JVM的各種更高級的編譯優化手段就會逐漸加上,例如if條件的執行狀況,逃逸分析等。這裡的C2 CompilerThread線程乾的就是編譯優化的活。
現在貌似可以解釋之前的現象了。
在程式剛啟動的時候,java還處於解釋執行模式,因此服務效率很低,響應時間緩慢,處理得慢了,load自然也就高了。而當流量持續不斷導入時,我們代碼的很多方法執行次數不斷增多,此時C2 CompilerThread線程不斷收集優化信息,並且開始將一些熱點代碼優化編譯成本地機器碼,因此該線程的cpu使用率增高。而當C2 CompilerThread線程完成初始編譯優化過程後,C2 CompilerThread線程的cpu使用率開始下降,與此同時優化後服務的性能大幅提升,服務響應時間也大大縮短,load也下降。
現在的癥結在於編譯優化過程持續時間較長,引起抖動。如何降低編譯優化的持續時間呢?
四、解決思路
1)預熱
如果在服務接受線上請求之前提前完成編譯優化過程,那麼將能避免此種抖動情況。一般的做法是預熱,有兩種方法:
a)程式主動預熱:在啟動完成後,程式主動的訪問熱點的代碼,確保主要的熱點代碼已被編譯成機器碼後再放入流量,可通過-XX:+PrintCompilation來確認。
b)複製流量預熱:通過tcpcopy軟體拷貝一份線上nginx的流量進行預熱,完成之後再導入線上流量。
2)啟動多個線程進行編譯優化
如果能加快編譯優化速度,那也能降低解釋執行階段導致的抖動時間。因此可以多拿幾個線程來做編譯,加快達到高峰性能的速度。
可以使用-XX:CICompilerCount參數來設置編譯線程數目,這個值預設是2(之前在棧里看到有兩個編譯線程),我們可以加到4。
3)採用多層編譯
編譯方式有三種:1)Client模式;2)Server模式;3)Tiered模式。我們服務預設是Server模式。
Server模式是採用c2高級編譯的,會比較耗時且要運行一段時間才會觸發編譯。 Server模式的優點是編譯後程式效率較高;
Client模式比較輕量也比較快觸發(比Server模式觸發快),編譯優化後程式效率不如Server模式;
Tiered模式是Client模式和Server模式的折中,一開始會啟用Client模式,可以在啟動後更快的讓部分代碼先進入編譯優化階段,之後會啟動Server模式,達到程式效率最大優化的目的。
Oracle JDK 7里的HotSpot VM已經開始有比較好的Tiered編譯(tiered compilation)支持,可以設置參數-XX:+TieredCompilation來啟動Tiered模式,java 8預設就是Tiered模式。
圖4是到http://www.javaworld.com/article/2078635/enterprise-middleware/jvm-performance-optimization--part-2--compilers.html截取的不同編譯方式的性能比較圖,橫坐標是時間,縱坐標是性能。可以看出Tired模式開始階段性能與C1相當,當到達某一時刻後性能與C2相當。

圖4 不同編譯模式的性能比較
五、結果分析
簡單起見採用方案2和方案3來進行優化。
採用方案2和3之後進行了多次發佈,發佈時除個別機器load達到10之外,基本沒有過高現象(在2~4範圍內),並且短時間(2分鐘)內,load都會降到較合理水平(2左右),較發佈時的load來看,比優化前要好很多。
方案2和方案3只是降低了抖動持續的時間以及抖動強度,並不能完全避免抖動。真正能避免抖動的方案應該是方案1,通過預熱的方式實現平滑發佈或重啟
##########################################################################################################
tomcat啟動時SessionIdGeneratorBase.createSecureRandom耗時5分鐘的問題 http://www.cnblogs.com/chyg/p/6844737.html
通常情況下,tomcat啟動只要2~3秒鐘,突然有一天,tomcat啟動非常慢,要花5~6分鐘,查了很久,終於在這篇文章找到瞭解決方案,博主牛人啊。
原文參見:http://blog.csdn.net/chszs/article/details/49494701
Tomcat 8啟動很慢,且日誌上無任何錯誤,在日誌中查看到如下信息:
Log4j:[2015-10-29 15:47:11] INFO ReadProperty:172 - Loading properties file from class path resource [resources/jdbc.properties] Log4j:[2015-10-29 15:47:11] INFO ReadProperty:172 - Loading properties file from class path resource [resources/common.properties] 29-Oct-2015 15:52:53.587 INFO [localhost-startStop-1] org.apache.catalina.util.SessionIdGeneratorBase.createSecureRandom Creation of SecureRandom instance for session ID generation using [SHA1PRNG] took [342,445] milliseconds.
原因
Tomcat 7/8都使用org.apache.catalina.util.SessionIdGeneratorBase.createSecureRandom類產生安全隨機類SecureRandom的實例作為會話ID,這裡花去了342秒,也即接近6分鐘。
SHA1PRNG演算法是基於SHA-1演算法實現且保密性較強的偽隨機數生成器。
在SHA1PRNG中,有一個種子產生器,它根據配置執行各種操作。
1)如果Java.security.egd 屬性或securerandom.source屬性指定的是”file:/dev/random”或”file:/dev/urandom”,那麼JVM 會使用本地種子產生器NativeSeedGenerator,它會調用super()方法,即調用 SeedGenerator.URLSeedGenerator(/dev/random)方法進行初始化。
2)如果java.security.egd屬性或securerandom.source屬性指定的是其它已存在的URL,那麼會調用SeedGenerator.URLSeedGenerator(url)方法進行初始化。
這就是為什麼我們設置值為”file:///dev/urandom”或者值為”file:/./dev/random”都會起作用的原因。
在這個實現中,產生器會評估熵池(entropy pool)中的雜訊數量。隨機數是從熵池中進行創建的。當讀操作時,/dev/random設備會只返回熵池中雜訊的隨機位元組。/dev/random非 常適合那些需要非常高質量隨機性的場景,比如一次性的支付或生成密鑰的場景。
當熵池為空時,來自/dev/random的讀操作將被阻塞,直到熵池收集到足夠的環境雜訊數據。這麼做的目的是成為一個密碼安全的偽隨機數發生器,熵池要有儘可能大的輸出。對於生成高質量的加密密鑰或者是需要長期保護的場景,一定要這麼做。
那麼什麼是環境雜訊?
隨機數產生器會手機來自設備驅動器和其它源的環境雜訊數據,並放入熵池中。產生器會評估熵池中的雜訊數據的數量。當熵池為空時,這個雜訊數據的收集是比較花時間的。這就意味著,Tomcat在生產環境中使用熵池時,會被阻塞較長的時間。
解決
有兩種解決辦法:
1)在Tomcat環境中解決
可以通過配置JRE使用非阻塞的Entropy Source。
在catalina.sh中加入這麼一行:-Djava.security.egd=file:/dev/./urandom 即可。
if [[ "$JAVA_OPTS" != *-Djava.security.egd=* ]]; then JAVA_OPTS="$JAVA_OPTS -Djava.security.egd=file:/dev/./urandom" fi
加入後再啟動Tomcat,整個啟動耗時下降到Server startup in 2912 ms。
2)在JVM環境中解決
打開$JAVA_PATH/jre/lib/security/java.security這個文件,找到下麵的內容:
securerandom.source=file:/dev/urandom
替換成
securerandom.source=file:/dev/./urandom
