
上周遇到了將數據從orcle導入到impala的問題,這個項目耽誤了我近一周的時間,雖然是種種原因導致的,但是還是做個總結。 需求首先是跑數據,跑數據這個就不敘述,用的是公司的平臺。 講講耽誤我最久的事吧 數據的導入導出。 將數據從orcle導出 PLSQL直接導出 我這邊連接公司的orcle資料庫 ...
上周遇到了將數據從oracle導入到impala的問題,這個項目耽誤了我近一周的時間,雖然是種種原因導致的,但是還是做個總結。
需求首先是跑數據,跑數據這個就不敘述,用的是公司的平臺。
講講耽誤我最久的事吧 數據的導入導出。
將數據從oracle導出
PLSQL直接導出
我這邊連接公司的orcle資料庫是PLSQL,本身PLSQL就是可以可以導出數據的,而且很簡單。
PLSQL在select後就能導出表的數據,能到處成csv、sql、xml等等。
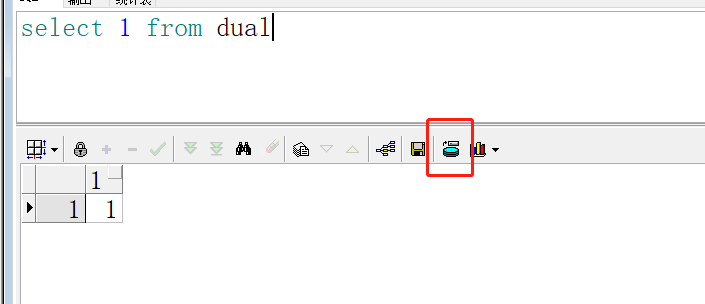
但是這方法最後還是被捨棄了,有幾個原因:
1.這種導出方法很慢,我導出200M的csv數據需要40分鐘
2.數據導出有限制,這種方法好像最多只能導出104w數據,但是需求是需要導出1億兩千萬的數據,很明顯是不可以的。
註:中間我考慮過按分區導出數據,因為這個表是按時時間分了分區,然後發現還是不行,因為數量還是太大了,30天的數據平均下來每個還是有400w,最後放棄了
事實證明這個方法不是很好用,導出幾百、幾天還行。多了就不行了。
使用oracle的內建包UTL_FILE
第二種用orcle裡面用utl_file讀寫文件包 ,每分鐘大約處理百萬行。適用於大量導出時。
一、首先需要新建一個存儲過程
1 CREATE 2 OR REPLACE PROCEDURE SQL_TO_CSV ( 3 P_QUERY IN VARCHAR2,-- PLSQL文 4 P_DIR IN VARCHAR2,-- 導出的文件放置目錄 5 P_FILENAME IN VARCHAR2 -- CSV名 6 ) IS L_OUTPUT UTL_FILE.FILE_TYPE; 7 8 L_THECURSOR INTEGER DEFAULT DBMS_SQL.OPEN_CURSOR; 9 10 L_COLUMNVALUE VARCHAR2 (4000); 11 12 L_STATUS INTEGER; 13 14 L_COLCNT NUMBER := 0; 15 16 L_SEPARATOR VARCHAR2 (1); 17 18 L_DESCTBL DBMS_SQL.DESC_TAB; 19 20 P_MAX_LINESIZE NUMBER := 32000; 21 22 23 BEGIN 24 --OPEN FILE 25 L_OUTPUT := UTL_FILE.FOPEN ( 26 P_DIR, 27 P_FILENAME, 28 'W', 29 P_MAX_LINESIZE 30 ); 31 32 --DEFINE DATE FORMAT 33 EXECUTE IMMEDIATE 'ALTER SESSION SET NLS_DATE_FORMAT=''YYYY-MM-DD HH24:MI:SS'''; 34 35 --OPEN CURSOR 36 DBMS_SQL.PARSE ( 37 L_THECURSOR, 38 P_QUERY, 39 DBMS_SQL.NATIVE 40 ); 41 42 DBMS_SQL.DESCRIBE_COLUMNS ( 43 L_THECURSOR, 44 L_COLCNT, 45 L_DESCTBL 46 ); 47 48 --DUMP TABLE COLUMN NAME 49 FOR I IN 1 ..L_COLCNT 50 LOOP 51 UTL_FILE.PUT ( 52 L_OUTPUT, 53 L_SEPARATOR || '"' || L_DESCTBL (I ).COL_NAME || '"' 54 ); 55 56 --輸出表欄位 57 DBMS_SQL.DEFINE_COLUMN ( 58 L_THECURSOR, 59 I, 60 L_COLUMNVALUE, 61 4000 62 ); 63 64 L_SEPARATOR := ','; 65 66 67 END 68 LOOP 69 ; 70 71 UTL_FILE.NEW_LINE (L_OUTPUT);--輸出表欄位 72 --EXECUTE THE QUERY STATEMENT 73 L_STATUS := DBMS_SQL. EXECUTE (L_THECURSOR); 74 75 --DUMP TABLE COLUMN VALUE 76 WHILE ( 77 DBMS_SQL.FETCH_ROWS (L_THECURSOR) > 0 78 ) 79 LOOP 80 L_SEPARATOR := ''; 81 82 FOR I IN 1 ..L_COLCNT 83 LOOP 84 DBMS_SQL.COLUMN_VALUE ( 85 L_THECURSOR, 86 I, 87 L_COLUMNVALUE 88 ); 89 90 UTL_FILE.PUT ( 91 L_OUTPUT, 92 L_SEPARATOR || '"' || TRIM ( 93 BOTH ' ' 94 FROM 95 REPLACE (L_COLUMNVALUE, '"', '""') 96 ) || '"' 97 ); 98 99 L_SEPARATOR := ','; 100 101 102 END 103 LOOP 104 ; 105 106 UTL_FILE.NEW_LINE (L_OUTPUT); 107 108 109 END 110 LOOP 111 ; 112 113 --CLOSE CURSOR 114 DBMS_SQL.CLOSE_CURSOR (L_THECURSOR); 115 116 --CLOSE FILE 117 UTL_FILE.FCLOSE (L_OUTPUT); 118 119 EXCEPTION 120 WHEN OTHERS THEN 121 RAISE; 122 123 124 END; 125 126 /
二、創建導出路徑
create or replace directory OUT_PATH as 'D:\out_path';
註意:這步只是在oracle sql developer中定義了導出路徑,如果路徑不存在,並不會自動生成,需要手動去新建!
三、調用數據
EXEC sql_to_csv('select * from <tablename>','OUT_PATH','<filename>');
這種是在網上查到的方法,這邊因為最近公司規定不能下載到本地所以沒有採用這種方法,但是這種方法測試是可行的,沒有具體測試效率。
sqluldr伺服器導出數據
第三種是我最後採用的方法
用sqluldr腳本導出到服務上,然後把文件轉移到impala的伺服器上去。
下載鏈接鏈接:https://pan.baidu.com/s/1bRRr-BDQL0yIJJTa16ttTw
提取碼:1tns
將sqluldr.rar中文件上傳到orcle所在伺服器中,然後執行 ./sqluldr2_linux64_10204.binuser= query="" field=',' text=txt file='' charset=UTF8; file='' 是存放路徑 charset=編碼 user=是orcle資料庫地址 query=是導出語句
然後執行效率100w大概40秒左右,速度比較快。
數據上傳到impala中
1、將數據從oracle伺服器轉移到impala所在伺服器
2、在hive中建好導出數據的表
CREATE TABLE tmp.tmp_call_orcle_1 ( test string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' --csv分隔符 STORED AS TEXTFILE; --設置文件為test文件
3、用hdfs命令將數據導入到建好的表中:hdfs dfs -put test.csv /user/hive/warehouse/tmp.db/test
4、將表的讀取路徑改成hdfs路徑
load data inpath '/user/hive/warehouse/tmp.db/tmp_call_orcle_1/tmp_call_orcle_1.csv' into table tmp.tmp_call_orcle_1;
至此就完成了將orcle數據導入impala的操作

