
What/Sphinx是什麼 定義 Sphinx是一個全文檢索引擎。 特性 索引和性能優異 易於集成SQL和XML數據源,並可使用SphinxAPI、SphinxQL或者SphinxSE搜索介面 易於通過分散式搜索進行擴展 高速的索引建立(在當代CPU上,峰值性能可達到10 ~ 15MB/秒) 高性 ...
What/Sphinx是什麼
定義
Sphinx是一個全文檢索引擎。
特性
- 索引和性能優異
- 易於集成SQL和XML數據源,並可使用SphinxAPI、SphinxQL或者SphinxSE搜索介面
- 易於通過分散式搜索進行擴展
- 高速的索引建立(在當代CPU上,峰值性能可達到10 ~ 15MB/秒)
- 高性能的搜索 (在1.2G文本,100萬條文檔上進行搜索,支持高達每秒150~250次查詢)
Why/為什麼使用Sphinx
遇到的使用場景
遇到一個類似這樣的需求:用戶可以通過文章標題和文章搜索到一片文章的內容,而文章的標題和文章的內容分別保存在不同的庫,而且是跨機房的。
可選方案
A、直接在資料庫實現跨庫LIKE查詢
優點:簡單操作
缺點:效率較低,會造成較大的網路開銷
B、結合Sphinx中文分詞搜索引擎
優點:效率較高,具有較高的擴展性
缺點:不負責數據存儲
使用Sphinx搜索引擎對數據做索引,數據一次性載入進來,然後做了所以之後保存在記憶體。這樣用戶進行搜索的時候就只需要在Sphinx伺服器上檢索數據即可。而且,Sphinx沒有MySQL的伴隨機磁碟I/O的缺陷,性能更佳。
其他典型使用場景
1、快速、高效、可擴展和核心的全文檢索
- 數據量大的時候,比MyISAM和InnoDB都要快。
- 能對多個源表的混合數據創建索引,不限於單個表上的欄位。
- 能將來自多個索引的搜索結果進行整合。
- 能根據屬性上的附加條件對全文搜索進行優化。
2、高效地使用WHERE子句和LIMIT字句
當在多個WHERE條件做SELECT查詢時,索引選擇性較差或者根本沒有索引支持的欄位,性能較差。sphinx可以對關鍵字做索引。區別是,MySQL中,是內部引擎決定使用索引還是全掃描,而sphinx是讓你自己選擇使用哪一種訪問方法。因為sphinx是把數據保存到RAM中,所以sphinx不會做太多的I/O操作。而mysql有一種叫半隨機I/O磁碟讀,把記錄一行一行地讀到排序緩衝區里,然後再進行排序,最後丟棄其中的絕大多數行。所以sphinx使用了更少的記憶體和磁碟I/O。
3、優化GROUP BY查詢
在sphinx中的排序和分組都是用固定的記憶體,它的效率比類似數據集全部可以放在RAM的MySQL查詢要稍微高些。
4、並行地產生結果集
sphinx可以讓你從相同數據中同時產生幾份結果,同樣是使用固定量的記憶體。作為對比,傳統SQL方法要麼運行兩個查詢,要麼對每個搜索結果集創建一個臨時表。而sphinx用一個multi-query機制來完成這項任務。不是一個接一個地發起查詢,而是把幾個查詢做成一個批處理,然後在一個請求里提交。
5、向上擴展和向外擴展
- 向上擴展:增加CPU/內核、擴展磁碟I/O
- 向外擴展:多個機器,即分散式sphinx
6、聚合分片數據
適合用在將數據分佈在不同物理MySQL伺服器間的情況。
例子:有一個1TB大小的表,其中有10億篇文章,通過用戶ID分片到10個MySQL伺服器上,在單個用戶的查詢下當然很快,如果需要實現一個歸檔分頁功能,展示某個用戶的所有朋友發表的文章。那麼就要同事訪問多台MySQL伺服器了。這樣會很慢。而sphinx只需要創建幾個實例,在每個表裡映射出經常訪問的文章屬性,然後就可以進行分頁查詢了,總共就三行代碼的配置。
介紹了Sphinx的工作原理,關於如何安裝的文章在網上有很多,筆者就不再覆述了,現在繼續講解Sphinx的配置文件,讓Sphinx工作起來。
How/如何使用Sphinx
Sphinx工作流程圖
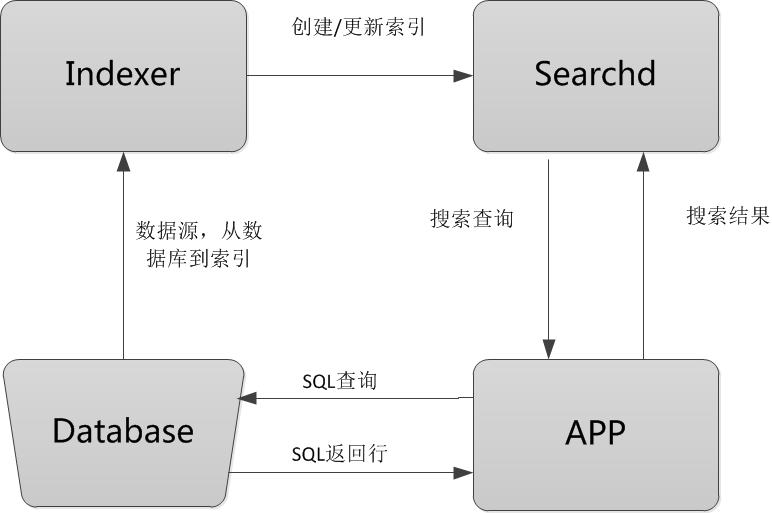
流程圖解釋
Database:數據源,是Sphinx做索引的數據來源。因為Sphinx是無關存儲引擎、資料庫的,所以數據源可以是MySQL、PostgreSQL、XML等數據。
Indexer:索引程式,從數據源中獲取數據,並將數據生成全文索引。可以根據需求,定期運行Indexer達到定時更新索引的需求。
Searchd:Searchd直接與客戶端程式進行對話,並使用Indexer程式構建好的索引來快速地處理搜索查詢。
APP:客戶端程式。接收來自用戶輸入的搜索字元串,發送查詢給Searchd程式並顯示返回結果。
Sphinx的工作原理
Sphinx的整個工作流程就是Indexer程式到資料庫裡面提取數據,對數據進行分詞,然後根據生成的分詞生成單個或多個索引,並將它們傳遞給searchd程式。然後客戶端可以通過API調用進行搜索。
介紹了Sphinx工作原理以及Sphinx的配置之後,繼續介紹在Sphinx中,負責做索引的程式Indexer是如何做索引的。
sphinx使用配置文件從資料庫讀出數據之後,就將數據傳遞給Indexer程式,然後Indexer就會逐條讀取記錄,根據分詞演算法對每條記錄建立索引,分詞演算法可以是一元分詞/mmseg分詞。下麵先介紹Indexer做索引時使用的數據結構和演算法。
數據源配置
先來看一份數據源的配置文件示例:
1 source test
2 {
3 type = mysql
4
5 sql_host = 127.0.0.1
6 sql_user = root
7 sql_pass = root
8 sql_db = test
9 sql_port = 3306 # optional, default is 3306
10
11 sql_query_pre = SET NAMES utf8
12 sql_query = SELECT id, name, add_time FROM tbl_test
13
14 sql_attr_timestamp = add_time
15
16 sql_query_info_pre = SET NAMES utf8
17 sql_query_info = SELECT * FROM tbl_test WHERE id=$id
18 }
其中
source後面跟著的是數據源的名字,後面做索引的時候會用到;
type:數據源類型,可以為MySQL,PostreSQL,Oracle等等;
sql_host、sql_user、sql_pass、sql_db、sql_port是連接資料庫的認證信息;
sql_query_pre:定義查詢時的編碼
sql_query:數據源配置核心語句,sphinx使用此語句從資料庫中拉取數據;
sql_attr_*:索引屬性,附加在每個文檔上的額外的信息(值),可以在搜索的時候用於過濾和排序。設置了屬性之後,在調用Sphinx搜索API時,Sphinx會返回已設置了的屬性;
sql_query_info_pre:設置查詢編碼,如果在命令行下調試出現問號亂碼時,可以設置此項;
sql_query_info:設置命令行下返回的信息。
索引配置
1 index test_index
2 {
3 source = test
4 path = /usr/local/coreseek/var/data/test
5 docinfo = extern
6 charset_dictpath = /usr/local/mmseg3/etc/
7 charset_type = zh_cn.utf-8
8 ngram_len = 1
9 ngram_chars = U+3000..U+2FA1F
10 }
其中
index後面跟的test_index是索引名稱
source:數據源名稱;
path:索引文件基本名,indexer程式會將這個路徑作為首碼生成出索引文件名。例如,屬性集會存在/usr/local/sphinx/data/test1.spa中,等等。
docinfo:索引文檔屬性值存儲模式;
charset_dictpath:中文分詞時啟用詞典文件的目錄,該目錄下必須要有uni.lib詞典文件存在;
charset_type:數據編碼類型;
ngram_len:分詞長度;
ngram_chars:要進行一元字元切分模式認可的有效字元集。
中文分詞核心配置
一元分詞
1 charset_type = utf8
2
3 ngram_len = 1
4
5 ngram_chars = U+3000..U+2FA1F
mmseg分詞
1 charset_type = utf8
2
3 charset_dictpath = /usr/local/mmseg3/etc/
4
5 ngram_len = 0
運行示例
資料庫數據
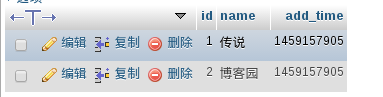
使用indexer程式做索引

查詢

可以看到,配置文件中的add_time被返回了,如上圖的1所示。而sql_query_info返回的信息如上圖的2所示。
Sphinx的配置不是很靈活,此處根據工作流程給出各部分的配置,更多的高級配置可以在使用時查閱文檔。
倒排索引
倒排索引是一種數據結構,用來存儲在全文搜索下某個單詞在一個文檔或者一組文檔中的存儲位置的映射。它是文檔檢索系統中最常用的數據結構。
倒排索引(Inverted Index):倒排索引是實現“單詞-文檔矩陣”的一種具體存儲形式,通過倒排索引,可以根據單詞快速獲取包含這個單詞的文檔列表。
傳統的索引是:索引ID->文檔內容,而倒排索引是:文檔內容(分詞)->索引ID。可以類比正向代理和反向代理的區別來理解。正向代理把內部請求代理到外部,反向代理把外部請求代理到內部。所以應該理解為轉置索引比較合適。
倒排索引主要由兩個部分組成:“單詞詞典”和“倒排文件”。
單詞詞典是倒排索引中非常重要的組成部分,它用來維護文檔集合中出現過的所有單詞的相關信息,同時用來記載某個單詞對應的倒排列表在倒排文件中的位置信息。在支持搜索時,根據用戶的查詢詞,去單詞詞典里查詢,就能夠獲得相應的倒排列表,並以此作為後續排序的基礎。
對於一個規模很大的文檔集合來說,可能包含幾十萬甚至上百萬的不同單詞,能否快速定位某個單詞直接影響搜索時的響應速度,所以需要高效的數據結構來對單詞詞典進行構建和查找,常用的數據結構包括哈希加鏈表結構和樹形詞典結構。
倒排索引基礎知識
- 文檔(Document):一般搜索引擎的處理對象是互聯網網頁,而文檔這個概念要更寬泛些,代表以文本形式存在的存儲對象,相比網頁來說,涵蓋更多種形式,比如Word,PDF,html,XML等不同格式的文件都可以稱之為文檔。再比如一封郵件,一條簡訊,一條微博也可以稱之為文檔。在本書後續內容,很多情況下會使用文檔來表徵文本信息。
- 文檔集合(Document Collection):由若幹文檔構成的集合稱之為文檔集合。比如海量的互聯網網頁或者說大量的電子郵件都是文檔集合的具體例子。
- 文檔編號(Document ID):在搜索引擎內部,會將文檔集合內每個文檔賦予一個唯一的內部編號,以此編號來作為這個文檔的唯一標識,這樣方便內部處理,每個文檔的內部編號即稱之為“文檔編號”,後文有時會用DocID來便捷地代表文檔編號。
- 單詞編號(Word ID):與文檔編號類似,搜索引擎內部以唯一的編號來表徵某個單詞,單詞編號可以作為某個單詞的唯一表徵。
Indexer程式就是根據配置好地分詞演算法,將獲取到的記錄進行分詞,然後用倒排索引做數據結構保存起來。
分詞演算法
一元分詞
一元分詞的核心配置
1 charsey_type = zh_cn.utf8 2 ngram_len = 1 3 ugram_chars = U+4E00..U+9FBF
ngram_len是分詞的長度。
ngram_chars標識要進行一元分詞切分模式的字元集。
原生的Sphinx支持的分詞演算法是一元分詞,這種分詞演算法是對記錄的每個詞切割後做索引,這種索引的優點就是覆蓋率高,保證每個記錄都能被搜索到。缺點就是會生成很大的索引文件,更新索引時會消耗很多的資源。所以,如果不是特殊需求,而且數據不是特別少的時候,都不建議使用一元分詞。
國人在sphinx的基礎上開發了支持中文分詞的Coreseek。Coreseek與Sphinx唯一的不同就是Coreseek還支持mmseg分詞演算法做中文分詞。
mmseg分詞
mmseg分詞演算法是基於統計模型的,所以演算法的規則也是來自對語料庫的分析和數學歸納,因為中文字元沒有明確的分界,會導致大量的字元分界歧義,而且,中文裡面,詞和短語也很難界定,因此,演算法除了要做統計和數學歸納之外,還要做歧義的解決。
在mmseg分詞中,有一個叫chunk的概念。
chunk,是一句話的分詞方式。包括一個詞條數組和四個規則。
如:研究生命,有“研究/生命”和“研究生/命”兩種分詞方式,這就是兩個chunk。
一個chunk有四個屬性:長度、平均長度(長度/分詞數)、方差、單字自由度(各單詞條詞頻的對數之和)。
做好分詞之後,會得到多種分詞方式,這時候就要使用一些過濾規則來完成歧義的解決,以得到最終的分詞方式。
歧義解決規則:
1、最大匹配
匹配最大長度的詞。如“國際化”,有“國際/化”、“國際化”兩種分詞方式,選擇後者。
2、最大平均詞長度
匹配平均詞最大的chunk。如“南京市長江大橋”,有“南京市/長江大橋”、“南京/市長/江大橋”三種分詞方式,前者平均詞長度是7/2=3.5,後者是7/3=2.3,故選擇前者的分詞方式。
3、最大方差
去方差最大的chunk。如“研究生命科學”,有“研究生/命/科學”、“研究/生命/科學“兩種分詞方式,而它們的詞長都一樣是2。所以需要繼續過濾,前者方差是0.82,後者方差是0。所以選擇第一種分詞方式。
4、最大單字自由度
選擇單個字出現最高頻率的chunk。比如”主要是因為“,有”主要/是/因為“,”主/要是/因為“兩種分詞方式,它們的詞長、方差都一樣,而”是“的詞頻較高,所以選擇第一種分詞方式。
如果經過上述四個規則的過濾,剩下的chunk仍然大於一,那這個演算法也無能為力了,只能自己寫擴展完成。
最後的最後
當然,有人會說資料庫的索引也可以做到sphinx索引,只是數據結構不一樣而已,但是,最大的不同是sphinx就像一張沒有任何關係查詢支持的單表資料庫。而且,索引主要用在搜索功能的實現而不是主要的數據來源。因此,你的資料庫也許是符合第三範式的,但索引會完全被非規範化而且主要包含需要被搜索的數據。
另外一點,大部分資料庫都會遭遇一個內部碎片的問題,它們需要在一個大請求里遭遇太多的半隨機I/O任務。那就是說,考慮一個在資料庫的索引中,查詢指向索引,索引指向數據,如果數據因為碎片問題被分開在不同的磁碟中,那麼此次查詢將占用很長的時間。
總結
通過一個項目的實踐,發現sphinx的使用要點主要在配置文件上,如果懂得配置了,那麼基本用法很容易掌握。如果要深入研究,比如研究其工作原理,那就得查閱更多的資料。高級特性還沒有用到,日後用到再做分享。最後,如果還想擴展sphinx,定製更強大的功能,可以直接閱讀源代碼,然後編寫擴展。使用sphinx也有弊端,如果需要保證高質量的搜索,那麼就要經常手動維護詞庫。如果不能保持經常更新詞庫,那麼可以考慮百度搜索之類的插件。如果可以加入機器學習的話,那麼會更好。
原創文章,文筆有限,才疏學淺,文中若有不正之處,萬望告知。
如果本文對你有幫助,請點下推薦,寫文章不容易。

