
1.初識 1.資料庫 1. 什麼角色: 用戶名密碼 商品價格等信息 對數據的處理更便捷 2. web程式 資料庫管理員專門管理 是一個開 3. 資料庫的縮寫 db 4. DBMS 資料庫管理系統 5. mysql RDBMS 關係型資料庫管理系統 6. 解決了: 1. 文件操作的效率和便捷問題 2. ...
1.初識
1.資料庫
- 什麼角色: 用戶名密碼 商品價格等信息 對數據的處理更便捷
- web程式 資料庫管理員專門管理
MySQL是一個開 - 資料庫的縮寫 db
- DBMS 資料庫管理系統
- mysql RDBMS 關係型資料庫管理系統
- 解決了:
- 文件操作的效率和便捷問題
- 多個服務同時使用數據的一致性問題
- 安全和並法問題
2.資料庫分類
- 關係型資料庫
- 慢 通過一個信息其他的信息,賬號密碼
- MySQL(免費裡面最好用) Oracle(收費 但最好)[同一家公司]
- sqlserver(微軟旗下)
- sqllite(輕量級 很少用) accesse(小金融公司)
- 非關係型資料庫
- 快 缺點是關聯性很不搶
- redis最好 MongoDB(輕量級 直接用)
- memcache(以前貨 記憶體級別)
- MySQL資料庫管理系統 DBMS
- 以後用到的資料庫
- 用的最多是5.6 5.7坑很多
3.卸載,安裝
卸載
在裡面找MySQL 環境變數 找到之後先停止 在cmd裡面
自帶客戶端MySQL.exe 第三方Navicat好用 但是先不用
停止服務 刪除服務 把安裝軟體也刪除(文件夾) 刪除環境變數(先找到)
最後重啟 是清除註冊表(百度刪除方法)
net stop mysql 停止mysql服務 mysqld remove 刪除服務 把安裝軟體也刪掉 刪除環境變數 清除註冊表/重啟電腦
安裝
- 路徑>>>路徑不能有中文 路徑不能有特殊字元 \t \......
- 修改配置文件>>>編碼utf-8 所有配置項後面不能有特殊符號 修改兩個路徑basedir datadir
- 檢測文件的擴展名設置>>>不要隱藏 禁止隱藏
- 配置環境變數>>> 在path中添加個路徑 bin的路徑
- 以管理員的身份重新打開一個cmd>>>mysqld install 安裝成功
- 啟動mysql>>>net start mysql 啟動mysql server
- 在cmd啟動mysql 客戶端>>>mysql>>>客戶端和本地的mysql server相連
4.用戶操作和登錄
- mysql server端
- net start mysql 啟動一個叫做mysql的服務
- net stop mysql 停止一個服務
- net start mysql 啟動一個叫做mysql的服務
- mysql 啟動客戶端,客戶端會自動的連接本地的3306埠
- mysql -uroot 表示要用root用戶登陸>>>預設密碼是空==root最高許可權==
- set password = password('123'); 設置密碼
- mysql -uroot -p 回車>>>Enter password :123 使用密碼登陸
- 登陸成功mysql -uroot -p123 回車 直接登陸成功
- 創建賬號
- 使用公司的資料庫 管理員會創建一個賬號給你用>>你的資料庫 借給別人用也可以創建一個賬號
- 創建:>>>mysql>create user 'eva'@'192.168.13.%' identified by '123';
- 遠程登陸>>>mysql> -ueva -p123 -h192.168.13.254
- 查看某個用戶的許可權>>>mysql> show grants for 'eva'@'192.168.10.%';
- 創建賬號並授權>>>mysql> grant all on *.* to 'eva'@'%' identified by '123' (all是最高許可權)
- 授權>>>mysql> flush privileges; # 刷新使授權立即生效
- ==強行離職 補貼N+1工資 風險與機遇並存==
2.MySQL的庫.表的詳細操作
1.庫操作
- 增:create database db1 charset utf8;
- 增:create database db1; (可以不寫utf8)
- 查:show databases;
- 查:show create database 庫名;(查看庫的詳細創建語句)
- 改:alter database db1 charset latin1;
- 刪除: drop database db1;
- 切換:use 庫名;
2.表操作
1.儲存引擎
數據的存儲方式 -- 存儲引擎engines 使用不同的存儲引擎,數據是以不同的方式存儲的
創建表設置儲存引擎:
show create table staff; create table myisam_t (id int,name char(18)) engine=myisam; create table memory_t (id int,name char(18)) engine=memory;show engines; 查看存儲引擎
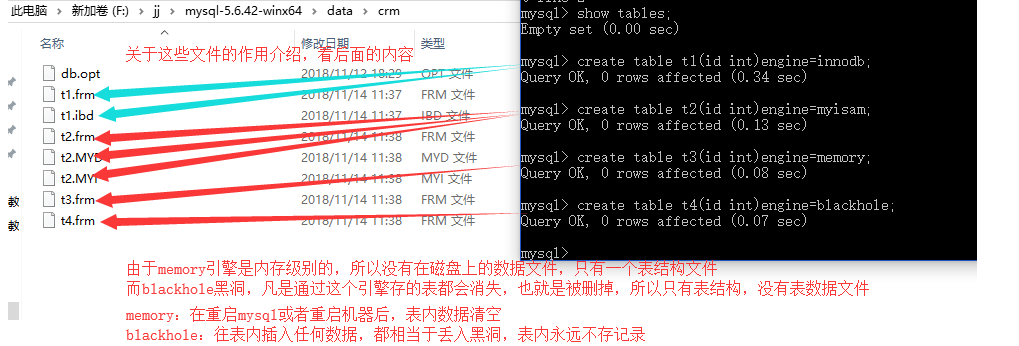

innodb 2個文件 ==事務==
- mysql5.6以上 預設的存儲方式
- transaction 事務 保證數據安全 數據的完整性而設置的概念
- row-level locking 行級鎖
- table-level locking 表級鎖
- foreign keys 外鍵約束
- 樹tree - 加速查詢 (樹形結構(數據+樹) + 表結構)

myisam 3個文件
- mysql5.5以下 預設的存儲方式
- table-level locking 表級鎖
- 樹tree - 加速查詢 (樹形結構 + 數據 + 表結構)

常用存儲引擎及使用場景
- ==InnoDB==>>>用於事務處理應用程式,支持外鍵和行級鎖。如果應用對事物的完整性有比較高的要求,在併發條件下要求數據的一致性,數據操作除了插入和查詢之外,還包括很多更新和刪除操作,那麼InnoDB存儲引擎是比較合適的。InnoDB除了有效的降低由刪除和更新導致的鎖定,還可以確保事務的完整提交和回滾,對於類似計費系統或者財務系統等對數據準確要求性比較高的系統都是合適的選擇。
- ==MyISAM==>>>如果應用是以讀操作和插入操作為主,只有很少的更新和刪除操作,並且對事務的完整性、併發性要求不高,那麼可以選擇這個存儲引擎。
- ==Memory==>>>將所有的數據保存在記憶體中,在需要快速定位記錄和其他類似數據的環境下,可以提供極快的訪問。Memory的缺陷是對錶的大小有限制,雖然資料庫因為異常終止的話數據可以正常恢復,但是一旦資料庫關閉,存儲在記憶體中的數據都會丟失。
流程關係

2.先切換到文件夾下:==use 庫名==
- 增:create table 表名(id int,name char);
- 查:show tables;
- 查:show create table 表名;(表的詳細信息
- )
- 改:
- alter table 表名 rename 新名字; 改表名
- alter table t1 modify name char(3); 修改類型
- alter table t1 change name name1 char(2); 修改名字和類型
- 刪:drop table 表名;
- 清空表操作:
- delete from t1; #如果有自增id,新增的數據,仍然是以刪除前的最後一樣作為起始。
- truncate table t1;數據量大,刪除速度比上一條快,且直接從零開始
3.MySQL的基礎數據類型
介紹
存儲引擎決定了表的類型,而表記憶體放的數據也要有不同的類型,每種數據類型都有自己的寬度,但寬度是可選的詳細參考
mysql常用數據類型概覽
#1. 數字: 整型:tinyint int bigint 小數: float :在位數比較短的情況下不精準 double :在位數比較長的情況下不精準 0.000001230123123123 存成:0.000001230000 decimal:(如果用小數,則用推薦使用decimal) 精準 內部原理是以字元串形式去存 #2. 字元串: char(10):簡單粗暴,浪費空間,存取速度快 root存成root000000 varchar:精準,節省空間,存取速度慢 sql優化:創建表時,定長的類型往前放,變長的往後放 比如性別 比如地址或描述信息 >255個字元,超了就把文件路徑存放到資料庫中。 比如圖片,視頻等找一個文件伺服器,資料庫中只存路徑或url。 #3. 時間類型: 最常用:datetime #4. 枚舉類型與集合類型
數值類型
tinyint int create table int_t ( ti tinyint, # **** i int, # ***** f float, # 精度問題 小數點後5位 # ***** d double, # 精度更高但也不准確 e decimal(30,20) tiun tinyint unsigned, iun int unsigned );
日期類型
內置函數 now() datetime 打卡時間/日誌/論壇博客類的評論\文章 ***** date 員工生日/入職日期/離職日期/開班時間 ***** time 上課時間/下課時間/規定上班時間 競賽數據 year 年 timestamp 由於表示範圍的問題,導致用的少了 create table time_t2( dt datetime NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP, # 表示的範圍更大,還能擁有timestamp的特點 d date, t time, y year, ts timestamp # 不能為空,預設值是當前時間,在修改的時候同時更新時間 )
字元串類型
char 0-255 定長存儲 存儲速度更快 占用更多的空間 ***** char(12) alex --> 'alex ' --> 12的長度 varchar 0-65535 變長存儲 存儲速度慢 占用的空間小 **** varchar(12) 'alex' --> 'alex4' --> 5的長度 手機號碼/身份證號碼 : char 用戶名/密碼 : 有一定範圍彈性 char 評論 : varchar 時間換空間,空間換時間.沒有可以有也沒有可以無
枚舉類型與集合類型
set 多選 集合 去重 從有限的條件中多選一個引號里逗號分隔 enum 單選 枚舉 單選只能從有限的條件里選擇 沒有就是空 單選題,只能從有限的條件中選擇 create table enum_t( id int, name char(12), gender enum('男','女','不詳') ) gender性別(男 女 不詳) 多選題,從有限的條件中選 create table set_t( id int, name char(12), hobby set('抽煙','喝酒','燙頭','搓腳') )
4.MySQL完整性約束
PRIMARY KEY (PK) 標識該欄位為該表的主鍵,可以唯一的標識記錄
FOREIGN KEY (FK) 標識該欄位為該表的外鍵
NOT NULL 標識該欄位不能為空
UNIQUE KEY (UK) 標識該欄位的值是唯一的
AUTO_INCREMENT 標識該欄位的值自動增長(整數類型,而且為主鍵)
DEFAULT 為該欄位設置預設值
UNSIGNED 無符號
ZEROFILL 使用0填充==unsigned 無符號的:數字==
not null與default
not null 非空 null 可空
default 預設值
預設值,創建列時可以指定預設值,當插入數據時如果未主動設置,則自動添加預設值 create table tb1( nid int not null defalut 2, num int not null );
unique 唯一
普通唯一
獨一無二,唯一屬性:id,身份證號等
是一種key,唯一鍵,是在數據類型之外的附加屬性,有加速查詢的作用
create table department2( id int, name varchar(20), comment varchar(100), constraint uk_name unique(name) );
聯合唯一
create table service( id int primary key auto_increment, name varchar(20), host varchar(15) not null, port int not null, unique(host,port) #聯合唯一 );
primary key
從約束角度看primary key欄位的值不為空且唯一,那我們直接使用not null+unique不就可以了嗎,要它乾什麼?主鍵primary key是innodb存儲引擎組織數據的依據,innodb稱之為索引組織表,一張表中必須有且只有一個主鍵。
一個表中可以:單列做主鍵 多列做主鍵(複合主鍵或者叫做聯合主鍵)
關於主鍵的通俗解釋和強調內容(重點************************)
unique key和primary key都是MySQL的特殊類型,不僅僅是個欄位約束條件,還稱為索引,可以加快查詢速度,這個索引功能我們後面再講,現在只講一下這些key作為約束條件的效果。 關於主鍵的強調內容: 1.一張表中必須有,並且只能由一個主鍵欄位:innodb引擎下存儲表數據的時候,會通過你的主鍵欄位的數據來組織管理所有的數據,將數據做成一種樹形結構的數據結構,幫你較少IO次數,提高獲取定位數據、獲取數據的速度,優化查詢。 解釋:如果我們在一張表中沒有設置primary key,那麼mysql在創建表的時候,會按照順序從上到下遍歷你設置的欄位,直到找到一個not null unique的欄位,自動識別成主鍵pri,通過desc可以看到,這樣是不是不好啊,所以我們在創建表的時候,要給他一個主鍵,讓他優化的時候用,如果沒有pri也沒有not null unique欄位,那麼innodb引擎下的mysql被逼無奈,你沒有設置主鍵欄位,主鍵又有不為空且唯一的約束,又不能擅自給你的欄位加上這些約束,那麼沒辦法,它只能給你添加一個隱藏欄位來幫你組織數據,如果是這樣,你想想,主鍵是不是幫我們做優化查詢用的啊,這個優化是我們可以通過主鍵來查詢數據:例如:如果我們將id設置為主鍵,當我們查一個id為30的數據的時候,也就是select * from tb1 where id=30;這個查詢語句的速度非常快,不需要遍歷前面三十條數據,就好像我們使用的字典似的,找一個字,不需要一頁一頁的翻書,可以首先看目錄,然後看在哪一節,然後看在哪一頁,一步步的範圍,然後很快就找到了,這就像我們說的mysql的索引(主鍵、唯一鍵)的工作方式,一步一步的縮小範圍來查找,幾步就搞定了,所以通過主鍵你能夠快速的查詢到你所需要的數據,所以,如果你的主鍵是mysql幫你加的隱藏的欄位,你查詢數據的時候,就不能將這個隱藏欄位作為條件來查詢數據了,就不能享受到優化後的查詢速度了,對麽 2.一張表裡面,通常都應該有一個id欄位,而且通常把這個id欄位作為主鍵,當然你非要讓其他的欄位作為主鍵也是可以的,看你自己的設計,創建表的時候,一般都會寫create table t1(id int primary key);id int primary key這個東西在建表的時候直接就寫上在沒有設置主鍵的時候,not null+unique會被預設當成主鍵
mysql> create table t1(id int not null unique); Query OK, 0 rows affected (0.02 sec) mysql> desc t1; +-------+---------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+---------+------+-----+---------+-------+ | id | int(11) | NO | PRI | NULL | | +-------+---------+------+-----+---------+-------+ 1 row in set (0.00 sec)單列主鍵測試
============單列做主鍵=============== #方法一:not null+unique create table department1( id int not null unique, #主鍵 name varchar(20) not null unique, comment varchar(100) ); mysql> desc department1; +---------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------+--------------+------+-----+---------+-------+ | id | int(11) | NO | PRI | NULL | | | name | varchar(20) | NO | UNI | NULL | | | comment | varchar(100) | YES | | NULL | | +---------+--------------+------+-----+---------+-------+ rows in set (0.01 sec) #方法二:在某一個欄位後用primary key create table department2( id int primary key, #主鍵 name varchar(20), comment varchar(100) ); mysql> desc department2; +---------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------+--------------+------+-----+---------+-------+ | id | int(11) | NO | PRI | NULL | | | name | varchar(20) | YES | | NULL | | | comment | varchar(100) | YES | | NULL | | +---------+--------------+------+-----+---------+-------+ rows in set (0.00 sec) #方法三:在所有欄位後單獨定義primary key create table department3( id int, name varchar(20), comment varchar(100), constraint pk_name primary key(id); #創建主鍵併為其命名pk_name mysql> desc department3; +---------+--------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +---------+--------------+------+-----+---------+-------+ | id | int(11) | NO | PRI | NULL | | | name | varchar(20) | YES | | NULL | | | comment | varchar(100) | YES | | NULL | | +---------+--------------+------+-----+---------+-------+ rows in set (0.01 sec)聯合主鍵解釋
聯合主鍵 和聯合唯一是類似的, mysql> create table t10( ->id int, ->port int, ->primary key(id,port) -> ); Query OK, 0 rows affected (0.45 sec) mysql> desc t10; +-------+---------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+---------+------+-----+---------+-------+ | id | int(11) | NO | PRI | 0 | | | port | int(11) | NO | PRI | 0 | | +-------+---------+------+-----+---------+-------+ 2 rows in set (0.10 sec) 看key,兩個都寫的是pri,兩個聯合起來作為主鍵,他們兩個作為一個主鍵,不能再有其他的主鍵了,也就是在創建表的時候,只能出現一次primary key方法。 有同學說,老師,我不寫primary key行不,只寫一個not null unique欄位,當然行,但是我們應該這樣做嗎,是不是不應該啊,所以以後設置主鍵的時候,就使用primary key來指定多列(聯合)主鍵測試
==================多列做主鍵================ create table service( ip varchar(15), port char(5), service_name varchar(10) not null, primary key(ip,port) ); mysql> desc service; +--------------+-------------+------+-----+---------+-------+ | Field | Type | Null | Key | Default | Extra | +--------------+-------------+------+-----+---------+-------+ | ip | varchar(15) | NO | PRI | NULL | | | port | char(5) | NO | PRI | NULL | | | service_name | varchar(10) | NO | | NULL | | +--------------+-------------+------+-----+---------+-------+ 3 rows in set (0.00 sec) mysql> insert into service values -> ('172.16.45.10','3306','mysqld'), -> ('172.16.45.11','3306','mariadb') -> ; Query OK, 2 rows affected (0.00 sec) Records: 2 Duplicates: 0 Warnings: 0 mysql> insert into service values ('172.16.45.10','3306','nginx'); ERROR 1062 (23000): Duplicate entry '172.16.45.10-3306' for key 'PRIMARY'
auto_increment 自動增加
只能操作數字 自帶非空屬性 只能對unique欄位進行設置 不受刪除影響 內部有記錄
預設起始位置為1,步長也為1.
不指定id,則自動增長 create table student( id int primary key auto_increment, 設置自動增加 name varchar(20), sex enum('male','female') default 'male' );sex enum('male','female') default 'male' 創建表時指定auto_increment的初始值,註意初始值的設置為表選項,應該放到括弧外
insert into student values(4,'asb','female'); 設置ID 對於自增的欄位,在用delete刪除後,再插入值,該欄位仍按照刪除前的位置繼續增長
insert into student(name) values('egon'); truncate student; 應該用truncate清空表,比起delete一條一條地刪除記錄,truncate是直接清空表,在刪除大表時用它(從0開始)
alter table student auto_increment=3; 在創建完表後,修改自增欄位的起始值
show create table student;
ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8(顯示預設值)設置自增:
set session auth_increment_increment=2 #修改會話級別的步長
set global auth_increment_increment=2 #修改全局級別的步長(所有會話都生效)
foreign key 外鍵約束
快速理解foreign key(外鍵其實就是標明表和表之間的關係,表和表之間如果有關係的話就三種:一對一,多對一,多對多)
on delete cascade 級聯刪除 on update cascade 級聯更新
分析步驟:
先站在左表的角度去找
是否左表的多條記錄可以對應右表的一條記錄,如果是,則證明左表的一個欄位foreign key 右表一個欄位(通常是id)
再站在右表的角度去找
是否右表的多條記錄可以對應左表的一條記錄,如果是,則證明右表的一個欄位foreign key 左表一個欄位(通常是id)
總結
- 多對一: 如果只有步驟1成立,則是左表多對一右表 如果只有步驟2成立,則是右表多對一左表
- 多對多:如果步驟1和2同時成立,則證明這兩張表時一個雙向的多對一,即多對多,需要定義一個這兩張表的關係表來專門存放二者的關係
- 一對一:如果1和2都不成立,而是左表的一條記錄唯一對應右表的一條記錄,反之亦然。這種情況很簡單,就是在左表foreign key右表的基礎上,將左表的外鍵欄位設置成unique即可
=====================多對一===================== create table press( id int primary key auto_increment, name varchar(20) ); create table book( id int primary key auto_increment, name varchar(20), press_id int not null, foreign key(press_id) references press(id) on delete cascade on update cascade ); insert into press(name) values ('北京工業地雷出版社'), ('人民音樂不好聽出版社'), ('知識產權沒有用出版社') ; insert into book(name,press_id) values ('九陽神功',1), ('九陰真經',2), ('九陰白骨爪',2), ('獨孤九劍',3), ('降龍十巴掌',2), ('葵花寶典',3) =====================多對多===================== create table author( id int primary key auto_increment, name varchar(20) ); #這張表就存放作者表與書表的關係,即查詢二者的關係查這表就可以了 create table author2book( id int not null unique auto_increment, author_id int not null, book_id int not null, constraint fk_author foreign key(author_id) references author(id) on delete cascade on update cascade, constraint fk_book foreign key(book_id) references book(id) on delete cascade on update cascade, primary key(author_id,book_id) ); #插入四個作者,id依次排開 insert into author(name) values('egon'),('alex'),('yuanhao'),('wpq'); #每個作者與自己的代表作如下 1 egon: 1 九陽神功 2 九陰真經 3 九陰白骨爪 4 獨孤九劍 5 降龍十巴掌 6 葵花寶典 2 alex: 1 九陽神功 6 葵花寶典 3 yuanhao: 4 獨孤九劍 5 降龍十巴掌 6 葵花寶典 4 wpq: 1 九陽神功 insert into author2book(author_id,book_id) values (1,1), (1,2), (1,3), (1,4), (1,5), (1,6), (2,1), (2,6), (3,4), (3,5), (3,6), (4,1) ; =====================一對一===================== 一定是student來foreign key表customer,這樣就保證了: 1 學生一定是一個客戶, 2 客戶不一定是學生,但有可能成為一個學生 create table customer( id int primary key auto_increment, name varchar(20) not null, qq varchar(10) not null, phone char(16) not null ); create table student( id int primary key auto_increment, class_name varchar(20) not null, customer_id int unique, #該欄位一定要是唯一的 foreign key(customer_id) references customer(id) #外鍵的欄位一定要保證unique on delete cascade on update cascade ); #增加客戶 insert into customer(name,qq,phone) values ('李飛機','31811231',13811341220), ('王大炮','123123123',15213146809), ('守榴彈','283818181',1867141331), ('吳坦克','283818181',1851143312), ('贏火箭','888818181',1861243314), ('戰地雷','112312312',18811431230) ; #增加學生 insert into student(class_name,customer_id) values ('脫產3班',3), ('周末19期',4), ('周末19期',5) ;- 多對一: 如果只有步驟1成立,則是左表多對一右表 如果只有步驟2成立,則是右表多對一左表
外鍵約束有三種約束模式(都是針對父表的約束):
- 模式一: district 嚴格約束(預設的 ),父表不能刪除或者更新已經被子表數據引用的記錄
- 模式二:cascade 級聯模式:父表的操作,對應的子表關聯的數據也跟著操作 。
- 模式三:set null:置空模式,父表操作之後,子表對應的數據(外鍵欄位)也跟著被置空。
- 通常的一個合理的約束模式是:刪除的時候子表置空;更新的時候子表級聯。
- 指定模式的語法:foreign key(外鍵欄位)references 父表(主鍵欄位)on delete 模式 on update 模式;
- 註意:刪除置空的前提條件是 外鍵欄位允許為空,不然外鍵會創建失敗。
- 外鍵雖然很強大,能夠進行各種約束,但是外鍵的約束降低了數據的可控性和可拓展性。通常在實際開發時,很少使用外鍵來約束。
3.MySQL的行的詳細操作
1.刪除或修改被關聯欄位
場景:book表和publish表為多對一關係,book表的pid欄位外鍵關聯到了publish表的id欄位
1 查看外鍵關係名稱:
show create table book;
| book | CREATE TABLE `book` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` char(10) DEFAULT NULL,
`pid` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `pid` (`pid`),
CONSTRAINT `book_ibfk_1` FOREIGN KEY (`pid`) REFERENCES `publish` (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8 |
2 刪除外鍵關係
alter table book drop foreign key book_ibfk_1(外鍵名稱);
3 刪除欄位
alter table publish drop id(欄位名稱);
4 添加欄位
alter table publish add id(欄位名稱) int(數據類型) primary key auto_increment(約束條件);
5 創建表完成之後,後添加外鍵關係
alter table book add foreign key(pid) references publish(id);
2.創建外鍵時指定外鍵名稱
創建表時:
create table t1(
id int,
pid int,
constraint fk_t1_publish foreign key(pid) references publish(id);
)
創建表完成之後,後添加外鍵關係
alter table book add constraint fk_t1_publish foreign key(pid) references publish(id);
3.級聯
級聯有幾個模式
嚴格模式(預設的),外鍵有強制約束效果,被關聯欄位不能隨意刪除和修改
模式(cascade):外鍵有強制約束效果,被關聯欄位刪除或者修改,關聯他的那麼欄位數據會隨之刪除或者修改
constraint fk_t1_publish foreign key(pid) references publish(id) on delete cascade on update cascade;
set null模式: 被關聯欄位刪除時,關聯他的欄位數據會置成null
4.增刪改查
- 增:insert into t1 values(1,'egon1'),(2,'egon2'),(3,'egon3');
- 查:select * from t1;
- 改:update t1 set name='sb' where id=2; 後面加條件
- 刪:delete from t1 where id=1;
5.SQL語句(三種)
- DDL語句 資料庫定義語言: 資料庫、表、視圖、索引、存儲過程,例如CREATE DROP ALTER
- DML語句 資料庫操縱語言: 插入數據INSERT、刪除數據DELETE、更新數據UPDATE、查詢數據SELECT
- DCL語句 資料庫控制語言: 例如控制用戶的訪問許可權GRANT、REVOKE
6.額外
- *auto_increment 表示:自增
- *primary key 表示:約束(不能重覆且不能為空);加速查找
4.單表查詢
前提
1.單表查詢
select 某一個東西
可以查一個,多個,*所有
調用函數 : now() user() database() concat() concat_ws()
進行四則運算
可以去重 distinct
可以進行條件判斷 case when語句
2.單標查詢的語法
查詢數據的本質:mysql會到你本地的硬碟上找到對應的文件,然後打開文件,按照你的查詢條件來找出你需要的數據。下麵是完整的一個單表查詢的語法
select * from,這個select * 指的是要查詢所有欄位的數據。
SELECT distinct 欄位1,欄位2... FROM 庫名.表名
from後面是說從庫的某個表中去找數據,mysql會去找到這個庫對應的文件夾下去找到你表名對應的那個數據文件,找不到就直接報錯了,找到了就繼續後面的操作
WHERE 條件 從表中找符合條件的數據記錄,where後面跟的是你的查詢條件
GROUP BY field(欄位) 分組
HAVING 篩選 過濾,過濾之後執行select後面的欄位篩選,就是說我要確定一下需要哪個欄位的數據,你查詢的欄位數據進行去重,然後在進行下麵的操作
ORDER BY field(欄位) 將結果按照後面的欄位進行排序
LIMIT 限制條數 將最後的結果加一個限制條數,就是說我要過濾或者說限制查詢出來的數據記錄的條數
3.==重點中的重點==:關鍵字的執行優先順序
from > where > group by > having > select > distinct > order by > limit
- 找到表:from
- 拿著where指定的約束條件,去文件/表中取出一條條記錄
- 將取出的一條條記錄進行分組group by,如果沒有group by,則整體作為一組
- 將分組的結果進行having過濾
- 執行select
- 去重
- 將結果按條件排序:order by
- 限制結果的顯示條數
- 詳細博客
1.簡單查詢(*)
避免重覆DISTINCT:
desc employee; 查看表結構
SELECT id,name,sex,age,hire_date,post,post_comment,salary,office,depart_id FROM employee; select後面寫什麼查詢什麼
SELECT * FROM employee; 查詢全部 不推薦用* ,查詢的時候*的效率低,
SELECT name,salary FROM employee; 查詢所有的name和salary
SELECT post FROM employee; 查詢所有的post 但是有重覆
SELECT DISTINCT post FROM employee; 查詢post distinct去重功能
SELECT DISTINCT post,salary FROM employee; 因為post和salary沒有完全一樣的
select distinct post,sex from employee; post和sex兩組數據一樣才會去重
通過四則運算查詢:
SELECT name, salary*12 FROM employee; 查薪資每個都*12
SELECT name, salary*12 AS Annual_salary FROM employee; as + 新欄位名,就是起一個別名
SELECT name, salary*12 Annual_salary FROM employee; 通過新的別名查詢 除了乘法以外,加減乘除都是可以的
自定義顯示格式,自己規定查詢結果的顯示格式:
CONCAT() 函數用於連接字元串
SELECT CONCAT('姓名: ',name,' 年薪: ', salary*12) AS Annual_salary from employee; concat幫我們做字元串拼接的,並且拼接之後的結果,都在一個叫做Annual_salary的欄位中
SELECT CONCAT('姓名: ',name,' 年薪: ', salary*12) AS Annual_salary,CONCAT('性別:',sex) from employee; 分成兩列
SELECT CONCAT(name,':',salary*12) AS Annual_salary from employee; 通過冒號來將name和salary連接起來
select concat('<名字:',name,'> ','<薪資:',salary,'>') from employee; 查出所有員工的名字,薪資,格式為 <名字:egon> <薪資:3000>
select distinct depart_id from employee; 查出所有的崗位(去掉重覆)
SELECT name,salary*12 AS annual_year from employee; 查出所有員工名字,以及他們的年薪,年薪的欄位名為annual_year()
2.where約束
之前我們用where 後面跟的語句是不是id=1這種類型的啊,用=號連接的,除了=號外,還能使用其他的,看下麵:
比較運算符:> < >= <= <> !=
between 80 and 100 值在80到100之間
and是都滿足 or只要滿足一個
in(80,90,100) 值是80或90或100
like 'egon%'
pattern可以是%或_,
%表示任意多字元
_表示一個字元邏輯運算符:在多個條件直接可以使用邏輯運算符 and or not
1:單條件查詢 SELECT name FROM employee WHERE post='sale'; 單表查詢 優先順序,where的優先順序比select高,所以順序是先找到這個employee表,然後按照post='sale'的條件,然後去表裡面select數據 2:多條件查詢 SELECT name,salary FROM employee WHERE post='teacher' AND salary>10000; 多條件查詢 3:關鍵字BETWEEN AND 寫的是一個區間 SELECT name,salary FROM employee WHERE salary BETWEEN 10000 AND 20000; 關鍵字BETWEEN AND 是一個區間 SELECT name,salary FROM employee WHERE salary NOT BETWEEN 10000 AND 20000; 加個not,就是不在這個區間內 4:關鍵字IS NULL(判斷某個欄位是否為NULL不能用等號,需要用IS) 判斷null只能用is SELECT name,post_comment FROM employee WHERE post_comment IS NULL; 關鍵字IS NULL(判斷某個欄位是否為NULL不能用等號,需要用IS) 判斷null只能用is SELECT name,post_comment FROM employee WHERE post_comment IS NOT NULL; 加not, SELECT name,post_comment FROM employee WHERE post_comment=''; ''是空字元串,不是null,兩個是不同的東西,null是啥也沒有,''是空的字元串的意思,是一種數據類型,null是另外一種數據類型 5:關鍵字IN集合查詢 SELECT name,salary FROM employee WHERE salary IN (3000,3500,4000,9000) ; salary裡面是in條件的列印 SELECT name,salary FROM employee WHERE salary NOT IN (3000,3500,4000,9000) ; salary裡面不是in條件的列印 6:關鍵字LIKE模糊查詢,模糊匹配,可以結合通配符來使用 SELECT * FROM employee WHERE name LIKE 'eg%'; 通配符’%’ 匹配任意所有字元 SELECT * FROM employee WHERE name LIKE 'al__'; 通配符’_’ 匹配任意一個字元 註意我這裡寫的兩個_,用1個的話,匹配不到alex,因為al後面還有兩個字元ex。 1. 查看崗位是teacher的員工姓名、年齡 select name,age from employee where post = 'teacher'; 2. 查看崗位是teacher且年齡大於30歲的員工姓名、年齡 select name,age from employee where post='teacher' and age > 30; 3. 查看崗位是teacher且薪資在9000-1000範圍內的員工姓名、年齡、薪資 select name,age,salary from employee where post='teacher' and salary between 9000 and 10000; 4. 查看崗位描述不為NULL的員工信息 select * from employee where post_comment is not null; 5. 查看崗位是teacher且薪資是10000或9000或30000的員工姓名、年齡、薪資 select name,age,salary from employee where post='teacher' and salary in (10000,9000,30000); 6. 查看崗位是teacher且薪資不是10000或9000或30000的員工姓名、年齡、薪資 select name,age,salary from employee where post='teacher' and salary not in (10000,9000,30000); 7. 查看崗位是teacher且名字是jin開頭的員工姓名、年薪 select name,salary*12 from employee where post='teacher' and name like 'jin%';where條件咱們就說完了,這個where條件到底怎麼運作的,我們來說一下:我們以select id,name,age from employee where id>7;這個語句來說一下 首先先找到employee表,找到這個表之後,mysql會拿著where後面的約束條件去表裡面找符合條件的數據,然後遍歷你表中所有的數據,查看一下id是否大於7,逐條的對比,然後只要發現id比7大的,它就會把這一整條記錄給select,但是select說我只拿id、name、age這個三個欄位裡面的數據,然後就列印了這三個欄位的數據,然後where繼續往下過濾,看看id是不是還有大於7的,然後發現一個符合條件的就給select一個,然後重覆這樣的事情,直到把數據全部過濾一遍才會結束。這就是where條件的一個工作方式。
3.分組查詢 group by
示例:
# 統計每個崗位的名稱以及最高工資
select post,max(salary) from employee group by post;
分組時可以跟多個條件,那麼這個多個條件同時重覆才算是一組,group by 後面多條件用逗號分隔
select post,max(salary) from employee group by post,id;
ONLY_FULL_GROUP_BY模式
set global sql_mode='ONLY_FULL_GROUP_BY';
如果設置了這個模式,那麼select後面只能寫group by後面的分組依據欄位和聚合函數統計結果
什麼是分組?為什麼要分組?
首先明確一點:分組發生在where之後,即分組是基於where之後得到的記錄而進行的
分組指的是:將所有記錄按照某個相同欄位進行歸類,比如針對員工信息表的職位分組,或者按照性別進行分組等
為何要分組呢?是因為我們有時候會需要以組為單位來統計一些數據或者進行一些計算的,對不對,比方說下麵的幾個例子
取每個部門的最高工資
取每個部門的員工數
取男人數和女人數小竅門:‘每’這個字後面的欄位,就是我們分組的依據,只是個小竅門,但是不能表示所有的情況,看上面第三個分組,沒有'每'字,這個就需要我們通過語句來自行判斷分組依據
我們能用id進行分組嗎,能,但是id是不是重覆度很低啊,基本沒有重覆啊,對不對,這樣的欄位適合做分組的依據嗎?不適合,對不對,依據性別分組行不行,當然行,因為性別我們知道,是不是就兩種啊,也可能有三種是吧,這個重覆度很高,對不對,分組來查的時候才有更好的意義
大前提:
可以按照任意欄位分組,但是分組完畢後,比如group by post,只能查看post欄位,如果想查看組內信息,需要藉助於聚合函數. 註意一點,在查詢語句裡面select 欄位 from 表,這幾項是必須要有的,其他的什麼where、group by等等都是可有可無的select * from employee group by post; group by 語句 按照post分組
4.having過濾(分組再過濾)
select post,max(salary) from employee group by post having max(salary)>20000;
having過濾後面的條件可以使用聚合函數,where不行
select post,avg(salary) as new_sa from employee where age>=30 group by post having avg(salary) > 10000;統計各部門年齡在30歲及以上的員工的平均薪資,並且保留平均工資大於10000的部門
select post,group_concat(name),count(id) from employee group by post having count(id) < 2;查詢各崗位內包含的員工個數小於2的崗位名、崗位內包含員工名字、個數
select post,avg(salary) from employee group by post having avg(salary) > 10000;查詢各崗位平均薪資大於10000的崗位名、平均工資
select post,avg(salary) from employee group by post having avg(salary) > 10000 and avg(salary) <20000;查詢各崗位平均薪資大於10000且小於20000的崗位名、平均工資
select count(distinct post) from employee;
去重distinct 統計個數count
5.去重
示例:
select distinct post from employee;
註意問題:select的欄位必須寫在distinct的後面,並且如果寫了多個欄位,比如:
select distinct post,id from employee;這句話,意思就是post和id兩個組合在一起同時重覆的才算是重覆數據
6.查詢排序 order by
按單列排序 salary排序的
SELECT * FROM employee ORDER BY salary; #預設是升序排列
SELECT * FROM employee ORDER BY salary ASC; #升序
SELECT * FROM employee ORDER BY salary DESC; #降序
多條件排序
按照age欄位升序,age相同的數據,按照salary降序排列
select * from employee order by age asc ,salary esc;
1. 查詢所有員工信息,先按照age升序排序,如果age相同則按照hire_date降序排序
select * from employee order by age ASC,hire_date DESC;
2. 查詢各崗位平均薪資大於10000的崗位名、平均工資,結果按平均薪資升序排列
select post,avg(salary) from employee group by post having avg(salary) > 10000 order by avg(salary) asc;
3. 查詢各崗位平均薪資大於10000的崗位名、平均工資,結果按平均薪資降序排列
select post,avg(salary) from employee group by post having avg(salary) > 10000 order by avg(salary) desc;
7.限制查詢的記錄數 limit
取出工資最高的前三位
SELECT * FROM employee ORDER BY salary DESC
LIMIT 3; 預設初始位置為0,從第一條開始順序取出三條
SELECT * FROM employee ORDER BY salary DESC
LIMIT 0,5; 從第0開始,即先查詢出第一條,然後包含這一條在內往後查5條
SELECT * FROM employee ORDER BY salary DESC
LIMIT 5,5; 從第5開始,即先查詢出第6條,然後包含這一條在內往後查5條
==到目前為止,單表查詢所有的語法都講完了,語法就是按照我們博客最上面說的語法順序來寫,但是執行的時候,要按照對應的各個方法的優先順序去執行。==
8.補充:級聯set null的用法和示例
mysql> create table tt2(id int primary key auto_increment,name char(10));
mysql> create table tt3(id int,pid int,foreign key(pid) references tt2(id) on delete set null);
Query OK, 0 rows affected (1.06 sec)
mysql> desc tt3;
+-------+---------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| pid | int(11) | YES | MUL | NULL | |
+-------+---------+------+-----+---------+-------+
2 rows in set (0.01 sec)
mysql> insert into tt2(name) values('xx1'),('xx2');
Query OK, 2 rows affected (0.14 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> insert into tt3 values(1,1),(2,1);
Query OK, 2 rows affected (0.12 sec)
Records: 2 Duplicates: 0 Warnings: 0
mysql> select * from tt3;
+------+------+
| id | pid |
+------+------+
| 1 | 1 |
| 2 | 1 |
+------+------+
2 rows in set (0.00 sec)
mysql> delete from tt2 where id = 1;
Query OK, 1 row affected (0.10 sec)
mysql> select * from tt3;
+------+------+
| id | pid |
+------+------+
| 1 | NULL |
| 2 | NULL |
+------+------+
2 rows in set (0.00 sec)
9.使用正則表達式
之前我們用like做模糊匹配,只有%和_,局限性比較強,所以我們說一個正則,之前我們是不是學過正則匹配,你之前學的正則表達式都可以用,正則是通用的
SELECT * FROM employee WHERE name REGEXP '^ale';
SELECT * FROM employee WHERE name REGEXP 'on$';
SELECT * FROM employee WHERE name REGEXP 'm{2}';
小結:對字元串匹配的方式
WHERE name = 'egon';
WHERE name LIKE 'yua%';
WHERE name REGEXP 'on$';
查看所有員工中名字是jin開頭,n或者g結果的員工信息
select * from employee where name regexp '^jin.*[g|n]$';10.聚合函數
強調:聚合函數聚合的是組的內容,若是沒有分組,則預設一組
SELECT COUNT(*) FROM employee; count是統計個數
SELECT COUNT(*) FROM employee WHERE depart_id=1; 後面跟where條件的意思是統計一下滿足depart_id=1這個的所有記錄的個數
SELECT MAX(salary) FROM employee; max()統計分組後每組的最大值,這裡沒有寫group by,那麼就是統計整個表中所有記錄中薪資最大的,薪資的值
SELECT MIN(salary) FROM employee;
SELECT AVG(salary) FROM employee;
SELECT SUM(salary) FROM employee;
SELECT SUM(salary) FROM employee WHERE depart_id=3;
11.帶IN關鍵字的子查詢
#查詢員工平均年齡在25歲以上的部門名,可以用連表,也可以用子查詢,我們用子查詢來搞一下
select id,name from department
where id in
(select dep_id from employee group by dep_id having avg(age) > 25);
#連表來搞一下上面這個需求
select department.name from department inner join employee on department.id=employee.dep_id
group by department.name
having avg(age)>25;
總結:子查詢的思路和解決問題一樣,先解決一個然後拿著這個的結果再去解決另外一個問題,連表的思路是先將兩個表關聯在一起,然後在進行group by啊過濾啊等等操作,兩者的思路是不一樣的
#查看技術部員工姓名
select name from employee
where dep_id in
(select id from department where name='技術');
#查看不足1人的部門名(子查詢得到的是有人的部門id)
select name from department where id not in (select distinct dep_id from employee);
12.帶比較運算符的子查詢
待定代碼有問題,沒有表,無法驗證
#比較運算符:=、!=、>、>=、<、<=、<>
#查詢大於所有人平均年齡的員工名與年齡
mysql> select name,age from emp where age > (select avg(age) from emp);
#查詢大於部門內平均年齡的員工名、年齡
select t1.name,t1.age from emp t1
inner join
(select dep_id,avg(age) avg_age from emp group by dep_id) t2
on t1.dep_id = t2.dep_id
where t1.age > t2.avg_age;
13.帶EXISTS關鍵字的子查詢
EXISTS關字鍵字表示存在。在使用EXISTS關鍵字時,內層查詢語句不返回查詢的記錄。而是返回一個真假值。True或False
當返回True時,外層查詢語句將進行查詢;當返回值為False時,外層查詢語句不進行查詢。還可以寫not exists,和exists的效果就是反的
select * from employee
where exists
(select id from department where id=200);
department表中存在dept_id=203,Ture
不存在的時候是錯 返回 Empty set (0.00 sec)
14.GROUP BY
單獨使用GROUP BY關鍵字分組
SELECT post FROM employee GROUP BY post;
註意:我們按照post欄位分組,那麼select查詢的欄位只能是post,想要獲取組內的其他相關信息,需要藉助函數
GROUP BY關鍵字和GROUP_CONCAT()函數一起使用,比如說我想按部門分組,每個組有哪些員工,都顯示出來
SELECT post,GROUP_CONCAT(name) FROM employee GROUP BY post; 按照崗位分組,並查看組內所有成員名,通過逗號拼接在一起
SELECT post,GROUP_CONCAT(name,':',salary) as emp_members FROM employee GROUP BY post;按照崗位分組,並查看組內所有成員名,通過逗號拼接在一起
GROUP BY一般都會與聚合函數一起使用,聚合是什麼意思:聚合就是將分組的數據聚集到一起,合併起來搞事情,拿到一個最後的結果
select post,count(id) as count from employee group by post; 按照崗位分組,並查看每個組有多少人,每個人都有唯一的id號,我count是計算一下分組之後每組有多少的id記錄,通過這個id記錄我就知道每個組有多少人了
關於集合函數,mysql提供了以下幾種聚合函數:count、max、min、avg、sum等,上面的group_concat也算是一個聚合函數了,做字元串拼接的操作
15.ONLY_FULL_GROUP_BY (設置)
16.練習
1. 查詢崗位名以及崗位包含的所有員工名字
'''
a、先看一下和哪個表有關係:所有的信息都在employee這個表裡面,所以先寫from employee,找到表了
b、看有沒有什麼過濾條件,大於小於啊什麼的,沒有吧,所以是不是不需要寫where條件啊
c、看看有沒有分組的內容,也就是看看上面的需求裡面有沒有分類的概念,發現是不是有啊,按照崗位來分組,對不對,所以該寫什麼了:from employee group by post;
d、然後再看需要查什麼欄位出來,發現是不是要看崗位名和所有員工的名字啊,所以怎麼寫:select post,group_concat(name) from employee group by post;這就是完整語句了,不信你試試
'''
下麵的題都按照上面這個邏輯來搞一搞:
2. 查詢崗位名以及各崗位內包含的員工個數
3. 查詢公司內男員工和女員工的個數
4. 查詢崗位名以及各崗位的平均薪資
5. 查詢崗位名以及各崗位的最高薪資
6. 查詢崗位名以及各崗位的最低薪資
7. 查詢男員工與男員工的平均薪資,女員工與女員工的平均薪資。
8.統計各部門年齡在30歲及以上的員工平均薪資
想一下怎麼寫,1、from 表 2、where age>=30得到一張虛擬表 3、對虛擬表按部門group by 4、select 部門和聚合函數avg
答案:select post,avg(salary) from employee where age>=30 group by post;
看結果:
mysql> select post,avg(salary) from employee where age>=30 group by post; 因為有的部門裡面的員工沒有大於30歲的,所以沒有顯示出所有的部門
+---------+---------------+
| post | avg(salary) |
+---------+---------------+
| sale | 2500.240000 |
| teacher | 255450.077500 |
+---------+---------------+
2 rows in set (0.09 sec)
到這裡我們的group by就講完了,看一下我們完整查詢語句裡面還有什麼
SELECT distinct 欄位1,欄位2... FROM 庫名.表名
WHERE 條件
GROUP BY field(欄位)
HAVING 篩選 #過濾,過濾之後執行select後面的欄位篩選,就是說我要確定一下需要哪個欄位的數據,你查詢的欄位數據進行去重,然後在進行下麵的操作
ORDER BY field(欄位) #將結果按照後面的欄位進行排序
LIMIT 限制條數
註意:雖然語法裡面我們先寫的select,但是並不是先執行的select,按照mysql自己的規範來執行的下麵關鍵字的優先順序
from
where
group by
having
select
distinct
order by
limit
5.多表查詢
介紹 建表
#部門表
create table department(
id int,
name varchar(20)
);
#員工表,之前我們學過foreign key,強行加上約束關聯,但是我下麵這個表並沒有直接加foreign key,這兩個表我只是讓它們在邏輯意義上有關係,並沒有加foreign key來強制兩表建立關係,為什麼要這樣搞,是有些效果要給大家演示一下
#所以,這兩個表是不是先建立哪個表都行啊,如果有foreign key的話,是不是就需要註意表建立的順序了。那我們來建表。
create table employee(
id int primary key auto_increment,
name varchar(20),
sex enum('male','female') not null default 'male',
age int,
dep_id int
);
#給兩個表插入一些數據
insert into department values
(200,'技術'),
(201,'人力資源'),
(202,'銷售'),
(203,'運營'); #註意這一條數據,在下麵的員工表裡面沒有對應這個部門的數據
insert into employee(name,sex,age,dep_id) values
('egon','male',18,200),
('alex','female',48,201),
('wupeiqi','male',38,201),
('yuanhao','female',28,202),
('liwenzhou','male',18,200),
('jingliyang','female',18,204) #註意這條數據的dep_id欄位的值,這個204,在上面的部門表裡面也沒有對應的部門id。所以兩者都含有一條雙方沒有涉及到的數據,這都是為了演示一下效果設計的昂
;
#查看表結構和數據
mysql> desc department;
#查看
mysql> desc employee;
mysql> select * from department;
mysql> select * from employee1;
1.多表連表查詢
重點:外鏈接語法
SELECT 欄位列表
FROM 表1 INNER|LEFT|RIGHT JOIN 表2
ON 表1.欄位 = 表2.欄位;
1.交叉連接:不適用任何匹配條件。生成笛卡爾積
查詢順序不一樣 一個在前一個在後
沒有給條件所以全部顯示 這就是笛卡爾積
mysql> select * from department,employee;
mysql> select * from employee,department;
2.內連接:只連接匹配的行
mysql> select * from employee,department where employee.dep_id=department.id; #拿出id對應的數據,後面加判斷
select employee.name from employee,department where employee.dep_id=department.id and department.name='技術';#有兩個表的時候前面顯示的name必須指定表,否則會報錯
3.外鏈接之左連接:優先顯示左表全部記錄
left join 左邊語法
select employee.id,employee.name,department.name as depart_name from employee left join department on employee.dep_id=department.id;#以左表為準,即找出所有員工信息,當然包括沒有部門的員工 本質就是:在內連接的基礎上增加左邊有右邊沒有的結果
4.外鏈接之右連接:優先顯示右表全部記錄
right join 右邊語法
select employee.id,employee.name,department.name as depart_name from employee right join department on employee.dep_id=department.id;#以右表為準,即找出所有部門信息,包括沒有員工的部門 本質就是:在內連接的基礎上增加右邊有左邊沒有的結果
5.全外連接:顯示左右兩個表全部記錄
select * from employee left join department on employee.dep_id = department.id
union
select * from employee right join department on employee.dep_id = department.id
;
#註意:mysql不支持全外連接 full JOIN 強調:mysql可以使用此種方式間接實現全外連接
#註意 union與union all的區別:union會去掉相同的紀錄,因為union all是left join 和right join合併,所以有重覆的記錄,通過union就將重覆的記錄去重了。
6.符合條件連接查詢
select employee.name,department.name
from employee inner join department on
employee,dep_id=department.id where age>25;
#以內連接的方式查詢employee和department表,並且employee表中的age欄位值必須大於25,即找出年齡大於25歲的員工以及員工所在的部門
select employee.id,employee.name,employee.age,department.name
from employee,department
where employee.dep_id = department.idand age > 25
order by age asc;
#以內連接的方式查詢employee和department表,並且以age欄位的升序方式顯示
7.子查詢
select * from employee inner join department on employee.dep_id = department.id; #查看那些部門有哪些員工,先連表 在查詢
select employee.name from employee inner join department on employee.dep_id = department.id where department.name='技術';#查看某個部門的員工名單,然後根據連表的結果進行where過濾,將select*改為select employee.name
select name from employee where dep_id = (select id from department where name='技術');#那我們把上面的查詢結果用括弧括起來,它就表示一條id=200的數據,然後我們通過員工表來查詢dep_id=這條數據作為條件來查詢員工的name
這些就是子查詢的一個思路,解決一個問題,再解決另外一個問題,你子查詢裡面可不可以是多個表的查詢結果,當然可以,然後再通過這個結果作為依據來進行過濾,然後我們學一下子查詢裡面其他的內容,
子查詢:
1:子查詢是將一個查詢語句嵌套在另一個查詢語句中。
2:內層查詢語句的查詢結果,可以為外層查詢語句提供查詢條件。
3:子查詢中可以包含:IN、NOT IN、ANY、ALL、EXISTS 和 NOT EXISTS等關鍵字
4:還可以包含比較運算符:= 、 !=、> 、<等
6.Navicat工具
圖形化操作資料庫表
掌握:
1. 測試+鏈接資料庫
2. 新建庫
3. 新建表,新增欄位+類型+約束
4. 設計表:外鍵
5. 新建查詢
6. 備份庫/表
註意:
批量加註釋:ctrl+?鍵
批量去註釋:ctrl+shift+?鍵
7.pymysql模快和SQL註入問題
先安裝pymysql第三方模塊,導入模塊.
import pymysql
conn = pymysql.connect(
host='127.0.0.1', #主機
port=3306, #埠號
user='root',#用戶名
password='666', #密碼
database='day43', #需要連接的庫
charset='utf8'
)
cursor = conn.cursor()
sql = "select * from dep;"
ret = cursor.execute(sql) #ret 受影響的行數
print(cursor.fetchall()) #取出所有的
print(cursor.fetchmany(3)) #取出多條
print(cursor.fetchone()) #取出單條
cursor.scroll(3,'absolute') #絕對移動,按照數據最開始位置往下移動3條
cursor.scroll(3,'relative') #相對移動,按照當前游標位置往下移動3條
conn.commit() #增刪改操作時,需要進行提交
sql註入:解決方案
cursor.execute(sql,[參數1,參數2...])
不知道密碼或者用戶名就可以登陸的操作
防止沒有密碼登陸操作(瞭解)
8.聚集索引和普通索特性介紹
聚集索引(主鍵) id int primary key
普通索引 Index index_name(id)
唯一索引 int unique
主鍵:
表創建完了之後添加: Alter table 表名 add primary key(id)
刪除主鍵索引: Alter table 表名 drop primary key;
唯一索引:
表創建好之後添加唯一索引: alter table s1 add unique key u_name(id);
刪除: alter table s1 drop unique key u_name;
普通索引:
創建:
Create table t1(
Id int,
Index index_name(id)
)
Alter table s1 add index index_name(id);
Create index index_name on s1(id);
刪除:
Alter table s1 drop index u_name;
DROP INDEX 索引名 ON 表名字;
聯合索引(聯合主鍵\聯合唯一\聯合普通索引)
Create table t1(
Id int,
name char(10),
Index index_name(id,name)
)
b+樹:提高查詢效率
聚集索引
組織存儲整表所有數據的依據
id primary key
葉子節點存的是真是數據,存的是整行記錄
輔助索引(普通索引)
普通索引建立樹形結構,提高查詢效率,但是葉子節點存的是該列的數據和對應行的主鍵值
index name_index(name)
unique name_index(name)
select name from 表名 where name='xx';
葉子節點找到了對應數據,稱為覆蓋索引
找不到列數據,需要回表操作(拿著主鍵重新走一遍主鍵的樹形結構找到對應行的那一列數據)
索引分類
主鍵索引 唯一索引 普通索引
聯合主鍵索引 聯合唯一索引 聯合普通索引
聯合索引的最左匹配

