
引用:https://baijiahao.baidu.com/s?id=1600687025749463237&wfr=spider&for=pc 參考下圖,正向代理用途:Client無法直接訪問Server,比如谷歌翻牆,於是請求發送給代理,代理可以訪問Server並將其返回信息返回給Client ...
引用:https://baijiahao.baidu.com/s?id=1600687025749463237&wfr=spider&for=pc
參考下圖,正向代理用途:Client無法直接訪問Server,比如谷歌FQ,於是請求發送給代理,代理可以訪問Server並將其返回信息返回給Client。
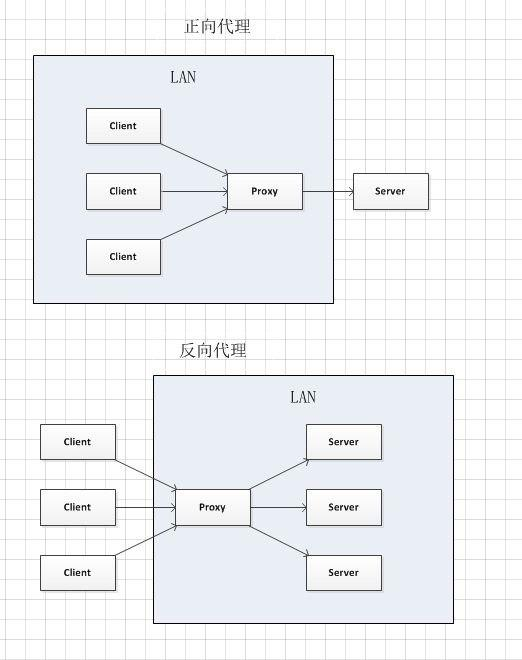
反向代理用途:1.把Server的IP功能變數名稱隱藏起來不直接暴露,Proxy充當跳板機/前置機的功能;2.對於大量的客戶端併發請求,進行分發給各個伺服器,實現負載均衡。
反向代理TCP/UDP負載均衡配置和選擇:編輯nginx.conf文件
#進程數,一般一個進程就夠了 worker_processes 1; events { #單個進程最大連接數(最大連接數=連接數*進程數) worker_connections 1024; } #TCP/UDP套接字固定字元串:stream stream { #反向代理URL管理 upstream myproxy { #源地址哈希法,就是對訪問客戶端的IP進行hash後的結果進行分配,這樣每一個客戶端固定請求同一個後端伺服器。 #ip_hash; #按照伺服器響應時間的長短來進行分發的,伺服器響應時間越短的,優先分發。 #fair
#正常分發 server 192.168.3.22:13333; server 192.168.3.22:13334; #權重,權重越大,連接數量越多,壓力越大。 #server 11.22.333.44:5555 weight=2; #server 11.22.333.11:6666 weight=1; #表示當前的server臨時不參與負載。 #server 11.22.333.22:8888 down; #其他全部的非backup機器down或者忙的時候,請求backup機器。所以這台機器壓力會最輕。 #server 11.22.333.33:8888 backup; } server { #region 統一監聽埠 listen 13335; #連接超時時間 proxy_connect_timeout 3s; #N秒內伺服器沒有接收到數據自動斷開與客戶端的連接,如不想要此功能則註釋該行 #proxy_timeout 10s; #反向代理URL proxy_pass myproxy; } }
打開cmd,輸入nginx -c nginx.conf,回車執行。
註意如果要關閉nginx,關了控制台是沒用的,需要另外打開一個cmd視窗輸入nginx -s quit,回車執行。
一般只修改配置文件,不需要重啟或關閉nginx,執行 nginx -s reload 重新載入配置文件即可。
深入Nginx
附上原文鏈接:https://blog.csdn.net/wy757510722/article/details/75267431
nginx是以多進程的方式來工作的,當然nginx也是支持多線程的方式的,只是我們主流的方式還是多進程的方式,也是nginx的預設方式:
1.nginx、redis等每個單獨的進程都可以獨占資源,通常情況下每個伺服器會開幾十個nginx、redis進程,這樣如果採用多線程的模式,各個線程能夠利用的資源就會受到一些限制,諸如:ulimit -n 命令展示的每個進程最多可以打開的文件數這樣的限制。
2.nginx中除了master需要跟worker通過管道進行通信,worker之間不需要通信,而且每個worker的功能都一樣,屬於常駐進程。在這種場景下多線程的優勢體現不出來,而且也可以避免多線程在編程時需要考慮資源訪問互斥、同步等問題帶來的編程複雜度的提升,以及可能帶來的調試困難。(這裡的同步、互斥並非指線程間消息傳遞等操作)
3.nginx採用多進程的方式,既可以避免因某個線程故障導致整個服務不可用的問題,也可以實現配置熱載入,不停服升級版本。
多進程工作模式
1. nginx在啟動後,會有一個master進程和多個worker進程。master進程主要用來管理worker進程,包含:接收來自外界的信號(重新載入配置文件,重啟nginx命令等),向各worker進程發送信號,監控 worker進程的運行狀態,當worker進程異常情況下退出後,會自動重新啟動新的worker進程。而基本的網路事件,則是放在worker進程中來處理了 。多個worker進程之間是對等的,他們同等競爭來自客戶端的請求,各進程互相之間是獨立的 。一個請求,只可能在一個worker進程中處理,一個worker進程,不可能處理其它進程的請求。 worker進程的個數是可以設置的,一般我們會設置與機器cpu核數一致,這裡面的原因與nginx的進程模型以及事件處理模型是分不開的 。
2.Master接收到信號以後怎樣進行處理(./nginx -s reload )?首先master進程在接到信號後,會先重新載入配置文件,然後再啟動新的進程,並向所有老的進程發送信號,告訴他們可以光榮退休了。新的進程在啟動後,就開始接收新的請求,而老的進程在收到來自 master的信號後,就不再接收新的請求,並且在當前進程中的所有未處理完的請求處理完成後,再退出 。
3. worker進程又是如何處理請求的呢?我們前面有提到,worker進程之間是平等的,每個進程,處理請求的機會也是一樣的。當我們提供80埠的http服務時,一個連接請求過來,每個進程都有可能處理這個連接,怎麼做到的呢?首先,每個worker進程都是從master 進程fork(分配)過來,在master進程裡面,先建立好需要listen的socket之後,然後再fork出多個worker進程,這樣每個worker進程都可以去accept這個socket(當然不是同一個socket,只是每個進程的這個socket會監控在同一個ip地址與埠,這個在網路協議裡面是允許的)。一般來說,當一個連接進來後,所有在accept在這個socket上面的進程,都會收到通知,而只有一個進程可以accept這個連接,其它的則accept失敗,這是所謂的驚群現象。當然,nginx也不會視而不見,所以nginx提供了一個accept_mutex這個東西,從名字上,我們可以看這是一個加在accept上的一把共用鎖。有了這把鎖之後,同一時刻,就只會有一個進程在accpet連接,這樣就不會有驚群問題了。accept_mutex是一個可控選項,我們可以顯示地關掉,預設是打開的。當一個worker進程在accept這個連接之後,就開始讀取請求,解析請求,處理請求,產生數據後,再返回給客戶端,最後才斷開連接,這樣一個完整的請求就是這樣的了。我們可以看到,一個請求,完全由worker進程來處理,而且只在一個worker進程中處理。
4.nginx採用這種進程模型有什麼好處呢?採用獨立的進程,可以讓互相之間不會影響,一個進程退出後,其它進程還在工作,服務不會中斷,master進程則很快重新啟動新的worker進程。當然,worker進程的異常退出,肯定是程式有bug了,異常退出,會導致當前worker上的所有請求失敗,不過不會影響到所有請求,所以降低了風險。
5.有人可能要問了,nginx採用多worker的方式來處理請求,每個worker裡面只有一個主線程,那能夠處理的併發數很有限啊,多少個worker就能處理多少個併發,何來高併發呢?非也,這就是nginx的高明之處,nginx採用了非同步非阻塞的方式來處理請求,也就是說,nginx是可以同時處理成千上萬個請求的 。對於IIS伺服器每個請求會獨占一個工作線程,當併發數上到幾千時,就同時有幾千的線程在處理請求了。這對操作系統來說,是個不小的挑戰,線程帶來的記憶體占用非常大,線程的上下文切換帶來的cpu開銷很大,自然性能就上不去了,而這些開銷完全是沒有意義的。我們之前說過,推薦設置worker的個數為cpu的核數,在這裡就很容易理解了,更多的worker數,只會導致進程來競爭cpu資源了,從而帶來不必要的上下文切換。而且,nginx為了更好的利用多核特性,提供了cpu親緣性的綁定選項,我們可以將某一個進程綁定在某一個核上,這樣就不會因為進程的切換帶來cache的失效。


