
升級前準備: 配置好新的hadoop-2.7.2到各個集群伺服器上 配置好新的環境變數備用 開始升級: 1.停止hive、hbase、zookeeper等相關服務 2.檢查文件(如果文件太多太費時間可以不做) 檢查元數據塊(過濾所有以小圓點開始的行): 3.停止hadoop集群 4.修改環境變數 s ...
升級前準備:
配置好新的hadoop-2.7.2到各個集群伺服器上
配置好新的環境變數備用
開始升級:
1.停止hive、hbase、zookeeper等相關服務
2.檢查文件(如果文件太多太費時間可以不做)
hadoop dfsadmin -safemode enter
檢查元數據塊(過濾所有以小圓點開始的行):
hadoop fsck / -files -blocks -locations |grep -v -E '^\.' > old-fsck.log hadoop dfsadmin -safemode leave
3.停止hadoop集群
$HADOOP_HOME/bin/stop-all.sh
4.修改環境變數
source /etc/profile 各個集群都執行
echo $HADOOP_HOME 看是否是新的hadoop目錄了
5.開始升級
hadoop-daemon.sh start namenode -upgrade 啟動namenode升級
hadoop-daemons.sh start datanode 啟動各個數據節點
打開日誌文件觀察有誤錯誤,如果報記憶體溢出,修改hadoop-env.sh 文件的export HADOOP_HEAPSIZE,HADOOP_CLIENT_OPTS參數值和yarn-env.sh文件JAVA_HEAP_MAX參數值
打開50070埠web頁面觀察升級過程
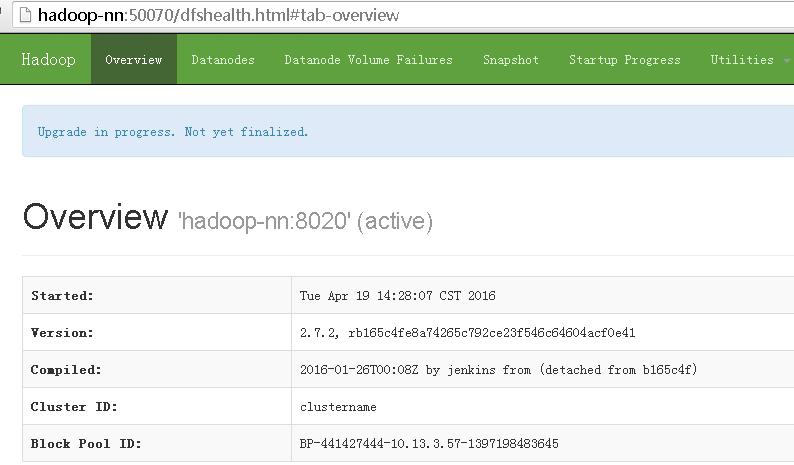

等所有數據節點全部升級完成後,檢查數據完整性(此過程根據集群數量得等一段時間)
hadoop fsck /
有問題回滾命令:
hadoop-daemon.sh start namenode -rollback
hadoop-daemons.sh start datanode –rollback
6.提交升級
運行一段時間後,觀察沒有問題,可以提交升級
hdfs dfsadmin -finalizeUpgrade


