
在電腦編程中,排序演算法是最常用的演算法之一,本文介紹了幾種常見的排序演算法以及它們之間的差異和複雜度。 冒泡排序 冒泡排序應該是最簡單的排序演算法了,在所有講解電腦編程和數據結構的課程中,無一例外都會拿冒泡排序作為開篇來講解排序的原理。冒泡排序理解起來也很容易,就是兩個嵌套迴圈遍曆數組,對數組中的元素 ...
在電腦編程中,排序演算法是最常用的演算法之一,本文介紹了幾種常見的排序演算法以及它們之間的差異和複雜度。
冒泡排序
冒泡排序應該是最簡單的排序演算法了,在所有講解電腦編程和數據結構的課程中,無一例外都會拿冒泡排序作為開篇來講解排序的原理。冒泡排序理解起來也很容易,就是兩個嵌套迴圈遍曆數組,對數組中的元素兩兩進行比較,如果前者比後者大,則交換位置(這是針對升序排序而言,如果是降序排序,則比較的原則是前者比後者小)。我們來看下冒泡排序的實現:
function bubbleSort(array) { let length = array.length; for (let i = 0; i < length; i++) { for (let j = 0; j < length - 1; j++) { if (array[j] > array[j + 1]) { [array[j], array[j + 1]] = [array[j + 1], array[j]]; } } } }
上面這段代碼就是經典的冒泡排序演算法(升序排序),只不過交換兩個元素位置的部分我們沒有用傳統的寫法(傳統寫法需要引入一個臨時變數,用來交換兩個變數的值),這裡使用了ES6的新功能,我們可以使用這種語法結構很方便地實現兩個變數值的交換。來看下對應的測試結果:
let array = []; for (let i = 5; i > 0; i--) { array.push(i); } console.log(array.toString()); // 5,4,3,2,1 bubbleSort(array); console.log(array.toString()); // 1,2,3,4,5
在冒泡排序中,對於內層的迴圈而言,每一次都是把這一輪中的最大值放到最後(相對於升序排序),它的過程是這樣的:第一次內層迴圈,找出數組中的最大值排到數組的最後;第二次內層迴圈,找出數組中的次大值排到數組的倒數第二位;第三次內層迴圈,找出數組中的第三大值排到數組的倒數第三位......以此類推。所以,對於內層迴圈,我們可以不用每一次都遍歷到length - 1的位置,而只需要遍歷到length - 1 - i的位置就可以了,這樣可以減少內層迴圈遍歷的次數。下麵是改進後的冒泡排序演算法:
function bubbleSortImproved(array) { let length = array.length; for (let i = 0; i < length; i++) { for (let j = 0; j < length - 1 - i; j++) { if (array[j] > array[j + 1]) { [array[j], array[j + 1]] = [array[j + 1], array[j]]; } } } }
運行測試,結果和前面的bubbleSort()方法得到的結果是相同的。
let array = []; for (let i = 5; i > 0; i--) { array.push(i); } console.log(array.toString()); // 5,4,3,2,1 bubbleSortImproved(array); console.log(array.toString()); // 1,2,3,4,5
在實際應用中,我們並不推薦使用冒泡排序演算法,儘管它是最直觀的用來講解排序過程的演算法。冒泡排序演算法的複雜度為O(n2)。
選擇排序
選擇排序與冒泡排序很類似,它也需要兩個嵌套的迴圈來遍曆數組,只不過在每一次迴圈中要找出最小的元素(這是針對升序排序而言,如果是降序排序,則需要找出最大的元素)。第一次遍歷找出最小的元素排在第一位,第二次遍歷找出次小的元素排在第二位,以此類推。我們來看下選擇排序的的實現:
function selectionSort(array) { let length = array.length; let min; for (let i = 0; i < length - 1; i++) { min = i; for (let j = i; j < length; j++) { if (array[min] > array[j]) { min = j; } } if (i !== min) { [array[i], array[min]] = [array[min], array[i]]; } } }
上面這段代碼是升序選擇排序,它的執行過程是這樣的,首先將第一個元素作為最小元素min,然後在內層迴圈中遍曆數組的每一個元素,如果有元素的值比min小,就將該元素的值賦值給min。內層遍歷完成後,如果數組的第一個元素和min不相同,則將它們交換一下位置。然後再將第二個元素作為最小元素min,重覆前面的過程。直到數組的每一個元素都比較完畢。下麵是測試結果:
let array = []; for (let i = 5; i > 0; i--) { array.push(i); } console.log(array.toString()); // 5,4,3,2,1 selectionSort(array); console.log(array.toString()); // 1,2,3,4,5
選擇排序演算法的複雜度與冒泡排序一樣,也是O(n2)。
插入排序
插入排序與前兩個排序演算法的思路不太一樣,為了便於理解,我們以[ 5, 4, 3, 2, 1 ]這個數組為例,用下圖來說明插入排序的整個執行過程:
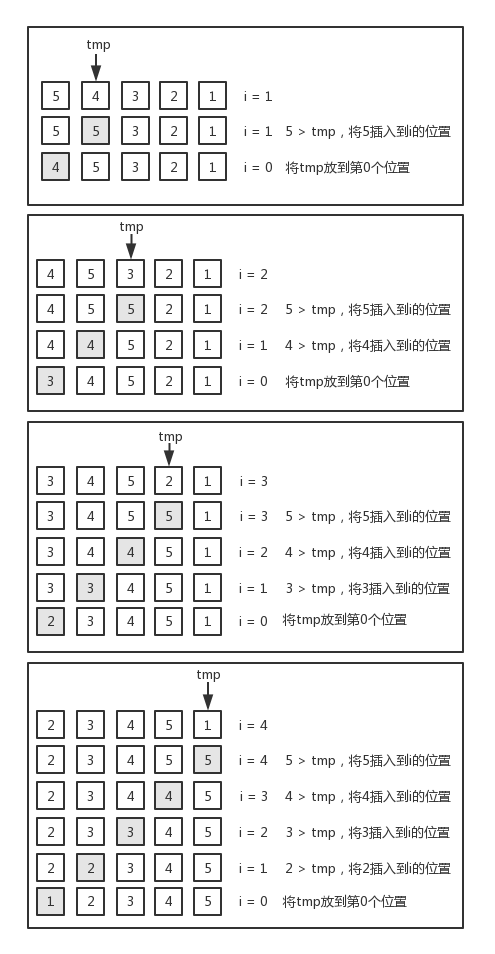
在插入排序中,對數組的遍歷是從第二個元素開始的,tmp是個臨時變數,用來保存當前位置的元素。然後從當前位置開始,取前一個位置的元素與tmp進行比較,如果值大於tmp(針對升序排序而言),則將這個元素的值插入到這個位置中,最後將tmp放到數組的第一個位置(索引號為0)。反覆執行這個過程,直到數組元素遍歷完畢。下麵是插入排序演算法的實現:
function insertionSort(array) { let length = array.length; let j, tmp; for (let i = 1; i < length; i++) { j = i; tmp = array[i]; while (j > 0 && array[j - 1] > tmp) { array[j] = array[j - 1]; j--; } array[j] = tmp; } }
對應的測試結果:
let array = []; for (let i = 5; i > 0; i--) { array.push(i); } console.log(array.toString()); // 5,4,3,2,1 insertionSort(array); console.log(array.toString()); // 1,2,3,4,5
插入排序比冒泡排序和選擇排序演算法的性能要好。
歸併排序
歸併排序比前面介紹的幾種排序演算法性能都要好,它的複雜度為O(nlogn)。
歸併排序的基本思路是通過遞歸調用將給定的數組不斷分割成最小的兩部分(每一部分只有一個元素),對這兩部分進行排序,然後向上合併成一個大數組。我們還是以[ 5, 4, 3, 2, 1 ]這個數組為例,來看下歸併排序的整個執行過程:
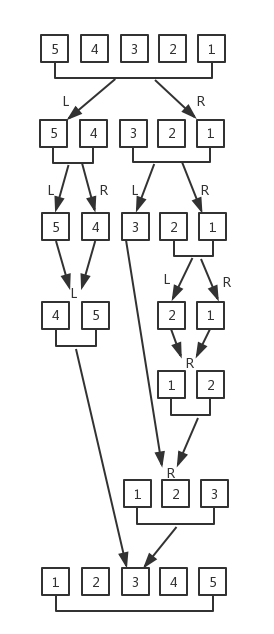
首先要將數組分成兩個部分,對於非偶數長度的數組,你可以自行決定將多的分到左邊或者右邊。然後按照這種方式進行遞歸,直到數組的左右兩部分都只有一個元素。對這兩部分進行排序,遞歸向上返回的過程中將其組成和一個完整的數組。下麵是歸併排序的演算法的實現:
const merge = (left, right) => { let i = 0; let j = 0; const result = []; // 通過這個while迴圈將left和right中較小的部分放到result中 while (i < left.length && j < right.length) { if (left[i] < right[i]) result.push(left[i++]); else result.push(right[j++]); } // 然後將組合left或right中的剩餘部分 return result.concat(i < left.length ? left.slice(i) : right.slice(j)); }; function mergeSort(array) { let length = array.length; if (length > 1) { const middle = Math.floor(length / 2); // 找出array的中間位置 const left = mergeSort(array.slice(0, middle)); // 遞歸找出最小left const right = mergeSort(array.slice(middle, length)); // 遞歸找出最小right array = merge(left, right); // 將left和right進行排序 } return array; }
主函數mergeSort()通過遞歸調用本身得到left和right的最小單元,這裡我們使用Math.floor(length / 2)將數組中較少的部分放到left中,將數組中較多的部分放到right中,你可以使用Math.ceil(length / 2)實現相反的效果。然後調用merge()函數對這兩部分進行排序與合併。註意在merge()函數中,while迴圈部分的作用是將left和right中較小的部分存入result數組(針對升序排序而言),語句result.concat(i < left.length ? left.slice(i) : right.slice(j))的作用則是將left和right中剩餘的部分加到result數組中。考慮到遞歸調用,只要最小部分已經排好序了,那麼在遞歸返回的過程中只需要把left和right這兩部分的順序組合正確就能完成對整個數組的排序。
對應的測試結果:
let array = []; for (let i = 5; i > 0; i--) { array.push(i); } console.log(array.toString()); // 5,4,3,2,1 console.log(mergeSort(array).toString()); // 1,2,3,4,5
快速排序
快速排序的複雜度也是O(nlogn),但它的性能要優於其它排序演算法。快速排序與歸併排序類似,其基本思路也是將一個大數組分為較小的數組,但它不像歸併排序一樣將它們分割開。快速排序演算法比較複雜,大致過程為:
- 從給定的數組中選取一個參考元素。參考元素可以是任意元素,也可以是數組的第一個元素,我們這裡選取中間位置的元素(如果數組長度為偶數,則向下取一個位置),這樣在大多數情況下可以提高效率。
- 創建兩個指針,一個指向數組的最左邊,一個指向數組的最右邊。移動左指針直到找到比參考元素大的元素,移動右指針直到找到比參考元素小的元素,然後交換左右指針對應的元素。重覆這個過程,直到左指針超過右指針(即左指針的索引號大於右指針的索引號)。通過這一操作,比參考元素小的元素都排在參考元素之前,比參考元素大的元素都排在參考元素之後(針對升序排序而言)。
- 以參考元素為分隔點,對左右兩個較小的數組重覆上述過程,直到整個數組完成排序。
下麵是快速排序演算法的實現:
const partition = (array, left, right) => { const pivot = array[Math.floor((right + left) / 2)]; let i = left; let j = right; while (i <= j) { while (array[i] < pivot) { i++; } while (array[j] > pivot) { j--; } if (i <= j) { [array[i], array[j]] = [array[j], array[i]]; i++; j--; } } return i; }; const quick = (array, left, right) => { let length = array.length; let index; if (length > 1) { index = partition(array, left, right); if (left < index - 1) { quick(array, left, index - 1); } if (index < right) { quick(array, index, right); } } return array; }; function quickSort(array) { return quick(array, 0, array.length - 1); }
假定數組為[ 3, 5, 1, 6, 4, 7, 2 ],按照上面的代碼邏輯,整個排序的過程如下圖所示:

下麵是測試結果:
let array = [3, 5, 1, 6, 4, 7, 2]; console.log(array.toString()); // 3,5,1,6,4,7,2 console.log(quickSort(array).toString()); // 1,2,3,4,5,6,7
快速排序演算法理解起來有些難度,可以按照上面給出的示意圖逐步推導一遍,以幫助理解整個演算法的實現原理。
堆排序
在電腦科學中,堆是一種特殊的數據結構,它通常用樹來表示數組。堆有以下特點:
- 堆是一棵完全二叉樹
- 子節點的值不大於父節點的值(最大堆),或者子節點的值不小於父節點的值(最小堆)
- 根節點的索引號為0
- 子節點的索引為父節點索引 × 2 + 1
- 右子節點的索引為父節點索引 × 2 + 2
堆排序是一種比較高效的排序演算法。
在堆排序中,我們並不需要將數組元素插入到堆中,而只是通過交換來形成堆,以數組[ 3, 5, 1, 6, 4, 7, 2 ]為例,我們用下圖來表示其初始狀態:
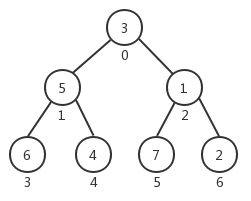
那麼,如何將其轉換成一個符合標準的堆結構呢?先來看看堆排序演算法的實現:
const heapify = (array, heapSize, index) => { let largest = index; const left = index * 2 + 1; const right = index * 2 + 2; if (left < heapSize && array[left] > array[index]) { largest = left; } if (right < heapSize && array[right] > array[largest]) { largest = right; } if (largest !== index) { [array[index], array[largest]] = [array[largest], array[index]]; heapify(array, heapSize, largest); } }; const buildHeap = (array) => { let heapSize = array.length; for (let i = heapSize; i >= 0; i--) { heapify(array, heapSize, i); } }; function heapSort(array) { let heapSize = array.length; buildHeap(array); while (heapSize > 1) { heapSize--; [array[0], array[heapSize]] = [array[heapSize], array[0]]; heapify(array, heapSize, 0); } return array; }
函數buildHeap()將給定的數組轉換成堆(按最大堆處理)。下麵是將數組[ 3, 5, 1, 6, 4, 7, 2 ]轉換成堆的過程示意圖:
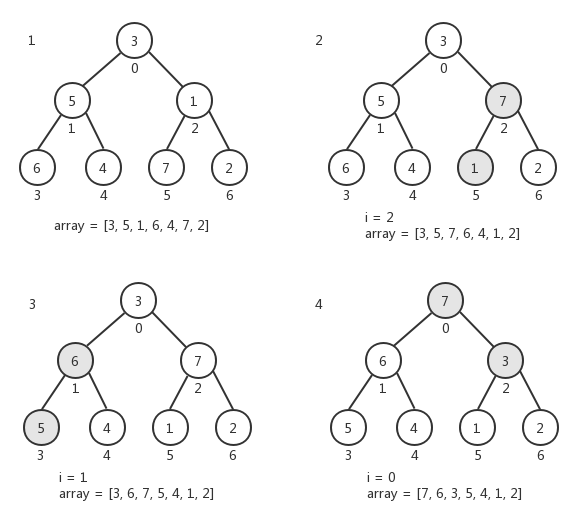
在函數buildHeap()中,我們從數組的尾部開始遍歷去查看每個節點是否符合堆的特點。在遍歷的過程中,我們發現當索引號為6、5、4、3時,其左右子節點的索引大小都超出了數組的長度,這意味著它們都是葉子節點。那麼我們真正要做的就是從索引號為2的節點開始。其實從這一點考慮,結合我們利用完全二叉樹來表示數組的特性,可以對buildHeap()函數進行優化,將其中的for迴圈修改為下麵這樣,以去掉對子節點的操作。
for (let i = Math.floor(heapSize / 2) - 1; i >= 0; i--) { heapify(array, heapSize, i); }
從索引2開始,我們查看它的左右子節點的值是否大於自己,如果是,則將其中最大的那個值與自己交換,然後向下遞歸查找是否還需要對子節點繼續進行操作。索引2處理完之後再處理索引1,然後是索引0,最終轉換出來的堆如圖中的4所示。你會發現,每一次堆轉換完成之後,排在數組第一個位置的就是堆的根節點,也就是數組的最大元素。根據這一特點,我們可以很方便地對堆進行排序,其過程是:
- 將數組的第一個元素和最後一個元素交換
- 減少數組的長度,從索引0開始重新轉換堆
直到整個過程結束。對應的示意圖如下:
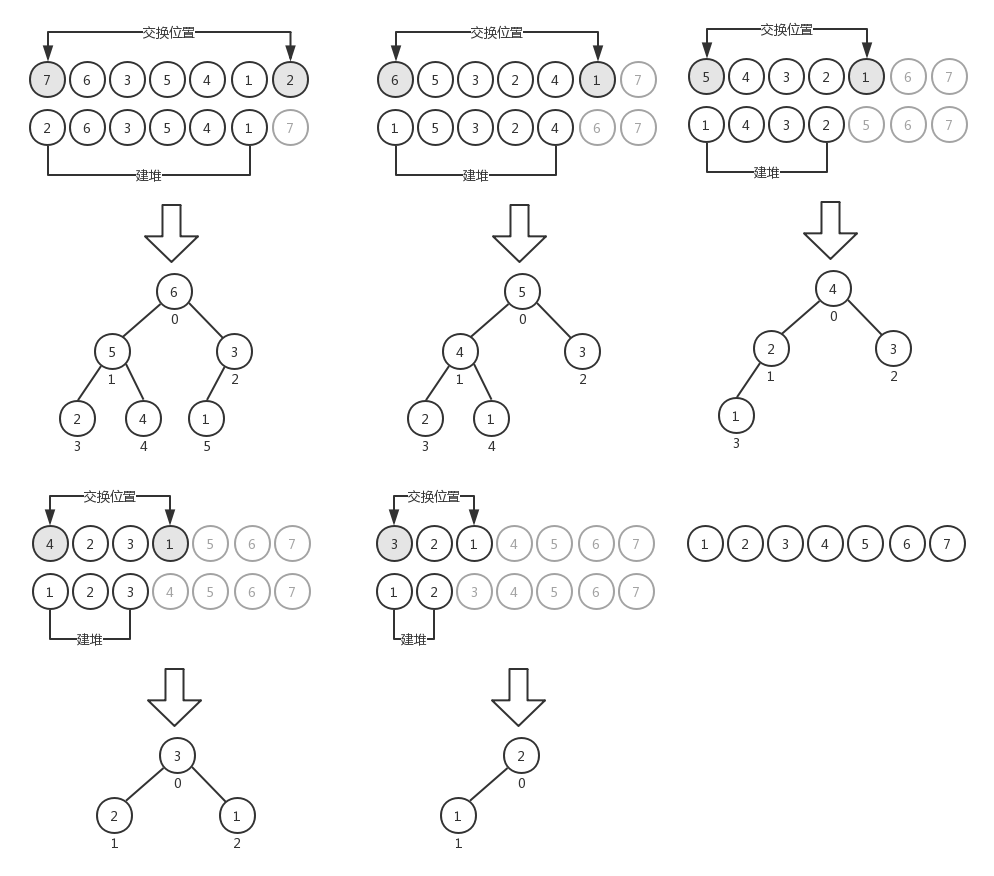
堆排序的核心部分在於如何將數組轉換成堆,也就是上面代碼中buildHeap()和heapify()函數部分。
同樣給出堆排序的測試結果:
let array = [3, 5, 1, 6, 4, 7, 2]; console.log(array.toString()); // 3,5,1,6,4,7,2 console.log(heapSort(array).toString()); // 1,2,3,4,5,6,7
有關演算法複雜度
上面我們在介紹各種排序演算法的時候,提到了演算法的複雜度,演算法複雜度用大O表示法,它是用大O表示的一個函數,如:
- O(1):常數
- O(log(n)):對數
- O(log(n) c):對數多項式
- O(n):線性
- O(n2):二次
- O(nc):多項式
- O(cn):指數
我們如何理解大O表示法呢?看一個例子:
function increment(num) { return ++num; }
對於函數increment(),無論我傳入的參數num的值是什麼數字,它的運行時間都是X(相對於同一臺機器而言)。函數increment()的性能與參數無關,因此我們可以說它的演算法複雜度是O(1)(常數)。
再看一個例子:
function sequentialSearch(array, item) { for (let i = 0; i < array.length; i++) { if (item === array[i]) return i; } return -1; }
函數sequentialSearch()的作用是在數組中搜索給定的值,並返回對應的索引號。假設array有10個元素,如果要搜索的元素排在第一個,我們說開銷為1。如果要搜索的元素排在最後一個,則開銷為10。當數組有1000個元素時,搜索最後一個元素的開銷是1000。所以,sequentialSearch()函數的總開銷取決於數組元素的個數和要搜索的值。在最壞情況下,沒有找到要搜索的元素,那麼總開銷就是數組的長度。因此我們得出sequentialSearch()函數的時間複雜度是O(n),n是數組的長度。
同理,對於前面我們說的冒泡排序演算法,裡面有一個雙層嵌套的for迴圈,因此它的複雜度為O(n2)。
時間複雜度O(n)的代碼只有一層迴圈,而O(n2)的代碼有雙層嵌套迴圈。如果演算法有三層嵌套迴圈,它的時間複雜度就是O(n3)。
下表展示了各種不同數據結構的時間複雜度:
| 數據結構 | 一般情況 | 最差情況 | ||||
| 插入 | 刪除 | 搜索 | 插入 | 刪除 | 搜索 | |
| 數組/棧/隊列 | O(1) | O(1) | O(n) | O(1) | O(1) | O(n) |
| 鏈表 | O(1) | O(1) | O(n) | O(1) | O(1) | O(n) |
| 雙向鏈表 | O(1) | O(1) | O(n) | O(1) | O(1) | O(n) |
| 散列表 | O(1) | O(1) | O(1) | O(n) | O(n) | O(n) |
| BST樹 | O(log(n)) | O(log(n)) | O(log(n)) | O(n) | O(n) | O(n) |
| AVL樹 | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) |
數據結構的時間複雜度
| 節點/邊的管理方式 | 存儲空間 | 增加頂點 | 增加邊 | 刪除頂點 | 刪除邊 | 輪詢 |
| 領接表 | O(| V | + | E |) | O(1) | O(1) | O(| V | + | E |) | O(| E |) | O(| V |) |
| 鄰接矩陣 | O(| V |2) | O(| V |2) | O(1) | O(| V |2) | O(1) | O(1) |
圖的時間複雜度
| 演算法(用於數組) | 時間複雜度 | ||
| 最好情況 | 一般情況 | 最差情況 | |
| 冒泡排序 | O(n) | O(n2) | O(n3) |
| 選擇排序 | O(n2) | O(n2) | O(n2) |
| 插入排序 | O(n) | O(n2) | O(n2) |
| 歸併排序 | O(log(n)) | O(log(n)) | O(log(n)) |
| 快速排序 | O(log(n)) | O(log(n)) | O(n2) |
| 堆排序 | O(log(n)) | O(log(n)) | O(log(n)) |
排序演算法的時間複雜度
搜索演算法
順序搜索是一種比較直觀的搜索演算法,上面介紹演算法複雜度一小節中的sequentialSearch()函數就是順序搜索演算法,就是按順序對數組中的元素逐一比較,直到找到匹配的元素。順序搜索演算法的效率比較低。
還有一種常見的搜索演算法是二分搜索演算法。它的執行過程是:
- 將待搜索數組排序。
- 選擇數組的中間值。
- 如果中間值正好是要搜索的值,則完成搜索。
- 如果要搜索的值比中間值小,則選擇中間值左邊的部分,重新執行步驟2。
- 如果要搜索的值比中間值大,則選擇中間值右邊的部分,重新執行步驟2。
下麵是二分搜索演算法的具體實現:
function binarySearch(array, item) { quickSort(array); // 首先用快速排序法對array進行排序 let low = 0; let high = array.length - 1; while (low <= high) { const mid = Math.floor((low + high) / 2); // 選取中間位置的元素 const element = array[mid]; // 待搜索的值大於中間值 if (element < item) low = mid + 1; // 待搜索的值小於中間值 else if (element > item) high = mid - 1; // 待搜索的值就是中間值 else return true; } return false; }
對應的測試結果:
const array = [8, 7, 6, 5, 4, 3, 2, 1]; console.log(binarySearch(array, 2)); // true
這個演算法的基本思路有點類似於猜數字大小,每當你說出一個數字,我都會告訴你是大了還是小了,經過幾輪之後,你就可以很準確地確定數字的大小了。


