
筆記記錄自林曉斌(丁奇)老師的《MySQL實戰45講》 (本篇內圖片均來自丁奇老師的講解,如有侵權,請聯繫我刪除) 18) --為什麼這些SQL語句邏輯相同,性能卻差異巨大? 本篇我們以三個例子來記錄。 案例一:條件欄位函數操作 一個交易系統中有這樣一個交易記錄表,假設現在已經記錄了從16年年初到1 ...
筆記記錄自林曉斌(丁奇)老師的《MySQL實戰45講》
(本篇內圖片均來自丁奇老師的講解,如有侵權,請聯繫我刪除)
18) --為什麼這些SQL語句邏輯相同,性能卻差異巨大?
本篇我們以三個例子來記錄。
案例一:條件欄位函數操作
mysql> CREATE TABLE `tradelog` ( `id` int(11) NOT NULL, `tradeid` varchar(32) DEFAULT NULL, `operator` int(11) DEFAULT NULL, `t_modified` datetime DEFAULT NULL, PRIMARY KEY (`id`), KEY `tradeid` (`tradeid`), KEY `t_modified` (`t_modified`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
一個交易系統中有這樣一個交易記錄表,假設現在已經記錄了從16年年初到18年年底的全部數據,需要統計發生在所有年份中7月份的交易記錄總數,你可能會這麼寫查詢語句:
mysql> select count(*) from tradelog where month(t_modified)=7;
由於查詢條件中的t_modified欄位上有索引,你就很放心的執行了,但是實際上執行地很慢。如果你接著這個問題查一查會發現,如果對欄位做了函數計算,就用不上索引了,這是MySQL的規定。那麼,為什麼呢?
我們前面介紹過了,MySQL是按照B+樹的數據結構來存放索引的,實際上t_modified這個欄位的索引示意圖如下:
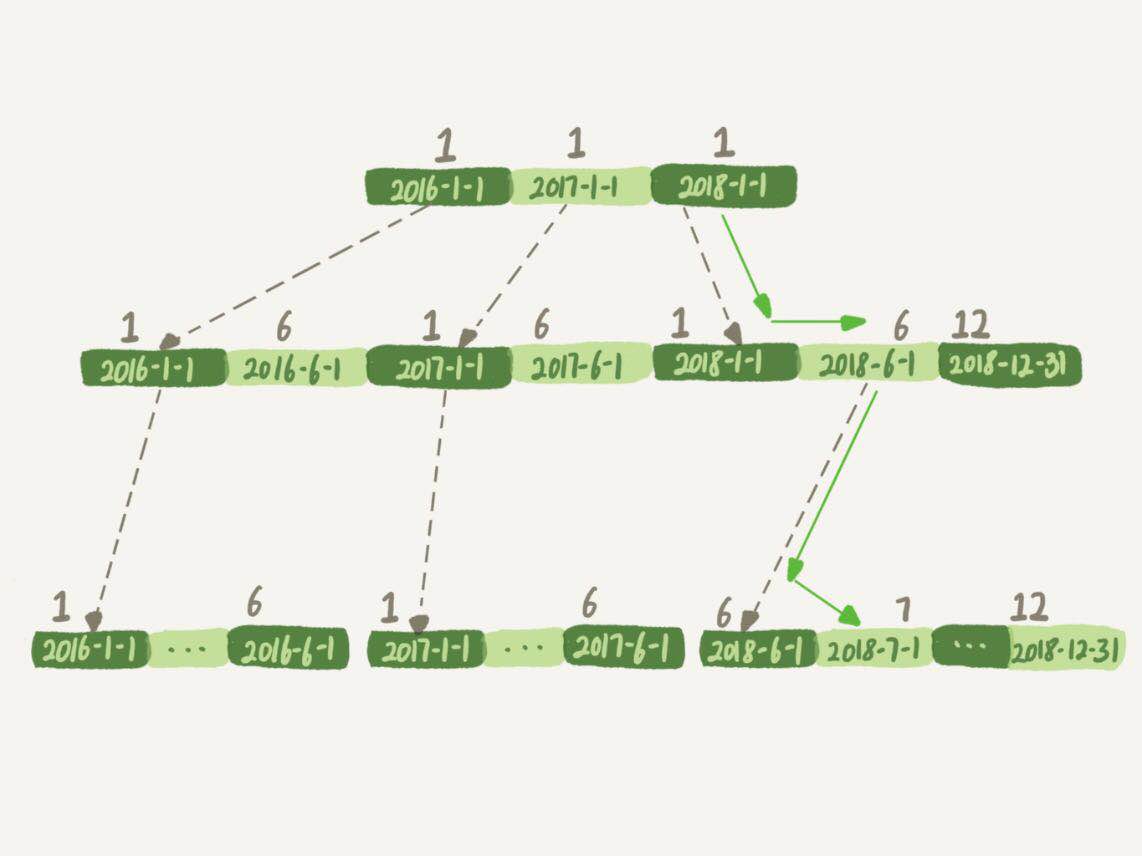
如果你的查詢條件是where t_modified = '2018-7-1',那麼引擎就會按照上面所示的方式快速定位到這條記錄,而如果你使用了month函數來計算的話,在這個索引樹的第一層引擎就不知道應該怎麼去尋找了。
實際上,B+樹提供這個快速定位能力,來源於同一層兄弟節點的有序性。
因此,對索引欄位做函數操作,可能會破壞索引值的有序性,因此優化器就決定放棄走樹搜索功能。需要註意的是,優化器並不是要放棄使用這個索引。在這個例子中,放棄了樹的搜索功能,優化器可以遍歷主鍵索引,也可以遍歷索引t_modified。優化器對比索引大小之後,發現t_modified更小,遍歷這個索引更快,因此最終還是會選擇索引t_modified。
上面這個例子對索引欄位使用了函數操作破壞所引值的有序性,因此查詢變慢,那麼我們應該怎麼優化一下呢?問題的關鍵是使用上索引,我們可以把語句改成基於欄位本身的範圍查詢,例如:
mysql> select count(*) from tradelog where
-> (t_modified >= '2016-7-1' and t_modified<'2016-8-1') or
-> (t_modified >= '2017-7-1' and t_modified<'2017-8-1') or
-> (t_modified >= '2018-7-1' and t_modified<'2018-8-1');
當然,如果你的系統上線更早,或者後面又插入了之後年份的數據,你就需要把其他年份補齊了。
month()函數破壞了有序性因此導致查詢變慢,但實際上,MySQL的優化器確實有“偷懶”行為。例如
select * from tradlog where id+1 = 10000;
雖然沒有改變有序性,但是優化器還是不能利用索引快速定位到id=9999這一行。你需要手動改動查詢條件為
id = 10000-1才行。
案例二:隱式類型轉換
我們還用剛纔那個交易記錄表舉例,來看看這條SQL語句:
mysql> select * from tradelog where tradeid=110717;
交易編號tradeid這個欄位本來就有索引,但是explain的結果卻顯示,這條語句需要走全表掃描。你可能也發現了,tradeid的欄位類型是varchar(32),而輸入的參數確實整型,索引需要做類型轉換。那麼現在這裡就有兩個問題了:
- 數據類型的轉換規則是什麼?
- 為什麼有數據類型轉換,就需要走全表索引掃描?
先來看第一個問題,你可能會說,資料庫里類型這麼多,這種數據類型規則更多,我記不住怎麼辦呢?有一個簡單地方法,看看select "10" > 9的結果:
- 如果規則是“將字元串轉成數字”,那麼就是數字比較,結果應該是1;
- 如果規則是“將數字轉成字元串”,那麼久做字元串比較,結果應該是0;
實際上上面這個查詢返回的結果是1,即“將字元串轉成數字”。這時,我們再來看看案例二剛開始的查詢語句
mysql> select * from tradelog where tradeid=110717;
對於優化器來說,這個語句就相當於
mysql> select * from tradelog where CAST(tradeid AS signed int) = 110717;
因此優化器放棄了走樹搜索的功能。
案例三: 隱式字元編碼轉換
假設系統里還有另一個表trade_detail用於記錄交易的操作細節。為了方便量化分析和復現,我們準備一些數據,如下:
mysql> CREATE TABLE `trade_detail` ( `id` int(11) NOT NULL, `tradeid` varchar(32) DEFAULT NULL, `trade_step` int(11) DEFAULT NULL, /* 操作步驟 */ `step_info` varchar(32) DEFAULT NULL, /* 步驟信息 */ PRIMARY KEY (`id`), KEY `tradeid` (`tradeid`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; insert into tradelog values(1, 'aaaaaaaa', 1000, now()); insert into tradelog values(2, 'aaaaaaab', 1000, now()); insert into tradelog values(3, 'aaaaaaac', 1000, now()); insert into trade_detail values(1, 'aaaaaaaa', 1, 'add'); insert into trade_detail values(2, 'aaaaaaaa', 2, 'update'); insert into trade_detail values(3, 'aaaaaaaa', 3, 'commit'); insert into trade_detail values(4, 'aaaaaaab', 1, 'add'); insert into trade_detail values(5, 'aaaaaaab', 2, 'update'); insert into trade_detail values(6, 'aaaaaaab', 3, 'update again'); insert into trade_detail values(7, 'aaaaaaab', 4, 'commit'); insert into trade_detail values(8, 'aaaaaaac', 1, 'add'); insert into trade_detail values(9, 'aaaaaaac', 2, 'update'); insert into trade_detail values(10, 'aaaaaaac', 3, 'update again'); insert into trade_detail values(11, 'aaaaaaac', 4, 'commit');
此時如果需要查詢id=2(tradeid = 'aaaaaaab')的交易的所有操作步驟信息,SQL語句可以這麼寫:
mysql> select d.* from tradelog l, trade_detail d where d.tradeid=l.tradeid and l.id=2;
這條語句的explain執行結果為:

這個結果表明:
- 第一行顯示優化器會先在交易記錄表tradelog上查到id=2的行,這個步驟用上了主鍵索引,rows=1表示只掃描了1行。
- 第二行key=NULL,表示沒有用上交易詳情表trade_detail上的tradeid索引,進行了全表掃描。
這個執行結果里,是從tradelog表中取tradeid欄位,再去trade_detail表裡查詢匹配欄位,因此,我們把tradelog稱為驅動表,把trade_detail稱為被驅動表,把tradeid稱為關聯欄位。接下來我們來看看explain結果表示的執行流程:
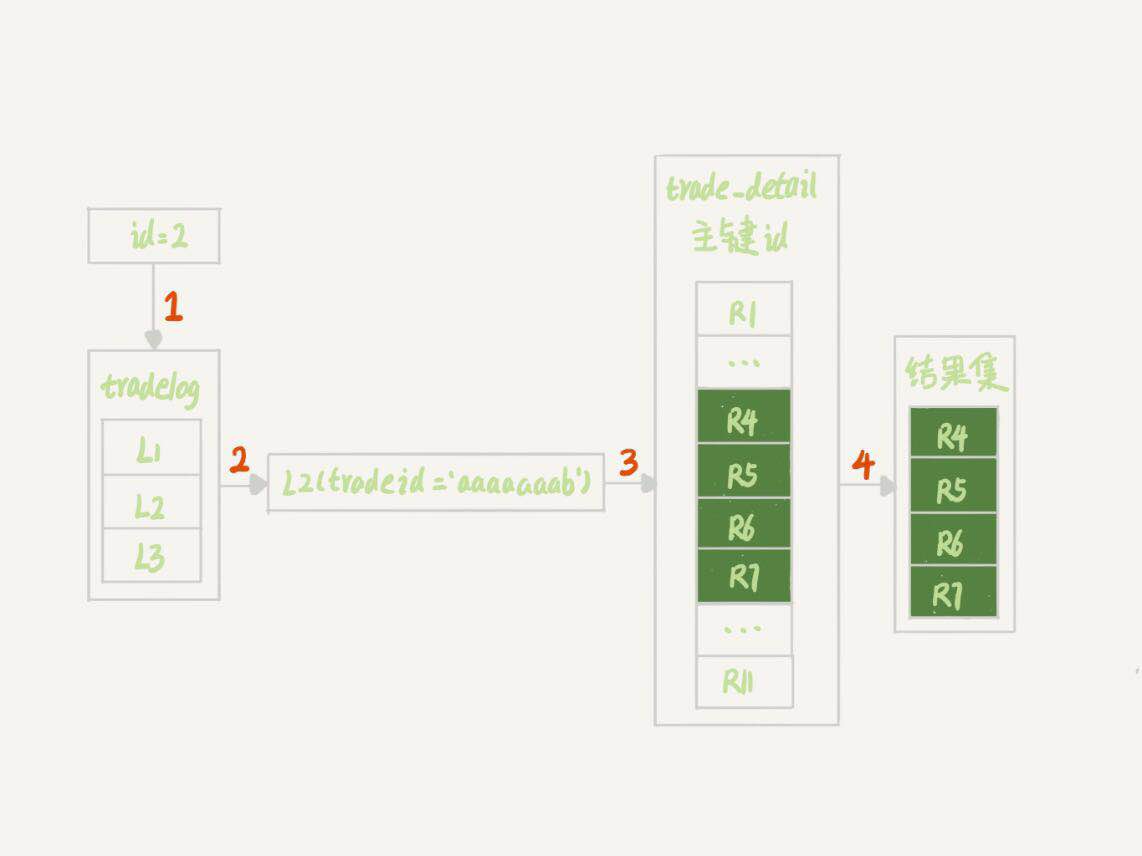
- 根據id在tradelog中找到L2這一行記錄。
- 從L2中取出tradeid欄位的值。
- 根據tradeid值到trade_detail表中查找條件匹配的行。explain的結果裡面第二行的key=NULL表示的就是,這個過程通過遍歷主鍵索引的方式,一個一個地判斷tradeid的值是否匹配。
到這裡你會發現,第三步中與我們期望的執行結果不符,因為trade_detail欄位上是有索引的,我們本來是希望通過使用tradeid索引來快速定位的。這時候如果你去問DBA同學,他可能會告訴你,因為這兩個表的字元集不同,一個是utf8,另一個是utf8mb4,所以做表連接查詢的時候用不上關聯欄位的索引。但是如果你再追問一下,為什麼字元集不同就用不上索引了呢?
如果說剛纔的執行結果問題是出在第三步,那麼如果單獨把這一步改成SQL語句的話,那就是:
mysql>select * from trade_detail where tradeid = $L2.tradeid.value;
其中,$L2.tradeid.value的字元集是utf8mb4。
參照前面的例子,你肯定想到了,字元集utf8mb4是utf8的超集,所以當這兩個類型的字元串是在做比較的時候,MySQL內部的操作是,先把utf8轉化成utf8mb4字元集,再做比較。也就是說,實際上這個語句等同於下麵這個寫法:
select * from trade_detail where CONVERT(traideid USING utf8mb4)=$L2.tradeid.value;
這就觸發了我們在案例一中的那種情況:對索引欄位做函數操作,優化器會放棄走樹搜索功能。
到這裡,你應該明白了,字元集不同只是條件之一,連接過程中要求在被驅動表的索引欄位上加函數操作,是直接導致對被驅動表做全表掃描的原因。
那麼這個語句我們應該怎麼去優化呢,一般有兩種作法:
- 直接把trade_detail的表的字元集也改成utf8mb4,這樣就沒有字元集轉換的問題了。
- 如果業務上不允許進行DDL的話,那就只能修改SQL語句了,你可以嘗試這麼寫:
mysql> select d.* from tradelog l , trade_detail d where d.tradeid=CONVERT(l.tradeid USING utf8) and l.id=2;
這裡我們主動改變了l.tradeid的字元集,避免了被驅動表上字元編碼的轉換。
今天這個三個例子,其實是在說同一件事。即:對索引欄位做函數操作,可能會破壞索引值的有序性,因此優化器就決定放棄走樹搜索功能。


