
整個Flink的Job啟動是通過在Driver端通過用戶的Envirement的execute()方法將用戶的運算元轉化成StreamGraph 然後得到JobGraph通過遠程RPC將這個JobGraph提交到JobManager對應的介面 JobManager轉化成executionGraph.d ...
整個Flink的Job啟動是通過在Driver端通過用戶的Envirement的execute()方法將用戶的運算元轉化成StreamGraph
然後得到JobGraph通過遠程RPC將這個JobGraph提交到JobManager對應的介面
JobManager轉化成executionGraph.deploy(),然後生成TDD發給TaskManager,然後整個Job就啟動起來了
這裡來看一下Driver端的實現從用戶的Envirement.execute()方法作為入口
這裡的Envirement分為
RemoteStreamEnvironment
LocalStreamEnvironment
因為local模式比較簡單這裡就不展開了,主要是看下RemoteStreamEnvironment的execute方法

可以看到這裡先獲取到了streamGraph,具體獲取的實現

這裡傳入了一個transformations其中就包含了我們用戶的所有operator

這個地方就是遍歷了用戶端所有的operator生成StreamGraph,遍歷的每一個運算元具體轉化成streamGraph的邏輯
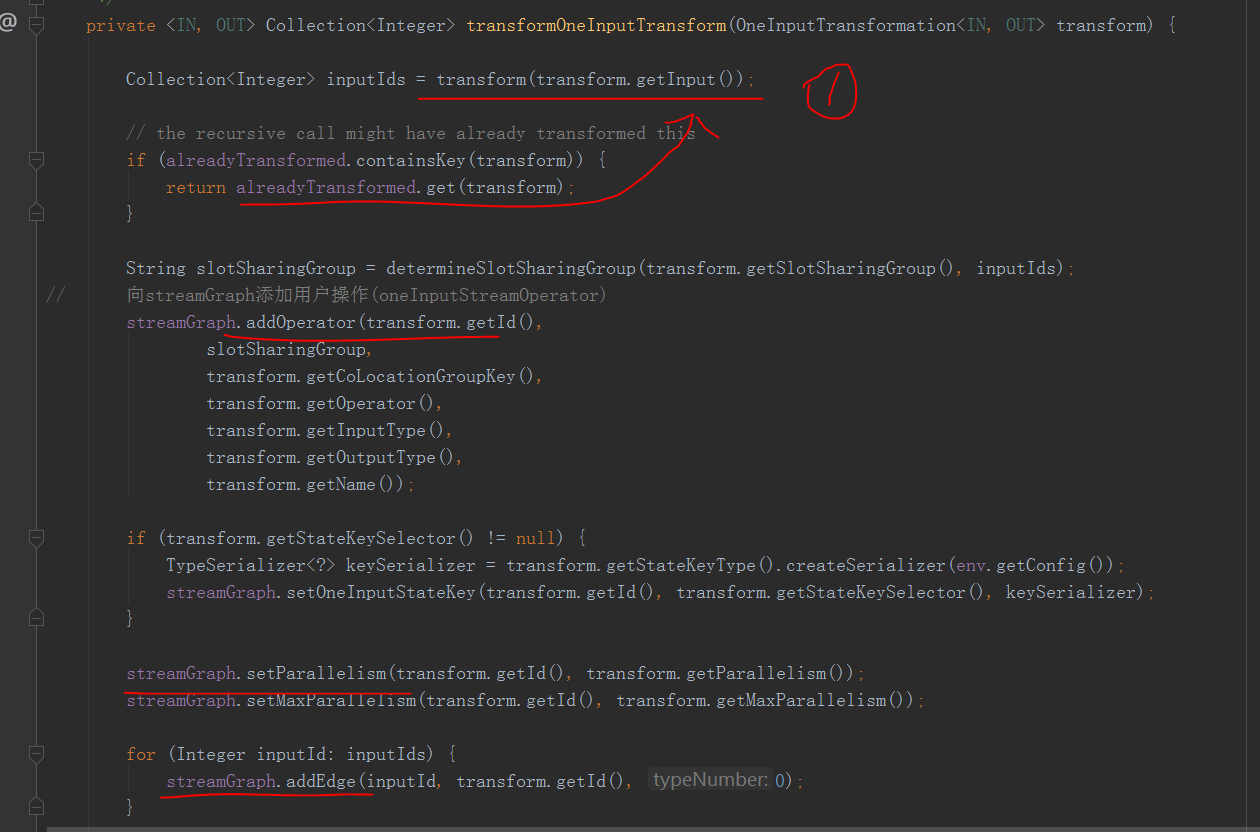
1處會遞歸遍歷input直到input已經transfor,然後拿到了上游的ids
然後將operator加入到了streamGraph中調用addNode()方法將operator作為一個node,包含了一些信息,上下游的類型,並行度,soltGroup
最後遍歷上游的ids,創建邊添加到streamGraph
到這裡streamGraph就創建完成了
回到最開始的地方,創建完streamGraph以後,會將streamGraph傳入executeRemotely(streamGraph, jarFiles)這個方法,這裡就是streamGraph轉化成jobgraph的邏輯
其中創建了一個RestClusterClient


可以看到這裡,通過getJobGraph方法將streamGraph轉換成了jobgraph
然後就submitJob將這個JobGraph提交Jobmanager了
先看一下streamGraph如何轉化成jobgraph的

通過getJobGraph方法然後


這個createJobGraph方法是主要的轉化邏輯

廣度優先遍歷為所有streamGraph的node 即operator生成hash散列值,為什麼要生成這個operator的hash?
因為這個hash需要作為每一個operator的唯一標示,標示每一個operator用於cp的恢復,當用戶代碼沒有修改時,這個hash值是不會改變的
接下來


這裡會將flink中上下游的operator操作根據是否滿足chain條件鏈在一起,在createChian中
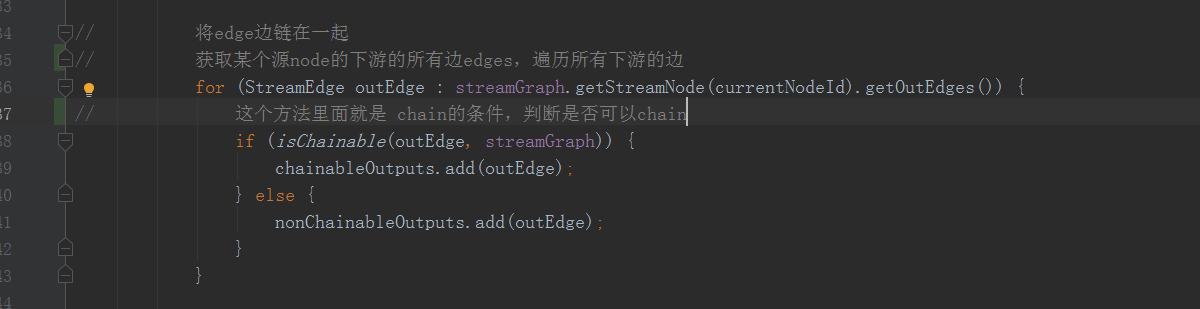
這個isChainable()方法就是是否可以chain的判斷條件

1.下游的輸入邊只有一條
2.下游操作operator不為空
3.上游操作operator不為空
4.上游必須有相同的solt組
5.下游chain策略為always
6.上游chain策略為head或上游chain策略為always
7.forwardpartition的邊
8.上下游並行度相同
9.用戶代碼設置的operator是否可以chian
將可以chain的streamnode 鏈在一起以後就可以創建成為jobGraph的jobVertex了
然後通過RestClusterClient會將這個jobGraph往jobmanager的Dispatcher對應的RPC介面上面發送
整個job的啟動Driver端的任務就結束了
總結:
在Driver端用戶的運算元會被創建成為streamGraph,其中包含了一些邊,角,上下游類型,並行度等一些信息
然後將streamGraph通過一些chain條件將可以chain的頂點chain在了一起轉化成了JobGraph
streamEdge變成了jobEdge,chain在一起的streamnode變成了jobVertex
最後然後通過RPC將整個jobGraph向jobmanager提交。


