
01 內容大綱 1. is == id 用法 2. 代碼塊 3. 同一代碼塊下的緩存機制 4. 不同代碼塊下的緩存機制(小數據池) 5. 總結 6. 集合(瞭解) 7. 深淺copy 02 具體內容 1.id is == id是記憶體地址。 你只要創建一個數據(對象)那麼都會在記憶體中開闢一個空間,將這 ...
01 內容大綱
- is == id 用法
- 代碼塊
- 同一代碼塊下的緩存機制
- 不同代碼塊下的緩存機制(小數據池)
- 總結
- 集合(瞭解)
- 深淺copy
02 具體內容
1.id is ==
- id是記憶體地址。 你只要創建一個數據(對象)那麼都會在記憶體中開闢一個空間,將這個數據臨時加在到記憶體中,那麼這個空間是有一個唯一標識的,就好比是身份證號,標識這個空間的叫做記憶體地址,也就是這個數據(對象)的id。可以利用id()去獲取這個數據的記憶體地址。
- == 是比較的兩邊的數值是否相等。
- is 是比較的兩邊的記憶體地址是否相等。 如果記憶體地址相等,那麼這兩邊其實是指向同一個記憶體地址。
- 如果記憶體地址id相同,那麼值肯定相同,但是如果值相同,記憶體地址id不一定相同。
- id is == 三個方法要會用,知道是做什麼的。
# id 相當於身份證號
i = 100
print(id(i))#1366718576
s = 'alex'
print(id(s))#2321428227272
# == 比較的是兩邊的值是否相等
l1 = [1,2,3]
print(id(l1))#2773818942472
l2 = [1,2,3]
print(id(l2))#2773819744136
print(l1 == l2)# True 如果值相同,記憶體地址id不一定相同
s1 = 'alex'
print(id(s1))#2147747407048
s2 = 'alex '
print(id(s2))#2147777344096
print(s1 == s2)#False
# is 判斷的是記憶體地址是否相同
l1 = [1, 2, 3]
l2 = [1, 2, 3]
print(id(l1))#1693709444104 同一代碼塊下,list不適用同一個代碼塊下的緩存機制
print(id(l2))#1693710245768
print(l1 is l2)#False 值相同,記憶體地址id不一定相同
s1 = 'alex'
s2 = 'alex'
print(id(s1))#2941129958600
print(id(s2))#2941129958600
print(s1 is s2)#True
print(s1 == s2)#True # 記憶體地址id 相同,值一定相同
2.代碼塊
- 代碼塊:我們所有的代碼都需要依賴代碼塊執行。Python程式是由代碼塊構造的。塊是一個python程式的文本,他是作為一個單元執行的。
- 代碼塊:一個模塊,一個函數,一個類,一個文件等都是一個代碼塊。
- 互動式方式下一行就是一個代碼塊。(作為交互方式輸入的每個命令都是一個代碼塊。)
- 兩個機制: 同一個代碼塊下,有一個機制。不同的代碼塊下,遵循另一個機制。
3.同一個代碼塊下的緩存機制。
前提條件:在同一個代碼塊內。
機制內容:Python在執行同一個代碼塊的初始化對象的命令時,會檢查是否其值是否已經存在,如果存在,會將其重用。換句話說:執行同一個代碼塊時,遇到初始化對象的命令時,他會將初始化的這個變數與值存儲在一個字典中,在遇到新的變數時,會先在字典中查詢記錄,如果有同樣的記錄那麼它會重覆使用這個字典中的之前的這個值。
適用的對象: int bool str
具體細則:所有的數字,bool,幾乎所有的字元串。
- int(float): 任何數字在同一代碼塊下都會復用。
- bool: True和False在字典中會以1,0方式存在,並且復用。
- str:幾乎所有的字元串都會符合緩存機制,滿足緩存機制則他們在記憶體中只存在一個,即:id相同。
優點:提升性能,節省記憶體。

i1 = 1000 i2 = 1000 i3 = 1000 print(id(i1))#1328495379536 print(id(i2))#1328495379536 print(id(i3))#1328495379536 i = 800 ##int i1 = 800 print(i is i1) #True s1 = 'hfdjka6757fdslslgaj@!#fkdjlsafjdskl;fjds中國' ##str s2 = 'hfdjka6757fdslslgaj@!#fkdjlsafjdskl;fjds中國' print(s1 is s2) #True
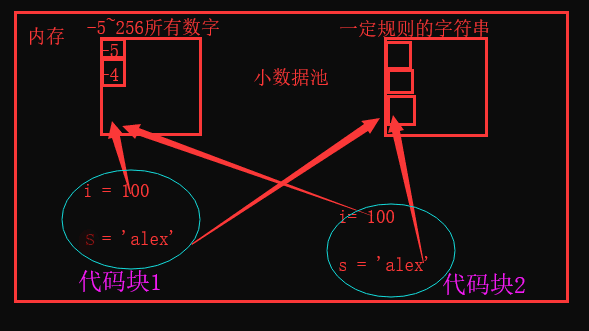
4.不同代碼塊下的緩存機制--- 小數據池。
小數據池,不同代碼塊的緩存機制,也稱為小整數緩存機制,或者稱為駐留機制。
前提條件:在不同代碼塊內。
機制內容:Python自動將-5~256的整數進行了緩存,當你將這些整數賦值給變數時,並不會重新創建對象,而是使用已經創建好的緩存對象。python會將一定規則的字元串在字元串駐留池中,創建一份,當你將這些字元串賦值給變數時,並不會重新創建對象, 而是使用在字元串駐留池中創建好的對象。
適用的對象: int bool str
具體細則:-5~256數字【記】,bool,滿足規則的字元串。(小數據池下的數字和字元串的範圍比同一代碼塊緩存機制時縮小了。)
int:對於整數來說,小數據池的範圍是-5~256 ,如果多個變數都是指向同一個(在這個範圍內的)數字,他們在記憶體中指向的都是一個記憶體地址。
#互動式環境下,屬於不同代碼塊,滿足小數據池的數字範圍是:-5~256 >>> i = 100 #在-5~256內 >>> i1 = 100 >>> print(id(i)) 1366718576 >>> print(id(i1)) 1366718576 >>> print(i is i1) True >>> i2 = 1000 #不在範圍內 >>> i3 = 1000 >>> print(id(i2)) 1928403259184 >>> print(id(i3)) 1928403508080 >>> print(i2 is i3) Falsebool:bool值就是True,False,無論你創建多少個變數指向True,False,那麼他在記憶體中只存在一個。
str:
優點:提升性能,節省記憶體。
5.總結:
- 面試題考。
- 回答的時候一定要分清楚:如果在同一代碼塊下,則採用同一代碼塊下的換緩存機制。如果是不同代碼塊,則採用小數據池的駐留機制。
- 小數據池:數字的範圍是-5~256.
- 緩存機制的優點:提升性能,節省記憶體。
6.集合set
- 集合 set,容器型的數據類型,它要求它裡面的元素是不可變的數據類型(int,str,bool,tuple),但是它本身是可變的數據類型。集合是無序的,不能按索引刪除。{}。
- 不可變的數據類型:int,str,bool,tuple 容器型的數據類型:list, tuple, dict, set
- 集合的作用:
- 列表的去重:不能保留列表原來的順序
- 關係測試: 交集,並集,差集,.....(數據之間的關係)
# 集合的創建:
set1 = set({1,3,'barry',False})
print(set1)#{False, 1, 'barry', 3}
set1 = {1,3,'太白金星',4,'alex',False,'武大'}
print(set1)#{False, 1, '武大', 3, 4, '太白金星', 'alex'}
# 空集合:
dic = {} # 創建空字典
print({}, type({})) #{} <class 'dict'>
set1 = set() # 創建空集合
print(set1) #set()
# 集合的有效性測試:要求它裡面的元素是不可變的數據類型
set1 = {[1,2,3], 3, {'name':'alex'}}
print(set1) #TypeError: unhashable type: 'list' 'dict'
set1 = {'太白金星', '景女神', '武大', '三粗', 'alexsb', '吳老師'}
# 集合的增:
# add
set1.add('xx')
print(set1)#{'景女神', 'xx', '三粗', '太白金星', 'alexsb', '吳老師', '武大'}
set1.add('haha')
print(set1)#{'景女神', 'xx', '三粗', 'haha', '太白金星', 'alexsb', '吳老師', '武大'}
# update迭代著增加---->集合自動去重
set1 = {'太白金星', '景女神', '武大', '三粗', 'alexsb', '吳老師'}
set1.update('derdfetg')
print(set1)#{'g', 'alexsb', '三粗', 'e', '景女神', 'r', '吳老師', '太白金星', 'f', 'd', 't', '武大'}
# 集合的刪
因為集合是無序的,所以不能按索引刪除
# remove :按照元素刪除
set1 = {'太白金星', '景女神', '武大', '三粗', 'alexsb', '吳老師'}
set1.remove('武大')
print(set1)#{'alexsb', '吳老師', '三粗', '太白金星', '景女神'}
# pop 隨機刪除一個元素
set1 = {'太白金星', '景女神', '武大', '三粗', 'alexsb', '吳老師'}
set1.pop()
print(set1)#{'武大', '太白金星', '吳老師', '三粗', 'alexsb'}
#clear
set1.clear() # 清空集合
print(set1)#set()
#del
del set1 # 刪除集合
print(set1)#NameError: name 'set1' is not defined
# 變相改值:先刪除,在增加
set1 = {'太白金星', '景女神', '武大', '三粗', 'alexsb', '吳老師'}
set1.remove('太白金星')
set1.add('男神')
print(set1)#{'三粗', 'alexsb', '吳老師', '武大', '景女神', '男神'}
#關係測試:***【重點】
# 交集(& 或者 intersection)
set1 = {1, 2, 3, 4, 5}
set2 = {4, 5, 6, 7, 8}
print(set1 & set2)#{4, 5}
print(set1.intersection(set2))#{4, 5}
# 並集:(| 或者 union)
set1 = {1, 2, 3, 4, 5}
set2 = {4, 5, 6, 7, 8}
print(set1 | set2)#{1, 2, 3, 4, 5, 6, 7, 8}
print(set1.union(set2))#{1, 2, 3, 4, 5, 6, 7, 8}
# 差集:(- 或者 difference)
set1 = {1, 2, 3, 4, 5}
set2 = {4, 5, 6, 7, 8}
print(set1 - set2)#{1, 2, 3} #求set1獨有的
print(set1.difference(set2))#{1, 2, 3}
print(set2 - set1)#{8, 6, 7}
# 反交集:(^ 或者 symmetric_difference)
print(set1 ^ set2)#{1, 2, 3, 6, 7, 8}
print(set1.symmetric_difference(set2))#{1, 2, 3, 6, 7, 8}
# 子集
set1 = {1,2,3}
set2 = {1,2,3,4,5,6}
print(set1 < set2)#True 說明set1是set2子集。
print(set1.issubset(set2))#True
# 超集
set1 = {1,2,3}
set2 = {1,2,3,4,5,6}
print(set2 > set1)#True 說明set2是set1超集。
print(set2.issuperset(set1))#True
應用:列表的去重 ***【重點】 不能保留列表原來的順序
l1 = [1,'太白', 1, 2, 2, '太白',2, 6, 6, 6, 3, '太白', 4, 5, ]
set1 = set(l1)
l1 = list(set1)
print(l1)#[1, 2, 3, 4, 5, 6, '太白']
7.深淺copy(面試會考,按代碼的形式考)
- 深淺copy其實就是完全複製一份,和部分複製一份的意思。
# 賦值運算【面試題】
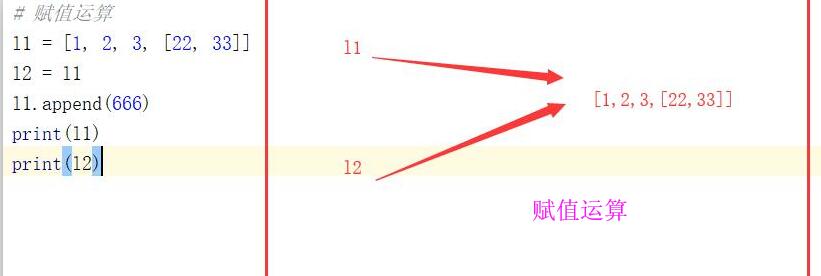
對於賦值運算來說,l1與l2指向的是同一個記憶體地址id,所以他們是完全一樣的。l1,l2指向的是同一個列表,任何一個變數對列表進行改變,剩下那個變數在使用列表之後,這個列表就是發生改變之後的列表。
l1 = [1, 2, 3, [22, 33]]
print(id(l1))#2999106822024
l2 = l1 #賦值運算
print(id(l2))#2999106822024
l1.append(666)
print(l1)#[1, 2, 3, [22, 33], 666]
print(l2)#[1, 2, 3, [22, 33], 666]
####註意區分:(重新建了一個列表)
l1 = [1, 2, 3, [22, 33]]
l2 = [1, 2, 3, [22, 33]]
print(id(l1))#2115308511112
print(id(l2))#2115308545608
l1.append(666)
print(l1)#[1, 2, 3, [22, 33], 666]
print(l2)#[1, 2, 3, [22, 33]]
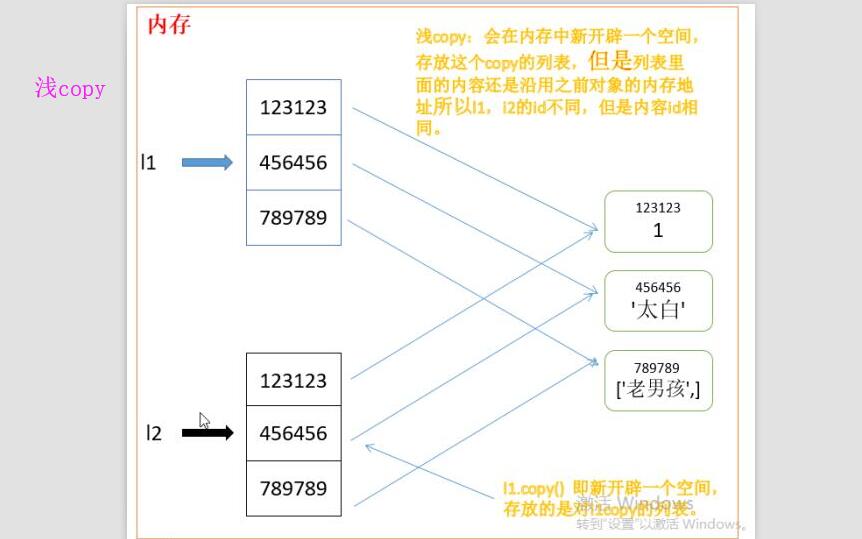
# 淺copy:
對於淺copy來說,只是在記憶體中重新創建了開闢了一個空間存放一個新列表,但是新列表中的元素與原列表中的元素是公用的。
#1:
l1 = [1, 2, 3, [22, 33]]
l2 = l1.copy()
l1.append(666)
print(l1,id(l1))#[1, 2, 3, [22, 33], 666] 2632840208264
print(l2,id(l2))#[1, 2, 3, [22, 33]] 2632840243464
#2: 淺copy只是copy了一個外殼,裡面所有內容指向原來的。所以l1和l2的id不同,但是裡面內容的id相同。
l1 = [1, 2, 3, [22, 33]]
l2 = l1.copy()
l1[-1].append(666)
print(id(l1))#1717681938312 列表id不同
print(id(l2))#1717681973512
print(id(l1[-1]))#1717681136648 內容id相同
print(id(l2[-1]))#1717681136648
print(id(l1[0]))#1366715408 內容id相同相同
print(id(l2[0]))#1366715408
print(id(l1[1]))#1366715440 內容id相同
print(id(l2[1]))#1366715440
print(l1) #[1, 2, 3, [22, 33, 666]]
print(l2) #[1, 2, 3, [22, 33, 666]]
#3.同一代碼塊下:
l1 = [1, 2, 3, [22, 33],(1,2,3)]
l2 = l1.copy()
print(l1,id(l1))#[1, 2, 3, [22, 33], (1, 2, 3)] 1808473481096
print(l2,id(l2))#[1, 2, 3, [22, 33], (1, 2, 3)] 1808473516296
print(id(l1[-1]),id(l2[-1]))#1808473473672 1808473473672
print(id(l1[-2]),id(l2[-2]))#1808472679432 1808472679432
#4.
l1 = [1, 2, 3, [22, 33]]
l2 = l1.copy()
l1[0] = 90
print(l1)#[90, 2, 3, [22, 33]]
print(l2)#[1, 2, 3, [22, 33]]
# 深copy
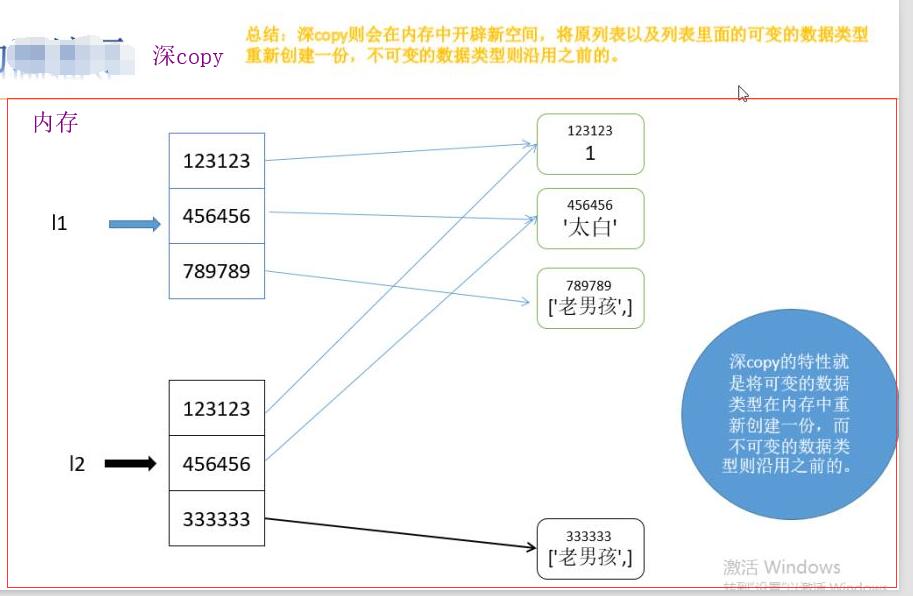
對於深copy來說,列表是在記憶體中重新創建的,列表中可變的數據類型是重新創建的,列表中的不可變的數據類型是公用的。
python對深copy做了優化,將不可變的數據類型沿用同一個。
import copy
l1 = [1, 2, 3, [22, 33]]
l2 = copy.deepcopy(l1)
print(id(l1))#2336066990856
print(id(l2))#2336066992136
l1[-1].append(666)
print(l1)#[1, 2, 3, [22, 33,666]]
print(l2)#[1, 2, 3, [22, 33]]
# 相關面試題;
【註意】***list切片是淺copy***
l1 = [1, 2, 3, [22, 33]]
l2 = l1[:]
l1[-1].append(666)
print(l1)#[1, 2, 3, [22, 33,666]]
print(l2)#[1, 2, 3, [22, 33,666]]
區分:看是否共用一個嵌套的可變數據類型list,dict
淺copy:嵌套的可變的數據類型(list dict)是同一個。
深copy:嵌套的可變的數據類型(list dict)不是同一個 。8.enumerate:枚舉
對於一個可迭代的(iterable)/可遍歷的對象(如列表、字元串),enumerate將其組成一個索引序列,利用它可以同時獲得索引和值。
# enumerate(iterable[, start])
l1 = ['a', 'b', 'c']
for i in enumerate(l1): # [(0, 'a'),(1, 'b'),(2, 'c')]
print(i)
# (0, 'a')
# (1, 'b')
# (2, 'c')
for i in enumerate(l1,start=100): #起始位置預設是0,可更改
print(i)
# (100, 'a')
# (101, 'b')
# (102, 'c')
li = ['alex','銀角','女神','egon','太白']
for i in enumerate(li):
print(i)
# (0, 'alex')
# (1, '銀角')
# (2, '女神')
# (3, 'egon')
# (4, '太白')
for index,name in enumerate(li,1):
print(index,name)
# 1 alex
# 2 銀角
# 3 女神
# 4 egon
# 5 太白
for index, name in enumerate(li, 100): # 起始位置預設是0,可更改
print(index, name)
# 100 alex
# # 101 銀角
# # 102 女神
# # 103 egon
# # 104 太白


