
昨天花了一下午寫了一個小爬蟲,用來分析自己的粉絲數據。這個真好玩!今天幫了群里好多大V也爬了他們的數據。運行速度:每分鐘5千粉絲以上。暫時先寫成這樣,這兩天要準備補考,沒有時間繼續玩這個。 下次要改進的地方:1、多線程 2、scrapy 3、深度數據 4、分散式爬蟲 希望實現的功能: + 1、地區、 ...
昨天花了一下午寫了一個小爬蟲,用來分析自己的粉絲數據。這個真好玩!今天幫了群里好多大V也爬了他們的數據。運行速度:每分鐘5千粉絲以上。暫時先寫成這樣,這兩天要準備補考,沒有時間繼續玩這個。
下次要改進的地方:1、多線程 2、scrapy 3、深度數據 4、分散式爬蟲
希望實現的功能:
- 1、地區、教育程度、註冊時間、送粉識別、顏值檢測
- 2、導出 h5超秀的界面 和完美的 xlsx 數據
- 3、對內容提出建議
- 4、對接微信後臺實現自動化
下麵是源碼,經2019年8月21日測試可用:
from selenium.webdriver import Chrome,ChromeOptions
from requests.cookies import RequestsCookieJar
from lxml import etree
from pandas import DataFrame
import json,time,requests,re,os,clipboard
def sele_input_zhihu():
'首次登陸知乎,需要輸入賬號密碼'
# 防止檢測
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
driver = Chrome(options=option)
# 登錄
driver.get("http://www.zhihu.com/")
name=input("請輸入手機號或郵箱:")
pwd=input("請輸入密碼:")
needPass=driver.find_element_by_xpath("//div[@class='SignFlow-tab']")
needPass.click()
driver.find_element_by_name("username").send_keys(name)
driver.find_element_by_name("password").send_keys(pwd)
submitBtn = driver.find_element_by_xpath("//button[@type='submit']")
submitBtn.click()
time.sleep(5)
# 保存cookies
cookies = driver.get_cookies()
with open("cookies.json", "w") as fp:
json.dump(cookies, fp)
print("保存cookies成功!")
driver.close()
def login_zhihu(s):
'利用保存的cookies登錄知乎'
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36'
}
s.headers=headers
cookies_jar = RequestsCookieJar()
with open("cookies.json","r")as fp:
cookies = json.load(fp)
for cookie in cookies:
cookies_jar.set(cookie['name'], cookie['value'])
s.cookies.update(cookies_jar)
print("登錄成功!")
# 淺數據處理
# "users":{(.*), "questions":{}
def parse_infos(session,url,id):
content = session.get(url).text
info_json=re.search(r'"users":(.*}}),"questions":{}',content).group(1)
json_dict=json.loads(info_json)
items=[]
for key in json_dict.keys():
item = json_dict[key]
if "name" in item.keys() and key!=id:
custom = "是" if(item["useDefaultAvatar"]==False) else "否"
thetype="普通用戶" if(item["isOrg"]==False) else "機構號"
gender="女" if(item["gender"]==0) else ("男" if (item["gender"]==1)else "未知")
vip="否"if(item["vipInfo"]["isVip"]==False) else "是"
items.append([item["urlToken"] , item["name"] , custom , item["avatarUrl"], item["url"] , thetype , item["headline"] , gender , vip , item["followerCount"] , item["answerCount"] , item["articlesCount"]])
return items
def main():
# 登錄
if not os.path.exists("cookies.json"):
print("未登錄賬戶,請登錄!")
sele_input_zhihu()
session=requests.session()
login_zhihu(session)
# 需要的數據
zhuye_url="https://www.zhihu.com/people/you-yi-shi-de-hu-xi/activities" # 這個地方用來輸入主頁鏈接
zhuye=re.match(r"(.*)/activities$",zhuye_url).group(1)
id = re.match(r".*/(.*)$",zhuye).group(1)
followers_url=zhuye+r"/followers?page={}"
# 分析粉絲個數和頁碼
html = etree.HTML(session.get(zhuye_url).text)
text=html.xpath("//div[@class='NumberBoard FollowshipCard-counts NumberBoard--divider']//strong/text()")[1]
follows = int("".join(text.split(",")))
pages = follows//20+1
print("關註者 "+str(follows)+"人,共 "+str(pages)+"頁數據!")
# 獲取導出淺數據
all_info = []
for i in range(1,pages+1):
infos_url = followers_url.format(i)
print("正在獲取第 "+str(i)+" 頁數據...")
array = parse_infos(session,infos_url,id)
all_info+=array
many=len(all_info)
print("數據獲取完成,共"+ str(many)+" 條數據!")
data = DataFrame(data=all_info,columns=["id", "用戶名", "自定義頭像", "頭像url", "主頁鏈接", "類型", "一句話描述", "性別", "鹽選會員", "粉絲總數", "回答數", "文章數"])
data.to_csv(id+"_淺數據.csv",encoding="utf-8-sig")
print("數據已導出到"+ id+"_淺數據.csv!")
# 生成粉絲數據報告
wood=org=female=money=male=f2k=f5k=f10k=gfemale=gmale=0
for info in all_info:
if info[2]=="否" and info[9]==0 and info[10]<=2 and info[11]<=2: wood+=1
if info[5]=="機構號": org+=1
if info[7]=="女":
female+=1
if info[9]>=20: gfemale+=1
else:
if info[9]>=50: gmale+=1
if info[7]=="男": male+=1
if info[8]=="是": money+=1
if info[9]>=10000: f10k+=1
elif info[9]>=5000: f5k+=1
elif info[9]>=2000: f2k+=1
report="*"*40+"\n淺粉絲數據快覽:在你所有 "+str(many)+" 個粉絲中:\n"+"共有僵屍粉 "+str(wood)+" 個,占比 "+"{:.4%}".format(wood/many)+" ,這可是相當"+(" 低 " if (wood/many)<0.2 else " 高 ")+"的比例。\n"+"另外,粉絲的男女比例為 1 : "+"{:.3}".format(female/male)+" ,看來你深受廣大"+(" 女 " if (female>=male) else " 男 ")+"性同胞的喜愛!\n"+"靚女"+str(gfemale)+"人,靚仔"+str(gmale)+"人 【只統計有顏值的】\n"+"在你的所有粉絲里,氪金學習的用戶有 "+str(money)+" 個,占比 "+"{:.3%}".format(money/many)+",看來您的粉絲多為"+("高"if(money/many>0.045) else" 低 ")+"收入用戶!\n"+" ◉ 粉絲10K+有 "+str(f10k)+" 人;\n"+" ◉ 粉絲5K-10K有 "+str(f5k)+" 人;\n"+" ◉ 粉絲2K-5K有 "+str(f2k)+" 人;\n"
if org>=1:
report+="除此之外,你的粉絲中還有 "+str(org)+" 位機構號!詳細的報告快去 淺數據.csv 里看看吧!\n"
clipboard.copy(report)
print(report)
if __name__=="__main__":
main()運行截圖:

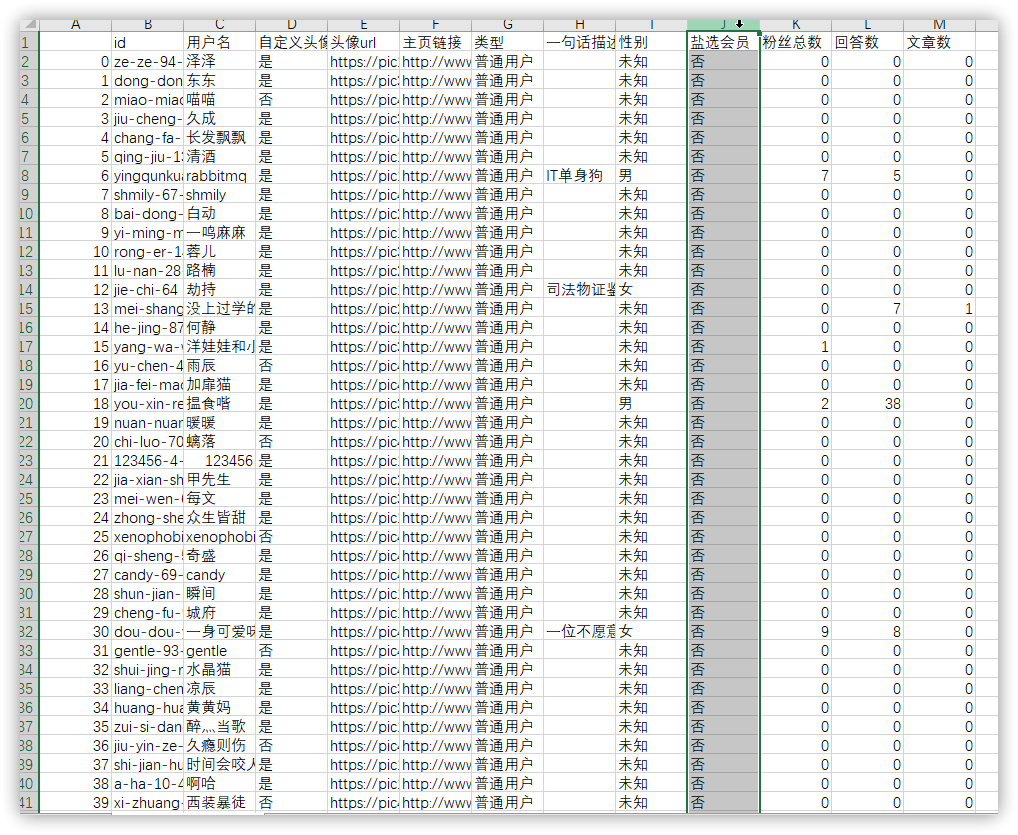
這是我今天的粉絲報告:
淺粉絲數據快覽:在你所有 9934 個粉絲中:
共有僵屍粉 2091 個,占比 21.0489% ,這可是相當 高 的比例。
另外,粉絲的男女比例為 1 : 0.352 ,看來你深受廣大 男 性同胞的喜愛!
靚女123人,靚仔354人 【只統計有顏值的】
在你的所有粉絲里,氪金學習的用戶有 477 個,占比 4.802%,看來您的粉絲多為高收入用戶!
◉ 粉絲10K+有 11 人;
◉ 粉絲5K-10K有 7 人;
◉ 粉絲2K-5K有 17 人;
除此之外,你的粉絲中還有 1 位機構號!詳細的報告快去 淺數據.csv 里看看吧!


