
熟悉MySQL的人,都知道InnoDB存儲引擎,如大家所知,Redo Log是innodb的核心事務日誌之一,innodb寫入Redo Log後就會提交事務,而非寫入到Datafile。之後innodb再非同步地將新事務的數據非同步地寫入Datafile,真正存儲起來。 那麼innodb引擎有了redo ...
熟悉MySQL的人,都知道InnoDB存儲引擎,如大家所知,Redo Log是innodb的核心事務日誌之一,innodb寫入Redo Log後就會提交事務,而非寫入到Datafile。之後innodb再非同步地將新事務的數據非同步地寫入Datafile,真正存儲起來。
那麼innodb引擎有了redo log和buffer pool以後,為什麼能夠在提升性能的同時,還能保證不丟數據呢? Buffer Pool, Redo Log以及Datafile之間的具體關係是什麼呢。
另外Innodb還有一大堆概念,Dirty Page, LRU, LSN,Checkpoint等等,這些概念在Innodb里是什麼運作的呢?
下麵通過一張圖來告訴大家
Buffer Pool, Redo Log以及Datafile的關係
 Innodb的原理
Innodb的原理
大家可以把innodb的事務寫入過程看成寫作一篇文章的過程。Innodb的寫入過程其實和我們寫作的過程是非常類似的。
試想,領導讓我們寫一篇文章,發表在論壇上。然後我們想到了一個絕佳的點子,並決定要放到文章里,可是手上還有其他事情,一時半會兒寫不完,又擔心過後忘了,領導還等著我們答覆,此時我們會怎麼做呢?我們一定會先大概構思個提綱,並把提綱和一些關鍵細節記錄到本子上,作為草稿,然後立刻告訴領導自己要寫什麼東西,讓其確認。最後等晚上有時間了,再根據草稿去斟詞酌句,編寫正稿。
在這個過程中,我們用到的幾個關鍵的東西:
我們的大腦,用來臨時暫時記住我們的點子
草稿,我們需要草稿來保證不會把點子和關鍵的細節給忘了
正稿,這是我們最終要輸出的東西
有了這幾個東西,我們不僅能確保我們不會錯過一篇漂亮的文章,還能快速告訴領導自己一定可以搞定這件事情。
Innodb實際上也用到了這幾個關鍵的東西:
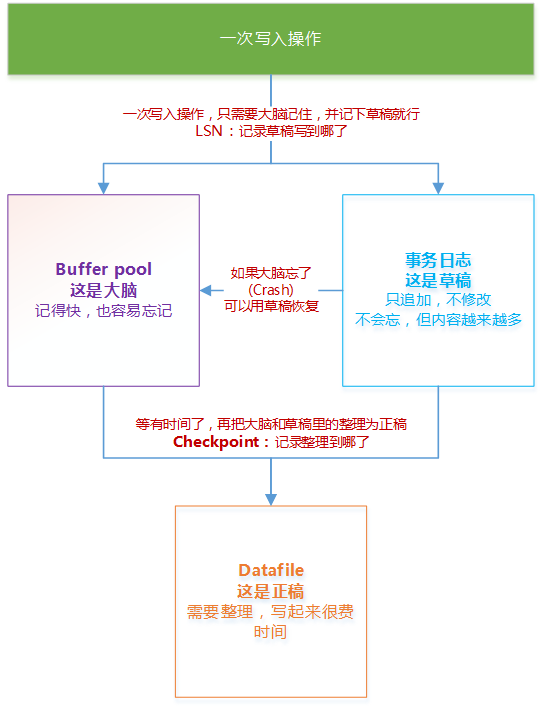
Buffer Pool:就是我們的大腦
事務日誌:就是我們的草稿
Datafile:就是我們的正稿
只要按照之前寫文章的過程,來進行整個事務的寫入操作,不僅能保證不丟失數據,而且能夠快速響應。
一次寫入操作是一次事務,innodb首先把事務數據寫入到Buffer Pool和事務日誌中,也就是在大腦中記憶下來,並寫下草稿。然後就可以提交事務,響應客戶端了。之後innodb在“有時間的時候”,非同步地把這次寫入的數據從Buffer Pool,或者事務日誌中正式地寫入到Datafile中,形成“正稿”。
其中,innodb為了保證事務日誌這個“草稿”一定能無損地還原成正稿,還不能占用太多空間,事務日誌需要有以下特點:
事務日誌中一定保存了要寫入的所有數據內容
事務日誌只會把新事務追加在日誌最後,而不會去修改之前的內容
一旦事務數據被寫到datafile,事務日誌中的“草稿”就可以刪除了
通過上面3個特點我們可以看出,在形成“正稿”之前,“草稿”是不會被刪除的;同時,“草稿”的空間是可以被迴圈利用的;最後,只要“草稿”在,我們一定能寫出“正稿”。
這裡還需要說明的,是Recovery流程。也就是如果在形成“正稿”前,資料庫Crash了,我們需要重啟整個進程,伺服器,甚至只能把數據複製到另外一臺伺服器來進行恢復。這個時候,事務日誌這個“草稿”就發揮了它最大的作用——數據恢復。這也和我們在工作生活中常出現的問題——把事情忘了——非常類似。
Buffer Pool本質就是存儲於記憶體中的一個數據結構,記憶體和人的大腦一樣,是“健忘”的。資料庫Crash時,Buffer Pool中的數據極大可能“灰飛煙滅”了。因此,事務日誌就如我們貼心的“記事本”,它把我們的記憶,保存為“草稿”,當我們忘了的時候,就可以翻開,把記憶重新回想起來。

LSN和Checkpoint
上面介紹了一次寫入事務的情況,而資料庫在使用過程中,事務都是連續不斷,根據上面所述innodb邏輯,寫“草稿”和寫“正稿”速度和進度絕大部分情況下是不一樣的。
再繼續上面“寫作文章”例子,如果我們的文章很長,一天寫不完,而白天都有其他工作,我們只能記錄草稿,只有晚上回去才能繼續寫正稿。那麼我們就面臨一個問題:我們昨天寫到哪了。
最常見的辦法就是,每天晚上去對照一下草稿的內容和正稿的內容,以此來判斷寫到哪了,但這比較花時間,因為正稿中可能包含了很多華麗的語句,我們需要思考一下才能對比上內容。
另外一個更簡單的辦法,就是每天晚上寫完正稿後,我們在草稿上做個標記,標記下最後一條被寫為正稿的內容,這樣第二天晚上,我們就可以從這個標記的後面一條開始,繼續寫我們的正稿,而不需要去對比內容。
顯然第二個方法效率更高,而且沒有什麼額外的風險。因此innodb就使用了這個辦法。LSN是草稿上每一條記錄的編號,我們每天晚上標記下最後一條寫到正稿的記錄編號,這個標記的編號,就是Checkpoint。Innodb根據這個checkpoint,就可以很快知道上次回放到哪裡,同時也可以把這個編號之前的草稿,全部刪掉了。
轉載原文:http://www.360doc.com/content/18/0523/10/45882429_756316759.shtml


