
雙11備戰前夕,總繞不過性能壓測環節,TPS 一直上不去 / 不達標,除了代碼上的問題外,伺服器環境、配置、網路、磁碟、CPU 亦是導致性能瓶頸的重要一環,本文旨在分享最近項目性能壓測過程中的排查經驗,文中的表單你可以作為排查手冊保存,如有不對之處,還請在評論區分享、交流你的經驗和觀點:) 通過本文 ...
雙11備戰前夕,總繞不過性能壓測環節,TPS 一直上不去 / 不達標,除了代碼上的問題外,伺服器環境、配置、網路、磁碟、CPU 亦是導致性能瓶頸的重要一環,本文旨在分享最近項目性能壓測過程中的排查經驗,文中的表單你可以作為排查手冊保存,如有不對之處,還請在評論區分享、交流你的經驗和觀點:)
原文地址(樣式排版上更好點) :https://blog.zhuliang.ltd/2019/08/server/test-with-perfmon.html
通過本文,你可以瞭解和掌握:
- 瞭解常見的系統瓶頸的可能原因。
- 通過性能探查器定位性能瓶頸。
- 幾點關於性能優化的策略。
- 一份關於 windows 性能監視器的部分計數器翻譯及對應的經驗結論。
吞吐量 和 延時的關係
關於吞吐量/吞吐率、延時,你可以通過 Jmeter中的”聚合報告“和”用表格查看報告“來獲取。
- Throughput 越大,Latency 越差:因為請求過多,系統繁忙導致響應速度降低。
- Latency 的值越小說明能支持的 Throughput 越高:Latency 數值小說明系統處理速度快,自然便可以處理更多的請求。
- Throughput "不用" 通過降低 latency 的方式來提高,排查性能問題的時候,勿在降低 Latency 值上消耗過多時間。
常見系統瓶頸:
- 類型轉換:除了裝箱拆箱外,還要著重看下 JSON 的一些轉換類庫,如 newtown,fastJson 等等,可能會引起 CPU 維持在高位。
- 非同步操作:有些非同步操作會非常影響性能,尤其是在網路較差的情況下,很可能阻塞業務。
- 如非同步下的狀態通知通常會影響性能。通常而言,非同步操作會讓”吞吐率“提升,但會犧牲 延時(latency)。
定位性能瓶頸
定位的方式不一定是程式級別的,一開始可以先從操作系統的 CPU 使用率,記憶體使用率,系統 IO 和 網路 IO,網路連接數 著手分析。
- CPU 使用率不高,但是 throughtput 和 latency 上不去: 說明程式沒有忙於計算,可能問題在 I/O 上。
- 一般 CPU 和 IO 是反著來的: CPU 沒問題,問題可能在 IO,反之亦然。
- 如果 CPU、IO、記憶體、網路帶寬使用都不高,但是系統性能上不去: 說明程式有問題,可能是為資源被鎖,存在鎖競爭關係,程式被阻塞;或者是在上下文切換等等。
- 關於 IO,要看 3 個方面:磁碟IO,網路IO 以及 記憶體換頁率。
- 程式級別的性能瓶頸定位:
- 分段註釋代碼 / 讓一些函數空轉 / 做一些硬編碼的 Mock,然後再測試下 Throughput 和 latency,看是否有好轉,如果有,說明函數是瓶頸,再進一步在這個函數體內註釋代碼,直到找到最耗性能的語句。
- 分析記憶體:需要用到的計數器:Memory 類別 和 Physical Disk 類別的計數器,步驟如下:
- 查看 Memory:Available Mbytes 指標:如果該指標的數據較小,系統可能出現了記憶體方面的問題,需要繼續下麵步驟進一步分析。
- 註意 Memory:Pages/sec、Pages Read/sec 和 Page Faults/sec 的值:操作系統會利用磁碟較好的方式提高系統可用記憶體量或者提高記憶體的使用效率。這 3 個指標直接反映了 OS 進行磁碟交換的頻度。
- Pages/sec 值 持續高於幾百,可能記憶體有問題。Pages/sec 值大不一定就表明記憶體有問題,可能是運行使用記憶體映射文件的應用導致。
- Page Faults/sec 越高說明每秒發生頁面次數越多,說明 OS 向記憶體讀取的次數越多。此時需要查看 Pages Read/sec 的計數值,該值閾值是 5,超過 5,則可以判斷存在記憶體方面的問題。
- 根據 Physical Disk 計數器的值分析性能瓶頸:需要分析 Page Reads/sec 和 %Disk Time 及 Average Disk Queue Length 的分析。如果 Pages Read/sec 很低,同時 %Disk Time 和 Average Disk Queue Length 的值很高,則可能有磁碟瓶頸。但是,如果隊列長度增加的同時 Pages Read/sec 並未降低,則是記憶體不足
- 分析處理器:
- 排查 System:%Total Processor Time 計數器的數值:該值體現的是伺服器 CPU 的整體利用率,對於多核系統而言,該值體現的是所有 CPU 的平均利用率。
- 如果該值持續超過 90%,說明整個系統面臨著處理器方面的瓶頸,需要增加處理器來提高性能。
- P.S.:多核下,如果該數據不大,但是各個 CPU 的 負載不均衡,也可以認為是 CPU 產生了瓶頸。
- 排查每個 CPU 的 Processor:%Processor Time 和 %User Time 和 %Privileged Time:
- %Processor Time 很高時,一般 CPU 都阻塞著,但是反之並不亦然。
- %User Time:非系統內核操作消耗的 CPU 時間(如調用系統本身資源--網路、IO等),若該值較大,可以考慮優化代碼、優化演算法;如果該伺服器是資料庫 Server,則該值較大的話可能是資料庫的”排序“或是”函數操作“消耗了過多的 CPU 時間,此時可考慮對 DB 進行優化。
- %Privileged Time:系統內核操作消耗的 CPU 時間
- 驗證是否系統 CPU 瓶頸:
- 查看 System:Processor Queue Length 計數器:如果該值大於 CPU 數量的總數 + 1 的時候,說明產生了處理器阻塞。
- 查看 System:Processor Queue Length 計數器:如果該值大於 CPU 數量的總數 + 1 的時候,說明產生了處理器阻塞。
- 排查 System:%Total Processor Time 計數器的數值:該值體現的是伺服器 CPU 的整體利用率,對於多核系統而言,該值體現的是所有 CPU 的平均利用率。
- 分析磁碟I/O:
- 如果計算得出每個磁碟的I/O 超過了磁碟本身的I/O能力,則可以確認磁碟是引起瓶頸的因素之一。
- 與 Processor:%Privileged Time 聯合分析:如果 Physical Disk:%Disk Time 較大,其他值比較適中,則硬碟可能是瓶頸,若幾個值都比較大,且持續超過 80%,則可能是記憶體泄漏。
- 分析 Disk sec/Transfer:一般來說,該值小於 15ms 為最佳,15~30ms 為良好,30~60ms 為可接受,超過 60ms 則需要考慮更換硬碟或者更換 raid 方式了。
- 分析進程:
- 查看 Process:%Processor Time的值:每個進程的該值反映的是進程消耗 CPU 的時間。
- 查看 Process:%Page Failures/sec 和 Memory:%Page Failures/sec 的比值,過濾出是哪個進程產生的最多的頁錯誤,一般這個進程是需要大量記憶體的進程,或者是非常活躍的進程(即在壓測情況下,就是你要壓測的進程)
- Process:%Private Bytes:該計數器指進程所占有的私有數據(單位位元組),即無法與其他進程共用的數據量,可以利用該值來判斷應用是否存在記憶體泄漏。
- 對於 IIS 進程,可以重點監控下 INetInfo進程的 Private Bytes,如果在壓測過程中,該值不斷增加,或是在壓測結束後,該值仍然處於一個高水平,則說明應用存在記憶體泄漏
- 分析網路:
- Network Interface:Bytes Total/sec 為發送和接收位元組的速率,可以通過該計數器值來判斷網路鏈接速度是否是瓶頸,具體操作方法是用該計數器的值和目前網路的帶寬進行比較。
- 聯合 Processor:%Privileged Time 進行分析:如果 Physical Disk:%Disk Time比較大,其他值比較適中,則硬碟可能是瓶頸,若幾個值都比較大,且持續超過 80%,則可能存在記憶體泄漏。
性能優化的幾個策略
- 應用層面:
- 善用 CDN,緩存,冗餘數據,SLB。
- 如果瓶頸在網路傳輸,那麼需要對傳輸數據進行壓縮(需要註意,壓縮演算法是很耗時的,只在瓶頸是網路傳輸的時候再考慮,你需要根據測試數據自行權衡。)。
- 並行處理的時候需要註意下宿主機是否是多核。如果宿主機是單核的,而程式代碼是多進程、多線程的,那麼對於高計算密集型的應用會適得其反,反而更慢。
- 優化代碼:
- 減少迴圈層數、減少遞歸。
- 在迴圈體中少做聲明變數、分配 / 釋放記憶體的操作:把迴圈體內的表達式抽離到迴圈體外。
- 註意函數調用在棧上的開銷。
- 合理使用 try-catch:不要用拋異常作為常規業務的失敗流程(如進行業務報錯)。
- 字元串處理需註意:減少不必要的聲明實例(.net core 出了一個 Span 類型,可以用來替代 Substring。)
- 不同的語言和代碼庫,對於複雜度是不一樣的,這個需要註意:如應該用 List.Count==0 來代替List.Any() 來判斷是否有數據。
- 關於這點,你可以使用計數器來判斷、測試自己寫的代碼在”耗時、Cpu Cycle,0/1/2代 GC回收“等數據的差異,擇優而定。
- 演算法調優:
- 哈希演算法並不高效,使用時候還需註意。
- 善用預處理和分量分次分批處理:像月報表之類的執行頻率低,但每次執行都很耗資源的,你可以嘗試預先每天/每周處理,不用等到每月才執行。
- 多線程調優:
- 多線程的瓶頸主要在互斥和同步鎖上,以及線程上下文切換的成本上:你應儘量少用甚至不用鎖,或者用樂觀鎖替代現有直接用 Lock 的鎖。
- 記憶體分配:當記憶體出現碎片時,會相當耗時。
- 在編碼的時候,意識上儘可能少的進行記憶體的分配。
- 池化技術對於一些短作業來說相當有效:如 HttpClientFactory 就是用了 http 池,可以用來減少對象創建、線程創建的開銷。
- 網路調優:
- TCP 很耗資源,對系統開銷很大:你可以搜索關鍵字:TCP Tuning 進行相關調優
- TCP 和 HTTP 要配置下 Keep-Alive,尤其是像 http 這樣的短連接,這也可以在一定程度上防止 DDoS攻擊。
- 對於 TCP 的 TIME_WAIT,這個狀態預設會持續 4 分鐘(持續 2 個 MSL--Max Segment Lifetime),TIME_WAIT 狀態下的資源不能回收,有大量 TIME_WAIT 連接的情況一般是在 HTTP 伺服器上。
- 你可以在註冊表中新建、設置 TCP 的 TcpTimedWaitDelay 和 MaxUserPort 項,來增加 TCP 連接釋放時間和臨時埠數。
- TCP 一旦發生丟包,TCP 的帶寬使用率會受到影響(盲目減半),再丟包,再減半;什麼時候不丟包了,就會逐步恢復。
- CPU 調優:
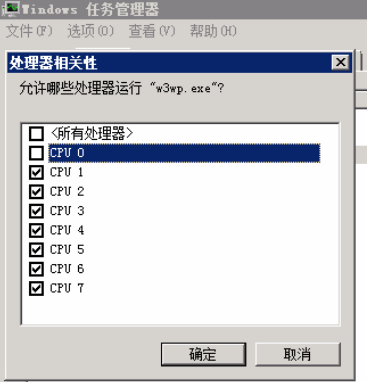
- CPU0 很關鍵, 它一般擔任著調節功能(如內核和非內核操作,上下文切換等),如果 0 號 CPU 被用得過狠的話,別的 CPU 性能也會下降。
- windows 下可在“任務管理器”中,右鍵“進程”選擇“設置相關性”來設置該進程可以運行在哪些核上。
- linux:使用 taskset 命令來設置(可以通過安裝 schedutils 來安裝這個命令) 。
- windows 下可在“任務管理器”中,右鍵“進程”選擇“設置相關性”來設置該進程可以運行在哪些核上。
- CPU0 很關鍵, 它一般擔任著調節功能(如內核和非內核操作,上下文切換等),如果 0 號 CPU 被用得過狠的話,別的 CPU 性能也會下降。
性能監視器
在伺服器上最直觀監視性能的方式就是直接使用系統自帶的”性能監視器“。
>perfmon #直接在 "運行" 中輸入 perfmon 即可打開
windows 下計數器說明:
| 類別 | 計數器名稱 | 描述 | 結論 |
|---|---|---|---|
| Memory | Available M bytes | 當前空閑物理記憶體。 | 當這個數值變小時,說明 windows 開始頻繁地調用磁碟頁面文件,如果這個數值很小(如小於 5Mb,系統會將大部分時間消耗在操作頁面文件上),一般要保留 10% 的可用記憶體,此值過小可能是記憶體不足或者記憶體泄漏。 |
| Pages/sec | 是 Pages Input/sec 和 Pages Output/sec 總和。 | Pages/sec 推薦 0-20,如果伺服器沒有足夠的記憶體處理其工作符合,此值數值將會一直很高,如果大於 80 ,表示有問題(太多的讀寫數據要訪問磁碟,可考慮增加記憶體或優化讀寫數據的演算法),該系列的值比較低,說明請求響應比較快,否則可能是伺服器記憶體短缺引起(也可能是緩存太大,導致系統記憶體太少。)一般如果Pages/sec 持續高於幾百,那麼應該進一步研究頁交換活動。有可能需要增加記憶體,以減少換頁的需求。Pages/sec 的值很大不一定表明記憶體有問題,而可能是運行使用記憶體映射文件的程式所致。計數器的比率高表示分頁過多。 | |
| Pages Read/sec | 讀取磁碟,以提取解決頁錯誤所需頁的次數。 | 其閾值為 5,該值越低越好(越低,說明響應時間越短);該值大表示磁碟讀,而非緩存讀。 如果 Page Reads/sec 持續保持為 5,表示可能記憶體不足。 | |
| Page Faults/sec | 該值表示頁錯誤的個數: 當處理器向記憶體指定位置請求一頁(可能是數據,也可能是代碼)出現錯誤時,這就構成了一個“頁錯誤”。如果該頁在記憶體的其他位置,該錯誤就被稱為軟錯誤(用 Transition Fault/sec衡量);如果該頁必須從硬碟上重新讀取時,被稱為硬錯誤。 | 許多處理器可以在有大量軟錯誤的情況下繼續操作,而硬錯誤會導致明顯的拖延。當進程使用的數據所處的記憶體頁不在記憶體中時,就會產生該值。如果某頁已經在主記憶體中,或者它正被共用此頁的其他進程使用,那麼就不會從磁碟調入該頁。 | |
| Cache Bytes | 分配在RAM中的駐留頁面數。 | 預設情況下為 50% 的可用記憶體。 | |
| Committed Bytes | 指以位元組表示的確認虛擬記憶體,是磁碟頁面文件上保留空間的物理記憶體。 | 不超過物理記憶體的 75% 。 | |
| Process | %Processor Time | 處理器消耗的處理器時間,如果專用於某種特定應用(如資料庫伺服器和應用伺服器),則可用應用相關進程 %Process Time 進行衡量。 | 可接受的上限一般不超過 85% 。 |
| Page Faults/sec | 將進程產生的頁故障與系統產生的相比較,以判斷該進程對系統頁故障產生的影響。 | ||
| Working Set | 表示進程正在使用的物理記憶體的量。(至於是具體進程還是所有進程,需要看監控實例是具體的還是所有的。) | 系統在工作集中的記憶體頁進行定址的時候,不會引發 Page Fault。另外,如果伺服器有足夠的空閑記憶體,頁就會留在工作集中,而當空閑記憶體少於一個特定的閾值時,頁就會被清除出工作集中。 | |
| Private Bytes | 此進程所分配的無法與其他進程共用的當前位元組數量。如果系統性能隨著時間而降低,則此計數器可以是記憶體泄漏的最佳指示器。 | ||
| Processor | %Processor Time | 指處理器執行非閑置線程時間的百分比。此計數器可以作為處理器活動的主要指示器。(%Processor Time = 100% - Idle Process時間比例) | 如果該值持續超過95%,表明瓶頸是 CPU,可以考慮增加或更換更快的處理器。正常情況下,保持在 80%±5% 比較好,過低說明 CPU 利用率不高,過高表示是瓶頸是 CPU。雖然該計數器高不一定是壞事,但如果其他處理器相關的計數器(如 Privileged Time 或者 Processor Queue Length)線性增加的話,高 CPU 使用率就值得調查了。 |
| %User Time | 非內核操作耗費的CPU時間。一般來說,如果系統中使用了大量的演算法或者複雜的計算操作,該值就會比較大。 | ||
| %Privileged Time | 這個計數器表示一個線程在特權模式下所使用的時間比例,當你的程式調用操作系統的方法(如文件操作,I/O 或者分配記憶體)時,這些操作系統的方法就是在特權模式下運行的。 | 如果數值持續大於 75% 就表示存在瓶頸。 | |
| %DPC Time | CPU 消耗在網路處理上的時間。 | 該值越小越好。如果持續高 %DPC 時間,則可能存在 CPU 瓶頸或應用程式或硬體相關問題。 | |
| %Interrupt Time | 表示 CPU 接收、處理硬體中斷所使用的時間比例。 | 閾值取決於處理器。一般,當該值 >15% 的時候說明可能存在硬體問題。 這個值間接指出產生中斷的硬體設備活動,比如網路變化。這個計數器顯著增加的話表示硬體可能存在問題 | |
| Interrupts/sec | 中斷率,表示每秒設備中斷 CPU 的次數,可以產生中斷的裝置包括:系統定時器,滑鼠,數據通訊聯網,網路卡以及其他外部設備等。中斷操作在後臺完成。 | 該值閾值取決於處理器,但越低越好,不宜超過 1000,如果該值顯著增加而系統活動沒有相應的增加,則表明存在硬體問題,需要檢查引起中斷的網路適配器、磁碟或其他硬體。 | |
| Physical Disk | %Disk Time | 指所選磁碟驅動器忙於讀/寫入請求所用的時間百分比。 | 正常值<10,此值過大表示耗費太多時間來訪問磁碟,可考慮增加記憶體、更換更快的硬碟、優化讀寫數據的演算法。若數值持續超過 80(此時處理器和網路並沒有飽和),則可能是記憶體泄漏。 |
| Current Disk Queue Length | 是在收集性能數據時磁碟上當前的請求數量。它還包括在收集時處於服務的請求。這是瞬態的快照,不是時間間隔的平均值。此計數器會反映暫時的高或低的隊列長度,但是如果磁碟驅動器被迫持續運行,它有可能一直處於高的狀態。 | 請求的延遲與此隊列的長度減去磁碟的軸數成正比。為了提高性能,此差應該平均小於 2。 | |
| Average Disk Queue Length | 指讀取和寫入請求的平均數。該值不應超過磁碟數的 1.5~2倍。要提高性能,可增加磁碟。註意,一個Raid Disk 實際有多個磁碟。 | 正常值應小於 5,此值持續過大表示磁碟 IO 太慢,要更換更快的硬碟。建議結合 Pages /sec 一起分析,看是記憶體分頁過多導致磁碟一直在讀寫還是就是磁碟問題。 | |
| Average Disk Read/Write Queue Length | 指讀取/寫入請求(隊列)的平均數。 | ||
| DiskRead(Writes)/sec | 物理磁碟上每秒磁碟讀、寫的次數。 | 兩者相加,應該小於磁碟設備最大容量。 | |
| Average Disk sec/Read | 指以秒計算的在磁碟上讀取數據所需的平均時間。 | ||
| Average Disk sec/Write | 指以秒計算的在磁碟上寫入數據所需的平均時間。 | ||
| Network Interface | Bytes Total/sec | 為發送和接受位元組的速率,包括幀字元在內。判斷網路連接速度是否是瓶頸,可以用該計數器的值和目前網路的帶寬比較。 | 建議不要超過帶寬的 50% 。 |
| System | %Total Processor Time | 系統上所有處理器都忙於執行非空閑線程的平均時間的百分比,該值反映了用於有用作業上的時間的比率。對單處理器系統來說,該值很容易理解;對多處理器來上,該值體現了所有處理器的平均繁忙程度。eg:如果所有處理器都繁忙,此值為 100%,如果有一半的處理器繁忙,另一半處理器完全空閑,此值為 50%。 | |
| File Data Operation/sec | 電腦對文件系統設備執行讀取和寫入操作的速率。本計數器的計數不包括文件控制文件。 | ||
| Processor Queue Length | 處理器隊列的線程數量,該計數器顯示的是等待中的線程數量,不包括正在運行的線程數量。 | 在 CPU 利用率 80~90% 的系統中,該值應為 "[1,3] * 處理器數量":如在一臺 8 核處理器,該值在 [8, 24] 區間範圍內算正常;而在 CPU 利用率較低的系統上,該值應為 [0,1],若持續大於 2,就有可能碰到了問題資源,需要進一步排查。 | |
| Call/sec | 指運行在電腦上的所有處理器調用操作系統服務例行程式的綜合速率,這些例行程式執行所有在電腦上的如安排和同步活動等基本的程式,並提供對非圖形設備、記憶體管理和名稱空間管理的訪問。 | 該值跟 Processor.Interrupts/sec 聯合使用,如果 Processor.Interrupts/sec 大於 Call/sec,則說明系統中某一硬體產生了過多的終端。 | |
| Context Switches/sec | 進程切換率,指電腦上的所有處理器全部從一個線程切換到另一個線程的綜合速率。產生上下文的可能情況:當正在運行的線程自動放棄處理器時出現上下文切換;一個有更高優先順序的線程取代一個正在運行的低優先順序線程的時候會發生上下文切換;在用戶模式和內核模式之間切換時產生上下文切換。 | 一般,該值小於 5000/秒/CPU 是不需要擔心的。如果Context 該值達到 15000/秒/CPU 的話就是一個制約因素了,需要看下是否代碼導致(如過多的非同步操作)。P.S.:上下文切換同樣會發生在許多線程擁有相同優先順序的情況,如果 CPU 使用率不高且 Context Swtich 非常低,那麼可能線程被堵塞。 | |
| Web Service | Current Connections | 當前連接數(針對到 IIS 實例)。 | 結合壓測用戶/線程數進行分析。 |
| Current Anonymous Users | 當前匿名連接數。 | 結合壓測用戶/線程數進行分析。 | |
| Current NonAnonymous Users | 當前非匿名用戶/匿名連接數。 | 結合壓測用戶/線程數進行分析。 | |
| Get/Put/Post Requests/sec | 使用Get/Put/Post 方式 HTTP 請求的速率。 |
參考
Processor queue length:https://social.msdn.microsoft.com/Forums/vstudio/en-US/356b87a3-e8b1-48ad-9355-e68ce3eef754/processor-queue-length?forum=vstest
Interrupt Time 說明:https://docs.microsoft.com/en-us/previous-versions/technet-magazine/cc718984(v=msdn.10)
性能計數器:http://www.appadmintools.com/documents/windows-performance-counters-explained/

