
一、什麼是進程 進程(Process)是電腦中的程式關於某數據集合上的一次運行活動,是系統進行資源分配和調度的基本單位,是操作系統結構的基礎。在早期面向進程設計的電腦結構中,進程是程式的基本執行實體;在當代面向線程設計的電腦結構中,進程是線程的容器。程式是指令、數據及其組織形式的描述,進程是程 ...
一、什麼是進程
進程(Process)是電腦中的程式關於某數據集合上的一次運行活動,是系統進行資源分配和調度的基本單位,是操作系統結構的基礎。在早期面向進程設計的電腦結構中,進程是程式的基本執行實體;在當代面向線程設計的電腦結構中,進程是線程的容器。程式是指令、數據及其組織形式的描述,進程是程式的實體。---來自百度百科
狹義定義:進程是正在運行的程式的實例(an instance of a computer program that is being executed)。 廣義定義:進程是一個具有一定獨立功能的程式關於某個數據集合的一次運行活動。它是操作系統動態執行的基本單元,在傳統的操作系統中,進程既是基本的分配單元,也是基本的執行單元。 進程的概念主要有兩點:第一,進程是一個實體。每一個進程都有它自己的地址空間,一般情況下,包括文本區域(text region)、數據區域(data region)和堆棧(stack region)。文本區域存儲處理器執行的代碼;數據區域存儲變數和進程執行期間使用的動態分配的記憶體;堆棧區域存儲著活動過程調用的指令和本地變數。第二,進程是一個“執行中的程式”。程式是一個沒有生命的實體,只有處理器賦予程式生命時(操作系統執行之),它才能成為一個活動的實體,我們稱其為進程。二、程式和進程的關係
編寫完畢的代碼,在沒有運⾏的時候,稱之為程式 正在運⾏著的代碼,就成為進程 進程除了包含代碼以外還有需要運⾏的環境等所以和程式是有區別的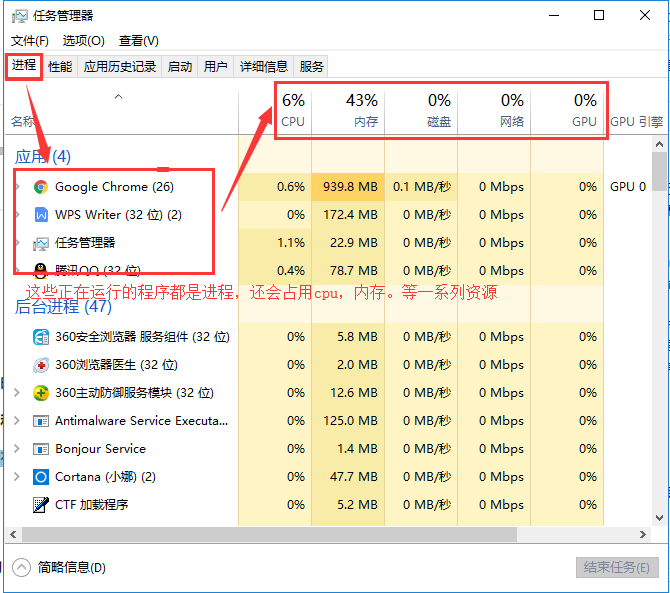
三、fork()
fork()函數只可以在Linux和Mac系統中,在windows中不可以用,所以它使用的也比較少#-*- coding:utf-8 -*-
import os
pid = os.fork()
if pid == 0:
print("子進程")
else:
print("主進程")
運行結果為:
主進程
子進程
getpid()、getppid()
import os
pid = os.fork()
if pid == 0:
print("我是子進程(%d),我的父進程(%d)"%(os.getpid(),os.getppid()))
else:
print("我是父進程(%d),我的子進程(%d)"%(os.getpid,pid))
print("父子進程都可以執行的代碼")
運行結果為:
我是父進程(4488),我的子進程(4491)
父子進程都可以執行的代碼
我是子進程(4491),我的父進程(4488)
父子進城都可以執行的代碼
說明:
- 程式執⾏到os.fork()時,操作系統會創建⼀個新的進程(⼦進程),然後複製⽗進程的所有信息到⼦進程中
- 然後⽗進程和⼦進程都會從fork()函數中得到⼀個返回值,在⼦進程中這個值⼀定是0,⽽⽗進程中是⼦進程的id號
- 普通的函數調⽤,調⽤⼀次,返回⼀次,但是fork()調⽤⼀次,返回兩次,因為操作系統⾃動把當前進程(稱為⽗進程)複製了⼀份(稱為⼦進程),然後,分別在⽗進程和⼦進程內返回
- ⼀個⽗進程可以fork出很多⼦進程,所以,⽗進程要記下每個⼦進程的ID,⽽⼦進程只需要調⽤getppid()就可以拿到⽗進程的ID
多個fork()
#-*- coding:utf-8 -*-
import os
pid1 = os.fork()
if pid1 == 0:#子進程1
print("1:我是第一個子進程%d,我的父進程是%d"%(os.getpid(),os.getppid()))
else:#父進程
print("2:我是父進程%d"%os.getpid())
pid2 = os.fork()
if pid2==0:
print("3:我是誰%d,我的父進程是%d"%(os.getpid(),os.getppid()))
else:
print("4:我是誰%d,我的父進程是%d"%(os.getpid(),os.getppid()))
運行結果為:
2:我是父進程3189
1:我是第一個子進程3190,我的父進程是3189
4:我是誰3190,我的父進程是3189
3:我是誰3191,我的父進程是3189
3:我是誰3192,我的父進程是3190
4:我是誰3189,我的父進程是991
說明:
- pid2開闢的進程將會被子進程1和父進程同時調用
- 當父線程調用pid2
- if pid2 == 0:會在創建一個子進程2,父進程是主進程
- else:及父線程本身,不會再創建進程
- 當子進程1調用pid2
- if pid2 ==0:會創建一個子子進程,父進程是子進程1
- else:即子線程1本身,不會再創建進程
其實上面的代碼就相當於:
#-*- coding:utf-8 -*-
import os
pid1 = os.fork()
if pid1 == 0:#子進程1
print("1:我是第一個子進程%d,我的父進程是%d"%(os.getpid(),os.getppid()))
else:#父進程
print("2:我是父進程%d"%os.getpid())
pid2 = os.fork()
if pid1 == 0:#子進程1
if pid2==0:#子子進程
print("3:我是誰%d,我的父進程是%d"%(os.getpid(),os.getppid()))
else:#子進程1
print("4:我是誰%d,我的父進程是%d"%(os.getpid(),os.getppid()))
else:#父進程
if pid2==0:#子進程2
print("3:我是誰%d,我的父進程是%d"%(os.getpid(),os.getppid()))
else:#父進程
print("4:我是誰%d,我的父進程是%d"%(os.getpid(),os.getppid()))
四、多進程使用全局變數
import os
import time
g_num = 100
ret = os.fork()
if ret == 0:
print("----process-1----")
g_num += 1
print("---process-1 g_num=%d---"%g_num)
else:
time.sleep(3)
print("----process-2----")
print("---process-2 g_num=%d---"%g_num)
運行結果為:
----process-1----
---process-1 g_num=101---
----process-2----
---process-2 g_num=100---
說明:多線程間全局變數是不共用的,每個線程裡面全局變數都是獨自一份的
五、multiprocessing
由於Python是跨平臺的,自然也應該提供一個跨平臺的多進程支持。multiprocessing模塊就是跨平臺版本的多進程模塊。
multiprocessing模塊提供了一個Process類來代表一個進程對象
#coding=utf-8
from multiprocessing import Process
import os
#子進程要執行的代碼
def sub_process(name):
print("這是在子進程中,name=%s,pid=%d"%(name,os.getpid()))
if __name__ == "__main__":
print("父進程:%d"%os.getpid())
p=Process(target=sub_process,args=("test",))
print("----子進程將要開啟----")
p.start()#開啟子進程
p.join()#用於等待子進程執行完畢再繼續往下執行
print("----子進程已經結束----")
運行結果為:
父進程:8344
----子進程將要開啟----
這是在子進程中,name=test,pid=9064
----子進程已經結束----
說明
- 創建子進程時,只需要傳入一個執行函數和函數的參數,創建一個Process實例,用start()方法啟動,這樣創建進程比fork()還要簡單。
- join()方法可以等待子進程結束後再繼續往下運行,通常用於進程間的同步。
Process語法結構如下:
Process([group [, target [, name [, args [, kwargs]]]]])
1 group:參數未使用,值始終為None 2 target:表示調用對象,即子進程要執行的任務 3 args:表示調用對象的位置參數元組,args=(1,2,'a',) 4 kwargs:表示調用對象的字典,kwargs={'name':'a','age':18} 5 name:為子進程的名稱
Process類常用方法:
1 start():啟動進程,並調用該子進程中的p.run()
2 run():進程啟動時運行的方法,正是它去調用target指定的函數,我們自定義類的類中一定要實現該方法
3 terminate():強制終止進程p,不會進行任何清理操作,如果p創建了子進程,該子進程就成了僵屍進程,使用該方法需要特別小心這種情況。如果p還保存了一個鎖那麼也將不會被釋放,進而導致死鎖
4 is_alive():如果p仍然運行,返回True
5 join([timeout]):主線程等待p終止(強調:是主線程處於等的狀態,而p是處於運行的狀態)。timeout是可選的超時時間,需要強調的是,p.join只能join住start開啟的進程,而不能join住run開啟的進程
Process類常用屬性:
1 daemon:預設值為False,如果設為True,代表p為後臺運行的守護進程,當p的父進程終止時,p也隨之終止,並且設定為True後,p不能創建自己的新進程,必須在p.start()之前設置
2 name:進程的名稱
3 pid:進程的pid
4 exitcode:進程在運行時為None、如果為–N,表示被信號N結束(瞭解即可)
5 authkey:進程的身份驗證鍵,預設是由os.urandom()隨機生成的32字元的字元串。這個鍵的用途是為涉及網路連接的底層進程間通信提供安全性,這類連接只有在具有相同的身份驗證鍵時才能成功(瞭解即可)
#coding=utf-8
from multiprocessing import Process
import time
import os
#兩個子進程將會調用的兩個方法
print("1:%d"%os.getpid())
def worker_1(interval):
print("worker_1:父進程(%s),當前進程(%s)"%(os.getppid(),os.getpid()))
t_start = time.time()
time.sleep(interval) #程式將會被掛起interval秒
t_end = time.time()
print("worker_1,執行時間為'%0.2f'秒"%(t_end - t_start))
print("2:%d"%os.getpid())
def worker_2(interval):
print("worker_2,父進程(%s),當前進程(%s)"%(os.getppid(),os.getpid()))
t_start = time.time()
time.sleep(interval)
t_end = time.time()
print("worker_2,執行時間為'%0.2f'秒"%(t_end - t_start))
#輸出當前程式的ID
print("3:%d"%os.getpid())
if __name__=='__main__':
print("4:%d"%os.getpid())
p1=Process(target=worker_1,args=(2,))
p2=Process(target=worker_2,name="Se7eN_HOU",args=(1,))
print("5:%d"%os.getpid())
p1.start()
p2.start()
#同時父進程仍然往下執行,如果p2進程還在執行,將會返回True
print("p2.is_alive=%s"%p2.is_alive())
#輸出p1和p2進程的別名和pid
print("p1.name=%s"%p1.name)
print("p1.pid=%s"%p1.pid)
print("p2.name=%s"%p2.name)
print("p2.pid=%s"%p2.pid)
print("6:%d"%os.getpid())
#join括弧中不攜帶參數,表示父進程在這個位置要等待p1進程執行完成後,再繼續執行下麵的語句,一般用於進程間的數據同步
p1.join()
print("p1.is_alive=%s"%p1.is_alive())
p2.join()
print("7:%d"%os.getpid())
運行結果為:
1:10452
2:10452
3:10452
4:10452
5:10452
p2.is_alive=True
p1.name=Process-1
p1.pid=10688
p2.name=Se7eN_HOU
p2.pid=2192
6:10452
1:2192
2:2192
3:2192
7:2192
worker_2,父進程(10452),當前進程(2192)
worker_2,執行時間為'1.00'秒
1:10688
2:10688
3:10688
7:10688
worker_1:父進程(10452),當前進程(10688)
worker_1,執行時間為'2.00'秒
p1.is_alive=False
7:10452
六、創建Process子類創建多進程
創建新的進程還能夠使用類的方式,可以自定義一個類,繼承Process類,每次實例化這個類的時候,就等同於實例化一個進程對象
from multiprocessing import Process
import time
import os
#創建一個類,繼承Process類
class My_Process(Process):
def __init__(self,interval):
#因為Process類本身也有__init__方法,這個子類相當於重寫了這個方法,
#但這樣就會帶來一個問題,我們並沒有完全的初始化一個Process類,所以就不能使用從這個類繼承的一些方法和屬性,
#最好的方法就是將繼承類本身傳遞給Process.__init__方法,完成這些初始化操作
Process.__init__(self)
self.interval = interval
#重寫了Process類的run()方法
def run(self):
print("子進程:%d,開始執行,父進程:%d"%(os.getpid(),os.getppid()))
t_start = time.time()
time.sleep(self.interval)
t_stop = time.time()
print("子進程:%d,執行結束,耗時%0.2f秒"%(os.getpid(),t_stop-t_start))
if __name__ == '__main__':
t_start = time.time()
print("當前進程是%d"%os.getpid())
p1 = My_Process(3)
p1.start()
p1.join()
t_stop = time.time()
print("當前進程%d執行結束,耗時:%0.2f"%(os.getpid(),t_stop-t_start))
運行結果為:
當前進程是9980
子進程:7084,開始執行,父進程:9980
子進程:7084執行結束,耗時3.00秒
當前進程9980執行結束,耗時:3.23
七、進程池Pool
當需要創建的子進程數量不多時,可以直接利用multiprocessing中的Process動態成生多個進程,但如果是上百甚至上千個目標,手動的去創建進程的工作量巨大,此時就可以用到multiprocessing模塊提供的Pool方法。
初始化Pool時,可以指定一個最大進程數,當有新的請求提交到Pool中時,如果池還沒有滿,那麼就會創建一個新的進程用來執行該請求;但如果池中的進程數已經達到指定的最大值,那麼該請求就會等待,直到池中有進程結束,才會創建新的進程來執行
from multiprocessing import Pool
import os
import time
import random
def worker(msg):
t_start = time.time()
print("%d進程開始執行%d"%(os.getpid(),msg))
#random.random()隨機生成0~1之間的浮點數
time.sleep(random.random()*2)
t_stop = time.time()
print(msg,"執行完畢,耗時%0.2f"%(t_stop-t_start))
if __name__ == '__main__':
po=Pool(3) #定義一個進程池,最大進程數3
for i in range(0,10):
#Pool.apply_async(要調用的目標,(傳遞給目標的參數元祖,))
#每次迴圈將會用空閑出來的子進程去調用目標
po.apply_async(worker,(i,))
print("----start----")
po.close() #關閉進程池,關閉後po不再接收新的請求
po.join() #等待po中所有子進程執行完成,必須放在close語句之後
print("-----end-----")
運行結果為:
----start----
4353進程開始執行0
4354進程開始執行1
4355進程開始執行2
2,執行完畢,耗時0.20
4355進程開始執行3
1,執行完畢,耗時1.19
4354進程開始執行4
4,執行完畢,耗時0.37
4354進程開始執行5
0,執行完畢,耗時1.57
4353進程開始執行6
5,執行完畢,耗時0.19
4354進程開始執行7
3,執行完畢,耗時1.63
4355進程開始執行8
6,執行完畢,耗時0.49
4353進程開始執行9
8,執行完畢,耗時0.75
7,執行完畢,耗時0.90
9,執行完畢,耗時0.63
-----end-----
multiprocessing.Pool常用函數解析:
- apply_async(func[, args[, kwds]]) :使用非阻塞方式調用func(並行執行,堵塞方式必須等待上一個進程退出才能執行下一個進程),args為傳遞給func的參數列表,kwds為傳遞給func的關鍵字參數列表;
- apply(func[, args[, kwds]]):使用阻塞方式調用func
- close():關閉Pool,使其不再接受新的任務;
- terminate():不管任務是否完成,立即終止;
- join():主進程阻塞,等待子進程的退出, 必須在close或terminate之後使用;
apply堵塞式
from multiprocessing import Pool
import os
import time
import random
def worker(msg):
t_start = time.time()
print("%d進程開始執行%d"%(os.getpid(),msg))
#random.random()隨機生成0~1之間的浮點數
time.sleep(random.random()*2)
t_stop = time.time()
print(msg,"執行完畢,耗時%0.2f"%(t_stop-t_start))
if __name__ == '__main__':
po=Pool(3) #定義一個進程池,最大進程數3
for i in range(0,10):
#Pool.apply_async(要調用的目標,(傳遞給目標的參數元祖,))
#每次迴圈將會用空閑出來的子進程去調用目標
po.apply(worker,(i,))
print("----start----")
po.close() #關閉進程池,關閉後po不再接收新的請求
po.join() #等待po中所有子進程執行完成,必須放在close語句之後
print("-----end-----")
運行結果為:
4400進程開始執行0
0,執行完畢,耗時1.89
4401進程開始執行1
1,執行完畢,耗時1.91
4402進程開始執行2
2,執行完畢,耗時1.64
4400進程開始執行3
3,執行完畢,耗時1.16
4401進程開始執行4
4,執行完畢,耗時1.85
4402進程開始執行5
5,執行完畢,耗時0.29
4400進程開始執行6
6,執行完畢,耗時0.19
4401進程開始執行7
7,執行完畢,耗時1.19
4402進程開始執行8
8,執行完畢,耗時0.61
4400進程開始執行9
9,執行完畢,耗時1.08
----start----
-----end-----
說明:通過運行結果可以看出來,阻塞式會等進程池中的進程都執行完畢了才會運行主進程的start和end的列印
八、進程間的通信-Queue
1. Queue的使用
可以使用multiprocessing模塊的Queue實現多進程之間的數據傳遞,Queue本身是一個消息列隊程式,首先用一個小實例來演示一下Queue的工作原理:
#-*- coding:utf-8 -*-
from multiprocessing import Queue
#創建一個Queue對象,最多可接受三條put消息
q = Queue(3)
q.put("消息1")
q.put("消息2")
print(q.full())
q.put("消息3")
print(q.full())
try:
q.put("消息4",True,2)
except :
print("消息隊列已滿,現有消息數量:%s"%q.qsize())
try:
q.put_nowait("消息5")
except :
print("消息隊列已滿,現有消息數量:%s"%q.qsize())
#推薦方式,先判斷消息隊列是否已滿,在寫入
if not q.full():
q.put_nowait("消息6")
#讀取消息時,先判斷消息隊列是否為空,在讀取
if not q.empty():
for i in range(q.qsize()):
print(q.get_nowait())
運行結果為:
False
True
消息隊列已滿,現有消息數量:3
消息隊列已滿,現有消息數量:3
消息1
消息2
消息3
說明
初始化Queue()對象時(例如:q=Queue()),若括弧中沒有指定最大可接收的消息數量,或數量為負值,那麼就代表可接受的消息數量沒有上限(直到記憶體的盡頭);
- Queue.qsize():返回當前隊列包含的消息數量;
- Queue.empty():如果隊列為空,返回True,反之False ;
- Queue.full():如果隊列滿了,返回True,反之False;
- Queue.get([block[, timeout]]):獲取隊列中的一條消息,然後將其從列隊中移除,block預設值為True;
1)如果block使用預設值,且沒有設置timeout(單位秒),消息列隊如果為空,此時程式將被阻塞(停在讀取狀態),直到從消息列隊讀到消息為止,如果設置了timeout,則會等待timeout秒,若還沒讀取到任何消息,則拋出"Queue.Empty"異常;
2)如果block值為False,消息列隊如果為空,則會立刻拋出"Queue.Empty"異常;
-
Queue.get_nowait():相當Queue.get(False);
-
Queue.put(item,[block[, timeout]]):將item消息寫入隊列,block預設值為True;
1)如果block使用預設值,且沒有設置timeout(單位秒),消息列隊如果已經沒有空間可寫入,此時程式將被阻塞(停在寫入狀態),直到從消息列隊騰出空間為止,如果設置了timeout,則會等待timeout秒,若還沒空間,則拋出"Queue.Full"異常;
2)如果block值為False,消息列隊如果沒有空間可寫入,則會立刻拋出"Queue.Full"異常;
- Queue.put_nowait(item):相當Queue.put(item, False);
2. Queue實例
我們以Queue為例,在父進程中創建兩個子進程,一個往Queue里寫數據,一個從Queue里讀數據:
from multiprocessing import Process
from multiprocessing import Queue
import os
import time
import random
#寫數據進程執行的代碼
def write(q):
for value in ["A","B","C"]:
print("Put %s to Queue "%value)
q.put(value)
time.sleep(random.random())
#讀取數據進程的代碼
def read(q):
while True:
if not q.empty():
value = q.get(True)
print("Get %s from Queue "%value)
time.sleep(random.random())
else:
break
if __name__ == '__main__':
#父進程創建Queue,並傳遞給各個子進程
q = Queue()
pw = Process(target = write,args=(q,))
pr = Process(target = read,args=(q,))
#啟動子進程pw,寫入
pw.start()
#等待pw結束
pw.join()
#啟動子進程pr,讀取
pr.start()
pr.join()
print("所有數據都寫入並且讀完")
運行結果為:
Put A to Queue
Put B to Queue
Put C to Queue
Get A from Queue
Get B from Queue
Get C from Queue
所有數據都寫入並且讀完
3. 進程池中的Queue
如果要使用Pool創建進程,就需要使用multiprocessing.Manager()中的Queue(),而不是multiprocessing.Queue(),否則會得到一條如下的錯誤信息:
RuntimeError: Queue objects should only be shared between processes through inheritance.
#coding=utf-8
from multiprocessing import Manager
from multiprocessing import Pool
import os
import time
import random
def reader(q):
print("reader啟動(%d),父進程為(%d)"%(os.getpid(),os.getppid()))
for i in range(q.qsize()):
print("reader從Queue獲取到的消息時:%s"%q.get(True))
def writer(q):
print("writer啟動(%d),父進程為(%d)"%(os.getpid(),os.getppid()))
for i in "Se7eN_HOU":
q.put(i)
if __name__ == '__main__':
print("-------(%d) Start-------"%os.getpid())
#使用Manager中的Queue來初始化
q = Manager().Queue()
po = Pool()
#使用阻塞模式創建進程,這樣就不需要在reader中使用死迴圈了,可以讓writer完全執行完成後,再用reader去讀取
po.apply(writer,(q,))
po.apply(reader,(q,))
po.close()
po.join()
print("-------(%d) End-------"%os.getpid())
運行結果為:
-------(880) Start-------
writer啟動(7744),父進程為(880)
reader啟動(7936),父進程為(880)
reader從Queue獲取到的消息時:S
reader從Queue獲取到的消息時:e
reader從Queue獲取到的消息時:7
reader從Queue獲取到的消息時:e
reader從Queue獲取到的消息時:N
reader從Queue獲取到的消息時:_
reader從Queue獲取到的消息時:H
reader從Queue獲取到的消息時:O
reader從Queue獲取到的消息時:U
-------(880) End-------


