
讀取: 1) 客戶端調用 DistributedFileSystem 的 Open() 方法打開文件。2) DistributedFileSystem 用 RPC 連接到 NameNode,請求獲取文件的數據塊的信息;NameNode 返迴文件的部分或者全部數據塊列表;對於每個數據塊,NameNod ...
讀取:
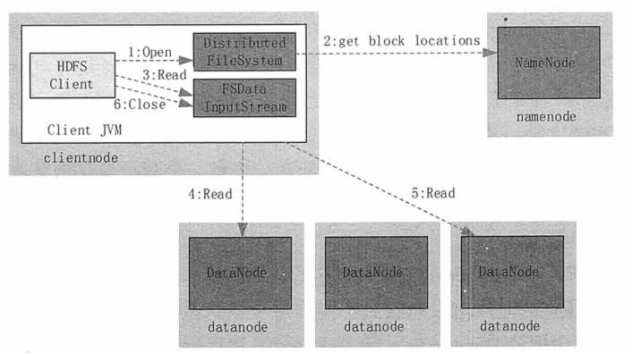
1) 客戶端調用 DistributedFileSystem 的 Open() 方法打開文件。
2) DistributedFileSystem 用 RPC 連接到 NameNode,請求獲取文件的數據塊的信息;NameNode 返迴文件的部分或者全部數據塊列表;對於每個數據塊,NameNode 都會返回該數據塊副本的 DataNode 地址;DistributedFileSystem 返回 FSDataInputStream 給客戶端,用來讀取數據。
3) 客戶端調用 FSDataInputStream 的 Read() 方法開始讀取數據。
4) FSInputStream 連接保存此文件第一個數據塊的最近的 DataNode,並以數據流的形式讀取數據;客戶端多次調用 Read(),直到到達數據塊結束位置。
5) FSInputStream連接保存此文件下一個數據塊的最近的 DataNode,並讀取數據。
6) 當客戶端讀取完所有數據塊的數據後,調用 FSDataInputStream 的 Close() 方法。
寫入:
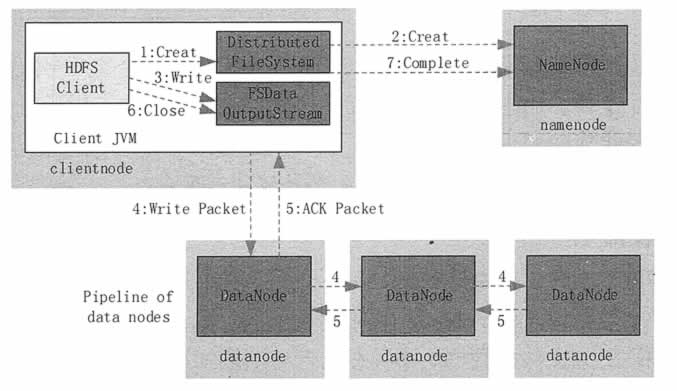
1) 客戶端調用 DistribuedFileSystem 的 Create() 方法來創建文件。
2) DistributedFileSystem 用 RPC 連接 NameNode,請求在文件系統的命名空間中創建一個新的文件;NameNode 首先確定文件原來不存在,並且客戶端有創建文件的許可權,然後創建新文件;DistributedFileSystem 返回 FSOutputStream 給客戶端用於寫數據。
3) 客戶端調用 FSOutputStream 的 Write() 函數,向對應的文件寫入數據。
4) 當客戶端開始寫入文件的時候,客戶端會將文件切分成多個 packets,併在內部以數據隊列“data queue(數據隊列)”的形式管理這些 packets,並向 namenode 申請 blocks,獲 取用來存儲 replicas 的合適的 datanode 列表,列表的大小根據 namenode 中 replication 的設定而定;
隊列中的分包被打包成數據包,將第一個塊寫入第一個Datanode,第一個 Datanode寫完傳給第二個節點,第二個寫完傳給第三節點
5) 為了保證所有 DataNode 的數據都是準確的,接收到數據的 DataNode 要向發送者發送確認包(ACK Packet)。確認包沿著數據流管道反向而上,當第三個節點寫完返回一個ack packet給 第二個節點,第二個返回一個ack packet給第一個節點,第一個節點返回ack packet給 FSDataOutputStream對象,意思標識第一個塊寫完,副本數為3;然後剩餘的塊依次這樣寫;
6) 不斷執行第 (3)~(5)步,直到數據全部寫完。
7) 調用 FSOutputStream 的 Close() 方法,將所有的數據塊寫入數據流管道中的數據結點,並等待確認返回成功。最後通過 NameNode 完成寫入。


