
這一篇筆記的mysql優化是註重於查詢優化,根據mysql的執行情況,判斷mysql什麼時候需要優化,關於資料庫開始階段的資料庫邏輯、物理結構的設計結構優化不是本文重點,下次再談 查看mysql語句的執行情況,判斷是否需要進行優化 以下分別通過java程式員可分析的前三個方面來討論mysql語句的查 ...
這一篇筆記的mysql優化是註重於查詢優化,根據mysql的執行情況,判斷mysql什麼時候需要優化,關於資料庫開始階段的資料庫邏輯、物理結構的設計結構優化不是本文重點,下次再談
查看mysql語句的執行情況,判斷是否需要進行優化
當感覺操作資料庫查詢語句速度變慢,不符合生產效率要求時,可按照以下步驟進行查看
1、 慢查詢的開啟與捕獲,查看可能是哪些SQL語句造成的查詢速度慢
2、 explain+SQL語句
3、 show profile分析SQL語句在伺服器內執行細節和生命周期情況
4、 通過以上三個步驟大致確定問題SQL之後,可聯繫運維人員或者DBA進行資料庫伺服器參數的調整優化以下分別通過java程式員可分析的前三個方面來討論mysql語句的查詢優化
一、慢查詢
慢查詢日誌是mysql的一個日誌記錄,可以用來記錄mysql語句執行時間超過指定的long_query_time的SQL語句,long_query_time的預設值是10s
慢查詢日誌預設情況下是不開啟的,因為將數據保存到日誌會對性能有一定影響,測試環境下可手動打開,但註意手動開啟之後只對本次啟動生效,mysql關閉之後重啟恢復預設狀態,要想持久生效要改變my.ini配置文件(Window系統下),其他系統變數也如此
可通過show varaibles like '%slow_query_log%'來查看日誌開啟情況
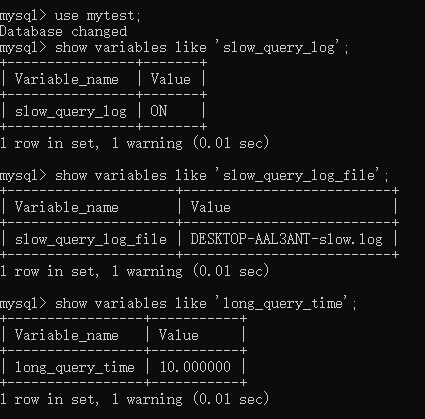
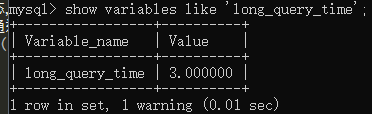
可以用set long_query_time = 3;語句來改變預設的閥值,然後我們可以用show varaiables like 'long_query_
time'來查看是否更改生效,若沒有生效,可嘗試重啟一下mysql客戶端即可
然後我們現在來測試一下,因為我們平時個人測試學習的資料庫及其簡單的SQL語句可能沒有造成很慢的查詢,我們可以採用 select sleep(time)來模擬測試
(這個函數類似於java線程中的sleep函數)
執行該函數之前slow.log文件:

執行sleep(4)函數,因為要讓你設置的這個time大於記錄到日誌裡面的時間閥值


可已看到這條慢查詢話費的具體時間是4.041230,也可以看到是哪個用戶在哪個資料庫操作的哪條具體SQL語句,我們開啟慢查詢日誌的目的就是找到這樣的造成查速度減慢的SQL語句,為第二步的explain提供基礎
mysqldumpslow日誌分析工具
在實際的資料庫使用過程中可能會有多條日誌記錄,數據複雜,人工分析費事費力,mysql提供了一個日誌分析工具mysqldumpslow
可以根據你設定的參數查詢出滿足條件的日誌記錄,方便查看
可用的參數有
-s, 是表示按照何種方式排序
排序方式有
c: 訪問計數
l: 鎖定時間
r: 返回記錄
t: 查詢時間
al:平均鎖定時間
ar:平均返回記錄數
at:平均查詢時間
-t, 是top n的意思,即為返回前面多少條的數據;
-g, 後邊可以寫一個正則匹配模式,大小寫不敏感的;示例
得到返回記錄集最多的10個SQL。
mysqldumpslow -s r -t 10 /database/mysql/mysql06_slow.log
得到訪問次數最多的10個SQL
mysqldumpslow -s c -t 10 /database/mysql/mysql06_slow.log
得到按照時間排序的前10條裡面含有左連接的查詢語句。
mysqldumpslow -s t -t 10 -g “left join” /database/mysql/mysql06_slow.log
另外建議在使用這些命令時結合 | 和more 使用 ,否則有可能出現刷屏的情況。
mysqldumpslow -s r -t 20 /mysqldata/mysql/mysql06-slow.log | more
二、explain+SQL語句
執行這個語句可以讓開發人員看到select語句執行的詳細信息,開發人員可以將上一步慢查詢中捕獲的慢查詢SQL語句進行分析,判斷查詢效率低的可能原因
可以幫助選擇更好的索引和寫出優化的查詢語句
使用explain我們可以得到以下信息
表的讀取順序
數據讀取操作的類型
哪些索引可以使用
哪些索引實際被使用
表之間的引用
每張表有多少行被優化器掃描
示例

我們來逐個分析各欄位
id:select查詢的序列號,代表的是select執行的順序,主要有以下三種情況
id相同時,則按照從上到下依次執行
id不同時,id值越大優先順序越高,越先被執行
id有相同有不同,則相同的id為一個組,不同組的id值按照規則二的優先順序執行,同組id則按照規則一依次執行 select_type:select查詢的類型,有以下常用幾種
simple:表示該查詢沒有子查詢和UNION連接查詢
primary:有子查詢時的最外層查詢
subquery:有子查詢時的內層嵌套查詢
derived:在from中包含的select就稱為derived(衍生) ,mysql會遞歸這些子查詢,把結果放在臨時表中
union:union的第二個或者最後一個
union result:union的結果 table:執行當前SQL語句用到的表
partitions:代表當前表所使用的分區
type:顯示使用了何種查詢,按照常見的幾種查詢最好到最壞排序為system>const>eq_ref>ref>range>index>all
system,const:mysql能夠對這部分進行查詢優化使能夠將其轉換成一個常量(system只返回一行,const有多行),如某一行的主鍵放入WHERE子句里的方式來選取此行的主鍵,MySQL就能將這個查詢轉換成一個常量。然後就可以高效的將表從聯接執行中移除
eq_ref:使用該索引查找,mysql知道最多返回一條數據,可以在使用主鍵或者唯一性索引查找時用到
ref:非唯一性索引的索引查找
range:範圍掃描,例如帶有between或者>,<,in等
index:掃描所有索引行
all:掃描所有數據行 possible_keys/kesy:代表可能用到的索引和實際用到的索引
key_len:在索引中使用的位元組數
ref:顯示了之前的表在key列記錄的索引中查找值所用的列或常量
rows:mysq估計的要找到滿足條件的行所需要掃描的行數
filtered:給出了一個百分比的值,這個百分比的值和rows列的值一起使用,可以估計出那些將要和QEP中的前一個表進行連接的行的數目。前一個表就是指id列的值比當前表的id小的表
extra:給出一些額外但重要的信息,常見重要的信息有
using index:使用了覆蓋索引,以避免掃描表(良好情況)
using filesort:索引創建數據排序方式不滿足要求,mysql在外部重新排序(嚴重,需要優化)
using temporary:mysql創建使用了臨時表來保存信息(嚴重,需要優化)
using where:使用了where
using join buffer:在獲取連接條件時沒有使用索引,並且需要連接緩衝區來存儲中間結果(需要增加索引進行優化) 這個裡面我們需要重點關註的屬性是type,keys,row,extra來判斷是否為一個良好的查詢
更多慄子及分析見下一篇文章索引詳解
三、show profile
show profile是mysql用來分析SQL查詢語句的資源使用情況的工具
使用方法:
1、 因為mysql這個功能預設是關閉的,所以先查看一下並開啟

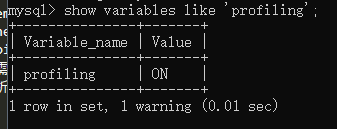
(與開啟慢查詢日誌類似,可能需要重啟mysql客戶端才能生效)
2、 我們執行一些測試的SQL語句之後運行show profiles語句
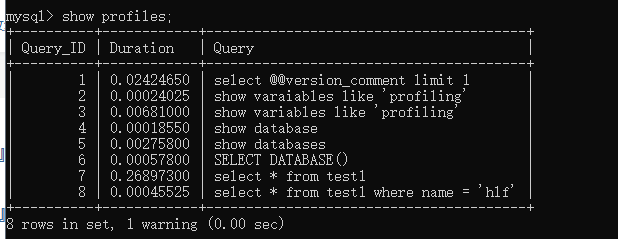
3、 我們可以選擇指定項指定SQL語句來分析

一般我們查看的屬性就是cpu和block io兩個模塊
註意:
若出現以下任意一個情況,都表示這是一個糟糕的SQL語句,需要優化
1、 convering heap to MyIsam查詢結果過大,記憶體不夠,需要記錄到磁碟上
2、 creating tmp table創建臨時表儲存數據,用完之後刪除
3、 copying to tmp table on disk將臨時表中的數據儲存到磁碟上
4、 locked


