
查詢語句 首先, 準備數據, 地址是: https://github.com/cystanford/sql_heros_data, 除了id以外, 24個欄位的含義如下: 查詢 查詢分為單列查詢, 多列查詢, 全部查詢等等: 學習階段可以使用SELECT , 但是在生產環境不要用, 因為效率會非常低 ...
查詢語句
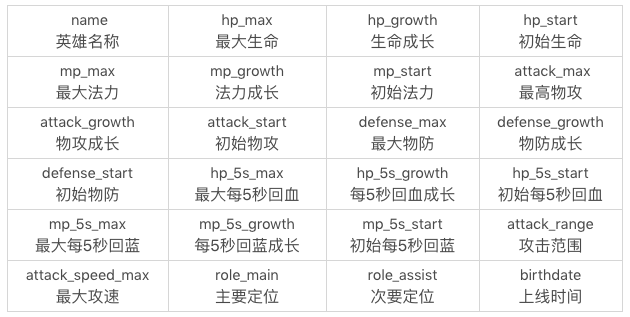
首先, 準備數據, 地址是: https://github.com/cystanford/sql_heros_data, 除了id以外, 24個欄位的含義如下:
查詢
查詢分為單列查詢, 多列查詢, 全部查詢等等:
SELECT name FROM heros; // 單列查詢
SELECT name, hp_max, mp_max, attack_max, defense_max FROM heros; // 多列查詢
SELECT * FROM heros; // 全部查詢學習階段可以使用SELECT *, 但是在生產環境不要用, 因為效率會非常低.
起別名
起別名是一種技巧, 可以對原有名稱進行簡化, 讓SQL語句看起來更加精簡, 這個在多表連接查詢的時候非常有用:
SELECT name AS n, hp_max AS hm, mp_max AS mm, attack_max AS am, defense_max AS dm FROM heros; // 起別名查詢查詢常數
SELECT 查詢可以對常數進行查詢, 簡單說就是在SELECT查詢結果中增加一列固定的常數列. 一般用於整合不同的數據源, 用常數作為這個表的標記.
SELECT '王者榮耀' as platform, name FROM heros; // 查詢常數虛構了一個platform欄位, 註意的是, 字元串常數要是用單引引起來, 否則會被當做列名來進行查詢, 會報錯, 如果是數字的話不需要添加單引號.
去除重覆行
去除重覆行是個非常少實用的操作, 關鍵字是DISTINCT:
SELECT DISTINCT attack_range FROM heros;
SELECT DISTINCT attack_range, name FROM heros需要註意的是:
- DISTINCT需要放在所有的列名之前, 也就是SELECT 之後.
- DISTINCT其實是對後面所有列名的組合進行去除, 並不是對某一列進行去重. 這也是為什麼DISTINCT要放在所有的列名之前的原因.
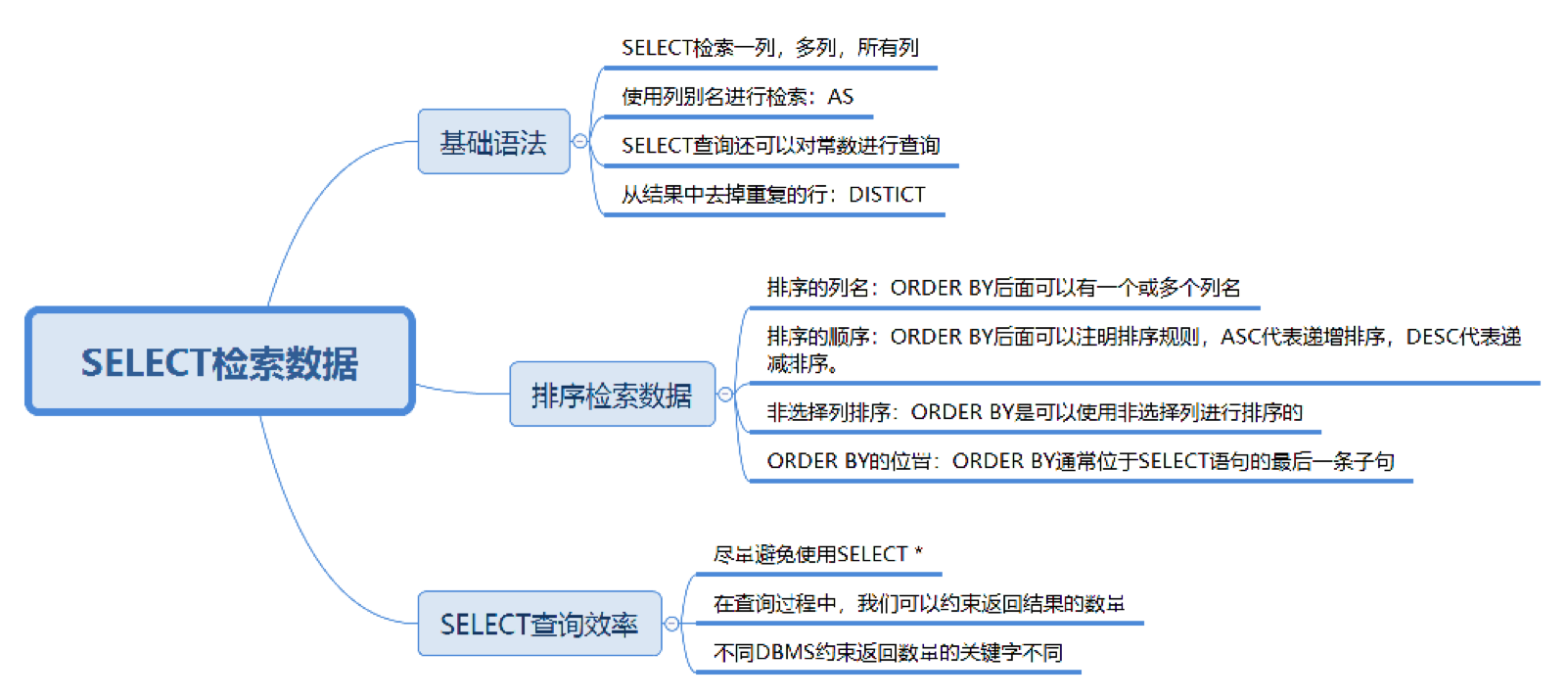
排序檢索數據
檢索數據的時候, 可以按照某種順序來進行結果的返回, 比如說查詢所有的英雄, 按照最大生命從高到低的順序進行排列, 這個時候排序就要使用到 ORDER BY 子句了, 註意點如下:
- 排序的列名: ORDER BY後面可以有一個或多個列名, 如果是多個列名進行排序, 會按照後面第一個列先進行排序, 當第一個列的值相同的時候, 再按照第二個列進行排序, 以此類推.
- 排序的順序: ORDER BY後面可以註明排序規則, ASC代表遞增排序, DESC代表遞減排序, 沒有註明規則, 預設是遞增排序. 還有對數值類型欄位的排序很容易理解, 那如果是文本數據呢? 需要參考資料庫的設置方式, 才可以進行判斷.
- 非選擇列排序: ORDER BY 可以使用非選擇列進行排序, 也就是說SELECT後面沒有這個列名, 同樣可以放到ORDER BY後面進行排序.
- ORDER BY的位置: ORDER BY通常位於SELECT語句的最後一條子句, 否則會報錯.
SELECT name, hp_max FROM heros ORDER BY hp_max DESC ; // 最大生命排序
SQL:SELECT name, hp_max FROM heros ORDER BY mp_max, hp_max DESC; // 最大法力升序, 法力相同, 生命值降序排序約束返回結果的數量
約束返回結果的數量, 使用LIMIT關鍵字.
SELECT name, hp_max FROM heros ORDER BY hp_max DESC LIMIT 5; // 最大生命值從高到低排序並返回前五條數據註意的是在不同的DBMS中, 使用的關鍵字可能不同. 在 MySQL、PostgreSQL、MariaDB 和 SQLite 中使用 LIMIT 關鍵字,而且需要放到 SELECT 語句的最後面。如果是 SQL Server 和 Access,需要使用 TOP 關鍵字
SELECT TOP 5 name, hp_max FROM heros ORDER BY hp_max DESC;如果是 DB2,使用FETCH FIRST 5 ROWS ONLY這樣的關鍵字
SELECT name, hp_max FROM heros ORDER BY hp_max DESC FETCH FIRST 5 ROWS ONLY; 如果是 Oracle,你需要基於 ROWNUM 來統計行數:
SQL:SELECT name, hp_max FROM heros WHERE ROWNUM <=5 ORDER BY hp_max DESC;約束返回結果數量可以減少數據表的網路傳輸量, 可以提升查詢效率.
SELECT的執行順序
這裡要說的是兩個順序, 一個是關鍵字的順序, 一個是SELECT語句的執行順序:
- 關鍵字的順序:
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ...- SELECT語句的執行順序
FROM > WHERE > GROUP BY > HAVING > SELECT 的欄位 > DISTINCT > ORDER BY > LIMIT一條SQL語句, 關鍵字順序和執行順序如下:
SELECT DISTINCT player_id, player_name, count(*) as num # 順序 5
FROM player JOIN team ON player.team_id = team.team_id # 順序 1
WHERE height > 1.80 # 順序 2
GROUP BY player.team_id # 順序 3
HAVING num > 2 # 順序 4
ORDER BY num DESC # 順序 6
LIMIT 2 # 順序 7在SELECT語句執行這些步驟的時候, 每個步驟都會生成一張虛擬表, 然後將這個虛擬表傳入下一個步驟作為輸入. 但是這些步驟是隱含在SQL的執行過程中, 對我們是不可見的.
SQL的執行原理
SELECT是先執行FROM這一步的, 這個階段, 如果是多張表聯查, 會經歷下麵的步驟:
- 首先通過笛卡爾積, 得到虛擬表vt(virtual table)1-1.
- 通過ON進行篩選, 在虛擬表vt1-1的基礎上進行篩選, 得到虛擬表vt1-2.
- 添加外部行. 如果使用的是左連接、右連接或者是全連接, 就會涉及外部行, 也就是虛擬表v1-2的基礎上增加外部行, 得到虛擬表vt1-3.
兩張以上的表, 會重覆上面的步驟, 直到所有的表都被處理完成, 這個過程得到的最後結論就是現在的原始數據.
拿到原始數據之後, 就可以在這個基礎上再進行WHERE階段了. 這個過程會再次得到一個虛擬表,假設為vt2.
之後進入第三步和第四步, 也就是GROUP BY和HAVING階段, 在vt2上進行分組和分組過濾, 得到中間的虛擬表vt3.
上面篩序就完成了, 接下來進入到SELECT階段, 當然, 是先查詢出所需要的列(欄位), 之後就會進入到DISTINCT階段, 這個也是兩個階段, 也會產生虛擬表.
欄位選擇並過濾重覆之後就會進入到ORDER BY階段進行排序, 再次得到虛擬表.
最後進入LIMIT階段, 得到最終的結果.
在一條SQL中, 不存在的關鍵字, 中間的那部分階段就會省略, 這些就是底層的原理.(疑惑是查詢欄位會使用到別名這些, 這些又是如何識別的呢?)
COUNT(*)的優化
- 一般情況下:
COUNT(*) = COUNT(1) > COUNT(欄位), 所以儘量使用COUNT(*),當然如果你要統計的是就是某個欄位的非空數據行數,那另當別論。畢竟執行效率比較的前提是要結果一樣才行。 - 如果要統計
COUNT(*),儘量在數據表上建立二級索引,系統會自動採用key_len小的二級索引進行掃描,這樣當我們使用SELECT COUNT(*)的時候效率就會提升,有時候提升幾倍甚至更高都是有可能的。

