
本文所羅列的要領會比你們網上搜尋到的都多,如果你在看完本篇文章之後,在面試的時候遇到相關問題,相信你一定能讓面試官眼前一亮。 ...
很多粉絲私信問我Kafka在性能優化方面做了哪些舉措,對於相關問題的答案其實我早就寫過了,就是沒有系統的整理一篇,最近思考著花點時間來整理一下,下次再有粉絲問我相關的問題我就可以瀟灑的甩個鏈接了。這個問題也是Kafka面試的時候的常見問題,面試官問你這個問題也不算刁難你。在網上也有很多相關的文章開講解這個問題,比如之前各大公眾號轉載的“為什麼Kafka這麼快?”,這些文章我看了,寫的不錯,問題在於只是羅列了部分的要領,沒有全部的詳述出來。本文所羅列的要領會比你們網上搜尋到的都多,如果你在看完本篇文章之後,在面試的時候遇到相關問題,相信你一定能讓面試官眼前一亮。
批量處理
傳統消息中間件的消息發送和消費整體上是針對單條的。對於生產者而言,它先發一條消息,然後broker返回ACK表示已接收,這裡產生2次rpc;對於消費者而言,它先請求接受消息,然後broker返回消息,最後發送ACK表示已消費,這裡產生了3次rpc(有些消息中間件會優化一下,broker返回的時候返回多條消息)。而Kafka採用了批量處理:生產者聚合了一批消息,然後再做2次rpc將消息存入broker,這原本是需要很多次的rpc才能完成的操作。假設需要發送1000條消息,每條消息大小1KB,那麼傳統的消息中間件需要2000次rpc,而Kafka可能會把這1000條消息包裝成1個1MB的消息,採用2次rpc就完成了任務。這一改進舉措一度被認為是一種“作弊”的行為,然而在微批次理念盛行的今日,其它消息中間件也開始紛紛效仿。
客戶端優化
這裡接著批量處理的概念繼續來說,新版生產者客戶端摒棄了以往的單線程,而採用了雙線程:主線程和Sender線程。主線程負責將消息置入客戶端緩存,Sender線程負責從緩存中發送消息,而這個緩存會聚合多個消息為一個批次。有些消息中間件會把消息直接扔到broker。
日誌格式
Kafka從0.8版本開始日誌格式歷經了三次變革:v0、v1、v2,Kafka的日誌格式越來越利於批量消息的處理。
日誌編碼
如果瞭解了Kafka具體的日誌格式(可以參考上圖),那麼你應該瞭解日誌(Record,或者稱之為消息)本身除了基本的key和value之外,還有一些其它的欄位,原本這些附加欄位按照固定的大小占用一定的篇幅(參考上圖左),而Kafka最新的版本中採用了變成欄位Varints和ZigZag編碼,有效地降低了這些附加欄位的占用大小。日誌(消息)儘可能變小了,那麼網路傳輸的效率也會變高,日誌存檔的效率也會提升,從而整理的性能也會有所提升。
消息壓縮
Kafka支持多種消息壓縮方式(gzip、snappy、lz4)。對消息進行壓縮可以極大地減少網路傳輸 量、降低網路 I/O,從而提高整體的性能。消息壓縮是一種使用時間換空間的優化方式,如果對 時延有一定的要求,則不推薦對消息進行壓縮。
建立索引,方便快速定位查詢
每個日誌分段文件對應了兩個索引文件,主要用來提高查找消息的效率,這也是提升性能的一種方式。(具體的內容在書中的第5章有詳細的講解,公眾號里好像忘記發表了,找了一圈沒找到)
分區
很多人會忽略掉這個因素,其實分區也是提升性能的一種非常有效的方式,這種方式所帶來的效果會比前面所說的日誌編碼、消息壓縮等更加的明顯。分區在其他分散式組件中也有大量涉及,至於為什麼分區能夠提升性能這種基本知識在這裡就不在贅述了。不過需要註意,一昧地增加分區並不能一直帶來性能的提升。
一致性
絕大多數的資料在講述Kafka性能優化的舉措之時是不會提及一致性的東西的。我們所瞭解的通用的一致性協議如Paxos、Raft、Gossip等,而Kafka另闢蹊徑採用類似PacificA的做法不是“拍大腿”拍出來的,採用這種模型會提升整理的效率。具體的細節後面會整理一篇,類似《在Kafka中使用Raft替換PacificA的可行性分析及優缺點》。
順序寫盤
操作系統可以針對線性讀寫做深層次的優化,比如預讀(read-ahead,提前將一個比較大的磁碟塊讀入記憶體) 和後寫(write-behind,將很多小的邏輯寫操作合併起來組成一個大的物理寫操作)技術。Kafka 在設計時採用了文件追加的方式來寫入消息,即只能在日誌文件的尾部追加新的消 息,並且也不允許修改已寫入的消息,這種方式屬於典型的順序寫盤的操作,所以就算 Kafka 使用磁碟作為存儲介質,它所能承載的吞吐量也不容小覷。
頁緩存
為什麼Kafka性能這麼高?當遇到這個問題的時候很多人都會想到上面的順序寫盤這一點。其實在順序斜盤前面還有頁緩存(PageCache)這一層的優化。
頁緩存是操作系統實現的一種主要的磁碟緩存,以此用來減少對磁碟 I/O 的操作。具體 來說,就是把磁碟中的數據緩存到記憶體中,把對磁碟的訪問變為對記憶體的訪問。為了彌補性 能上的差異,現代操作系統越來越“激進地”將記憶體作為磁碟緩存,甚至會非常樂意將所有 可用的記憶體用作磁碟緩存,這樣當記憶體回收時也幾乎沒有性能損失,所有對於磁碟的讀寫也 將經由統一的緩存。
當一個進程準備讀取磁碟上的文件內容時,操作系統會先查看待讀取的數據所在的頁 (page)是否在頁緩存(pagecache)中,如果存在(命中)則直接返回數據,從而避免了對物 理磁碟的 I/O 操作;如果沒有命中,則操作系統會向磁碟發起讀取請求並將讀取的數據頁存入 頁緩存,之後再將數據返回給進程。同樣,如果一個進程需要將數據寫入磁碟,那麼操作系統也會檢測數據對應的頁是否在頁緩存中,如果不存在,則會先在頁緩存中添加相應的頁,最後將數據寫入對應的頁。被修改過後的頁也就變成了臟頁,操作系統會在合適的時間把臟頁中的 數據寫入磁碟,以保持數據的一致性。
對一個進程而言,它會在進程內部緩存處理所需的數據,然而這些數據有可能還緩存在操 作系統的頁緩存中,因此同一份數據有可能被緩存了兩次。並且,除非使用 Direct I/O 的方式, 否則頁緩存很難被禁止。此外,用過 Java 的人一般都知道兩點事實:對象的記憶體開銷非常大, 通常會是真實數據大小的幾倍甚至更多,空間使用率低下;Java 的垃圾回收會隨著堆內數據的 增多而變得越來越慢。基於這些因素,使用文件系統並依賴於頁緩存的做法明顯要優於維護一 個進程內緩存或其他結構,至少我們可以省去了一份進程內部的緩存消耗,同時還可以通過結構緊湊的位元組碼來替代使用對象的方式以節省更多的空間。如此,我們可以在 32GB 的機器上使用 28GB 至 30GB 的記憶體而不用擔心 GC 所帶來的性能問題。此外,即使 Kafka 服務重啟, 頁緩存還是會保持有效,然而進程內的緩存卻需要重建。這樣也極大地簡化了代碼邏輯,因為 維護頁緩存和文件之間的一致性交由操作系統來負責,這樣會比進程內維護更加安全有效。
Kafka 中大量使用了頁緩存,這是 Kafka 實現高吞吐的重要因素之一。雖然消息都是先被寫入頁緩存,然後由操作系統負責具體的刷盤任務的。
零拷貝
Kafka使用了Zero Copy技術提升了消費的效率。前面所說的Kafka將消息先寫入頁緩存,如果消費者在讀取消息的時候如果在頁緩存中可以命中,那麼可以直接從頁緩存中讀取,這樣又節省了一次從磁碟到頁緩存的copy開銷。另外對於讀寫的概念可以進一步瞭解一下什麼是寫放大和讀放大。
附
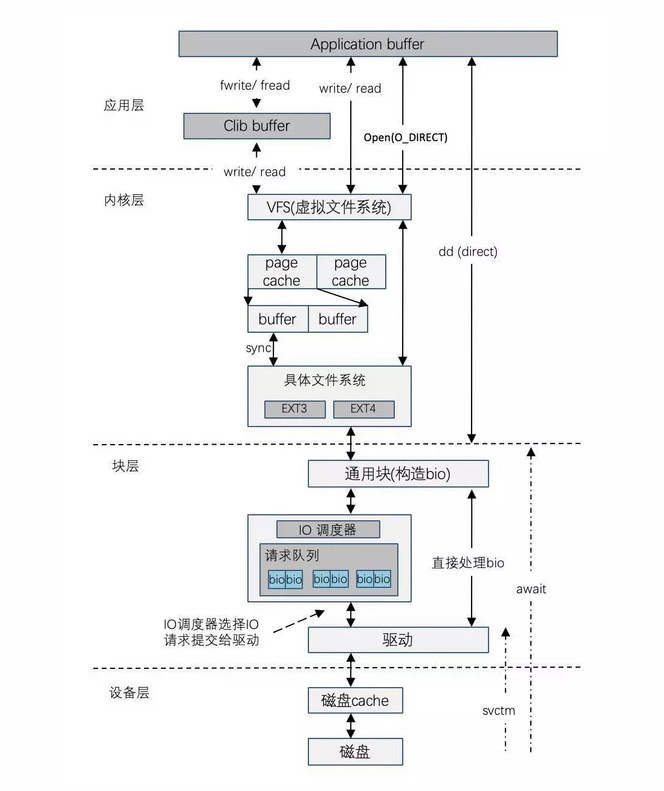
一個磁碟IO流程可以參考下圖:
註:文章轉載自網路,如果您覺得本文對您有幫助,歡迎關註我的公眾號【Java技術zhai】,有新文章發佈會第一時間通知您。

