
@[toc] 實戰內容 海倫女士一直使用線上約會網站尋找適合自己的約會對象。儘管約會網站會推薦不同的人選,但她並不是喜歡每一個人。經過一番總結,她發現自己交往過的人可以進行如下分類: 不喜歡的人 魅力一般的人 極具魅力的人 海倫收集約會數據已經有了一段時間,她把這些數據存放在文本文件datingTe ...
目錄
@
實戰內容
海倫女士一直使用線上約會網站尋找適合自己的約會對象。儘管約會網站會推薦不同的人選,但她並不是喜歡每一個人。經過一番總結,她發現自己交往過的人可以進行如下分類:
不喜歡的人
魅力一般的人
極具魅力的人海倫收集約會數據已經有了一段時間,她把這些數據存放在文本文件datingTestSet.txt中,每個樣本數據占據一行,總共有1000行。
海倫收集的樣本數據主要包含以下3種特征:
每年獲得的飛行常客里程數
玩視頻游戲所消耗時間百分比
每周消費的冰淇淋公升數任務:試建立一個分類器,使得在下次輸入數據後,程式可以幫助海倫預測海倫對此人的印象。
原著中,所有歸一化、kNN演算法,分類器都是作者自己寫的。代碼可以用於理解演算法原理,用於使用就沒有必要,而且代碼基於的版本是2.7,難以直接使用。
源代碼及其詳解可以參考以下鏈接:
機器學習實戰—k近鄰演算法(kNN)02-改進約會網站的配對效果
既然有了優秀的sklearn庫可以為我們提供現成的kNN函數,為什麼不直接調用它呢?這正是python較其他語言強大的所在呀!
用sklearn自帶庫實現kNN演算法分類
大致流程:
- 導入數據,列印數據的相關信息,初步瞭解數據
- 繪製圖像更直觀的分析數據
- 切分數據成測試集和訓練集,可以用sklearn自帶庫隨機切割,也可以將數據前半部分和後半部分切割,後者更有利於代入測試集人工檢驗
- 數據預處理,之後的代碼僅有歸一化
- 用sklearn自帶庫訓練演算法,然後打分正確率
- 完善分類器功能,允許後期輸入參數真正實現分類
可以參考以下鏈接,更詳細的瞭解sklearn自帶的kNN演算法做分類的流程:
用sklearn實現knn演算法的實現流程
以下是代碼(更多細節請參考附在最後的參考資料):
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn import preprocessing
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
#轉化文件格式 第一次執行後,在文件夾下會生成.csv文件,之後就不需要重覆執行這段代碼了
'''
txt = np.loadtxt('datingTestSet2.txt')
txtDf = pd.DataFrame(txt)
txtDf.to_csv('datingTestSet2.csv', index=False) #no index
'''
#load csv, learn more about it.
dataset = pd.read_csv('datingTestSet2.csv')
dataset.columns = ['miles', 'galons', 'percentage', 'label']
print(dataset.head())
print(dataset.dtypes)
print(np.unique(dataset['label']))
print(len(dataset))
#analyze our set through seaborn
# 繪製散點圖 第一次執行後,三個特征對結果的影響就會有個印象,後面也可以不再執行
'''
sns.lmplot(x='galons', y='percentage', data=dataset, hue='label',fit_reg=False)
sns.lmplot(x='miles', y='percentage', data=dataset, hue='label',fit_reg=False)
sns.lmplot(x='miles', y='galons', data=dataset, hue='label',fit_reg=False)
plt.show()
'''
#cut dataset randomly
'''
dataset_data = dataset[['miles', 'galons', 'percentage']]
dataset_label = dataset['label']
print(dataset_data.head())
data_train, data_test, label_train, label_test = train_test_split(dataset_data, dataset_label, test_size=0.2, random_state=0)
'''
#cut dataset
dataset_data = dataset[['miles', 'galons', 'percentage']]
dataset_label = dataset['label']
data_train = dataset.loc[:800,['miles', 'galons', 'percentage']] #我讓訓練集取前800個
print(data_train.head())
label_train = np.ravel(dataset.loc[:800,['label']])
data_test = dataset.loc[800:,['miles', 'galons', 'percentage']]
label_test = np.ravel(dataset.loc[800:,['label']])
#preprocessing, minmaxscaler
min_max_scaler = preprocessing.MinMaxScaler()
data_train_minmax = min_max_scaler.fit_transform(data_train)
data_test_minmax = min_max_scaler.fit_transform(data_test)
print(data_train_minmax)
#training and scoring
knn = KNeighborsClassifier(n_neighbors=15)
knn.fit(data_train_minmax,label_train)
score = knn.score(X=data_test_minmax,y=label_test,sample_weight=None)
print(score)
#completion
def classifyperson(): #此為手動輸入參數預測結果需要的函數
percentage = float(input('percentage of time spent playing video games?'))
ffMiles = float(input('frequent flier miles earned per year?'))
iceCream = float(input('liters of ice-cream consumed per year?'))
inArr = np.array([[percentage, ffMiles, iceCream]])
inArr_minmax = min_max_scaler.fit_transform(inArr)
return inArr_minmax
#inArr_minmax = classifyperson()
label_predict = knn.predict(data_test_minmax) #此代碼與之前人工切分數據集結合,用於人工校對正確率
print(label_predict)當k取15的時候,正確率試過來是最高的,能達到0.935
以下是測試集代入分類器後得到的結果,可以將其與文本文件里最後200個標簽一一對照一下,可以發現正確率確實還是蠻高的。
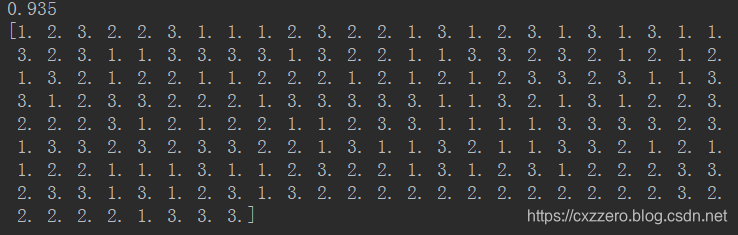
將內含非數值型的txt文件轉化為csv文件
原作中,作者已經將obj型標簽幫我們轉化成數值型了,因此在上面的代碼中,我們可以直接將轉化好的文件拿來用。但是如果要我們自己轉化數據類型,該怎麼轉化?
其實只需要將原作中的第一個函數略加改造即可。代碼如下:
# 將文本記錄轉換為NumPy的解析程式
def file2matrix(filename):
fr = open(filename)
#得到文件行數
arrayOfLines = fr.readlines()
numberOfLines = len(arrayOfLines)
#創建返回的Numpy矩陣
returnMat = np.zeros((numberOfLines,3))
classLabelVector = []
#解析文件數據到列表
index = 0
for line in arrayOfLines:
line = line.strip() #註釋1
listFromLine = line.split('\t') #註釋2
returnMat[index,:] = listFromLine[0:3]
classLabelVector.append(listFromLine[-1])
index += 1
return returnMat,classLabelVector
#調用函數,讀取數據
datingDataMat,datingLabels = file2matrix('datingTestSet.txt')
#拼接標簽和特征
datingDataMat_df = pd.DataFrame(datingDataMat)
datingLabels_df = pd.DataFrame(datingLabels)
txtDf = pd.concat([datingDataMat_df,datingLabels_df],axis=1) #橫向拼接
txtDf.to_csv('datingTestSet.csv', index=False) #這裡,datingTestSet.csv中的標簽是[largedoses, smalldoses, didn't like]
#讀取datingTestSet.csv
dataset = pd.read_csv('datingTestSet.csv')
dataset.columns = ['miles', 'galons', 'percentage', 'label']
print(dataset.head())得到的新DataFrame如下:
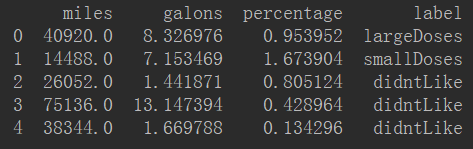
用sns.lmplot繪圖反映幾個特征之間的關係
以下列出了三個特征兩兩之間的關係(沒有列全),通過它們大致能感覺出三個特征值對結果的影響。
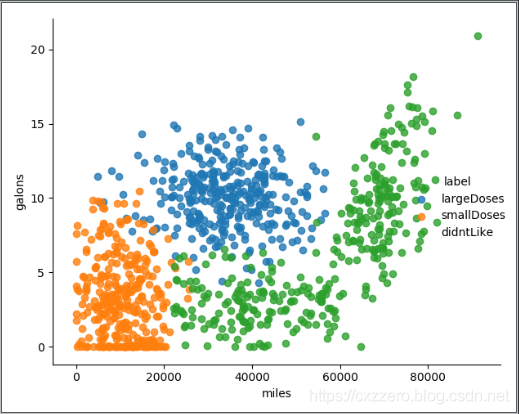
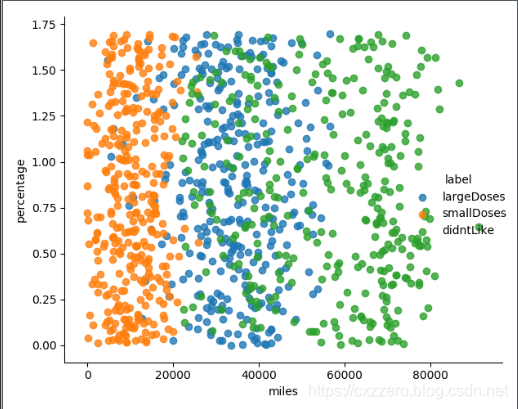
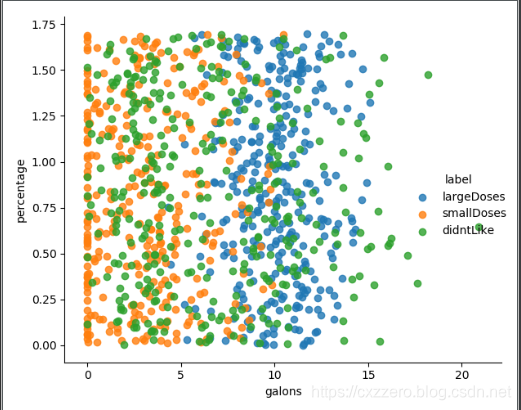
參考資料
如何把txt文件轉化為csv格式? (此辦法只適用於只有數值型的文件,或者說標簽已經被轉化為數值型了,如何將含object型的txt文件導入見後)
如何對DataFrame的列名重新命名?
pycharm如何用run執行不用console執行?
如何繪製散點圖?
如何改變DataFrame某一列的數據類型?
如何使用seaborn中的jointplot?
查看某一列有那些值?
jointplot沒有hue參數,有什麼其他函數可以代替嗎?
如何繪製子圖?
如何獲取Dataframe的行數和列數?
如何選取DataFrame列?官網
如何切分數據集?官網
如何用sklearn的train_test_split隨機切分數據集?
如何用sklearn自帶庫歸一化?官網
歸一化、標準化、正則化介紹及實例
如何使用sklearn中的knn演算法?
用sklearn實現knn演算法的實現流程
洗牌函數shuffle()和permutation()的區別是什麼?
如何使用with open()as filename?
如何用Python提取TXT數據轉化為DataFrame?
pandas dataframe的合併(append, merge, concat)


