
概述 NewSQL日漸火熱,無論還是開源的TiDB,CockroachDB還是互聯網大廠的Spanner,Oceanbase都號稱NewSQL,也就是分散式資料庫。NewSQL的典型特征就是,支持SQL,支持事務,高性能,低成本,高可靠,強一致,易擴展,運維友好等。從NewSQL的演進來看,所謂Ne ...
概述
NewSQL日漸火熱,無論還是開源的TiDB,CockroachDB還是互聯網大廠的Spanner,Oceanbase都號稱NewSQL,也就是分散式資料庫。NewSQL的典型特征就是,支持SQL,支持事務,高性能,低成本,高可靠,強一致,易擴展,運維友好等。從NewSQL的演進來看,所謂NewSQL,可以簡單理解為NoSQL+傳統的關係型資料庫的結合,NoSQL強調分散式(高可用,可擴展),關係型資料庫則強調事務,SQL。正因為二者的疊加,所以需要把兩個領域的概念整合在一起,本文主要想把分散式資料庫中幾個基本概念講清楚。
一致性
資料庫和分散式系統中都有一致性概念,由於很多英文單詞對應的中文都是“一致性”,導致容易產生誤區。資料庫中的ACID,C是Consistency,這個C主要強調應用邏輯的一致性,比如應用定義的約束,包括外鍵等。分散式系統的CAP以及一致性協議,也稱為一致性。前者主要強調,讀是否能讀到最新,以及併發場景下操作執行的時序關係,主要包括線性一致性(linearizability),順序一致性(sequential consistency),因果一致性(causal consistency)等;後者主要強調“共識”,分散式中的多個節點對某個事情(選主,事務提交)達成一致,常見的共識演算法包括paxos協議,raft協議等。
線性一致性(linearizability)
簡單來說,線性一致性要求,第一,“寫後讀”,這裡寫和讀是兩個操作,如果寫操作在完成之後,讀才開始,讀要能讀到最新的數據,而且保證以後也能讀操作也都能讀到這個最新的數據。第二,所有操作的時序與真實物理時間一致。相對於“寫後讀”,第二點要求即使不相關的兩個操作,如果執行有先後順序,線性一致性要求最終執行的結果也需要滿足這個先後順序。比如,操作序列(寫A,讀A,寫B,讀B),那麼不僅,讀A,讀B能讀到最新A值和B值;而且要保證,如果讀B讀到最新值時,讀A一定也能讀到最新值,也就是需要保證執行時序與真實時序相同。第三點,如果兩個操作是併發的(比如讀A沒有結束時,寫B開始了),那麼這個併發時序不確定,但從最終執行的結果來看,要確保所有線程(進程,節點)看到的執行序列是一致的。
下圖對線性一致性有詳細的論述,來源於[6]

順序一致性(sequential consistency)
相比線性一致性,主要區別在於,對於物理上有先後順序的操作,是否要保證這個時序。具體而言,對於單個線程,操作的順序仍然要保留,對於多個線程(進程,節點),執行的事件的先後順序與物理時鐘順序不保證。但是要求,從執行結果來看,所有線程(進程,節點)看到的執行序列是一樣的。詳細定義來源於[6]

下圖的例子很好的區分了線性一致性和順序一致性。

對於(a),執行序列write(y,2),read(x,0),write(x,4),read(y,2),結果符合要求,但是從客戶端的角度來看,write(x,4)先於read(x,0)執行,但是read卻沒有讀到最新值。
對於(b),write(y,2)和read(y,2)有先後順序,也是符合“寫後讀”,所以是線性一致性。
對於(c), 有幾種可能:
1).write(x,4),read(y,0),write(y,2),read(x,0),x的寫後讀,不符合要求;
2).write(y,2),read(x,0),write(x,4),read(y,0),y的寫後讀,不符合要求。
所以既不符合線性一致性,也不符合順序一致性。
因果一致性(causal consistency)
相對於順序一致性,弱化了不相關操作是否需要保序。
對於b),p1和p2 w(x)是沒有先後關係的,因此誰先發生都是可以的。
從p3的視角來看,操作執行的序列是w(x,7),r(x,7),w(x,2),r(x,2),w(x,4);保證了“寫後讀”
從p4的視角來看,操作執行序列是w(x,2),w(x,4),r(x,4),w(x,7),r(x,7);保證了“寫後讀”
但是不同進程看到的執行序列不一樣,所以不符合順序一致性。

可串列化
上一篇文章講了資料庫中異常和隔離級別,實際上隔離級別是純粹資料庫領域的概念與分散式系統並沒有交集,比如讀未提交,讀提交,可重覆讀以及可串列化。對於資料庫而言,我們說Serializable,是說併發場景下,多個併發事務最終執行的序列與某個串列執行的序列相同(無事務併發,事務的執行沒有重疊)。那麼如何實現併發控制來達到可串列化調度。資料庫中對於同一對象的操作可能存在幾類衝突,包括讀寫衝突,寫寫衝突,寫讀衝突等,如果解決了這些衝突,也就實現了可串列化調度。實際上衝突可串列化調度是可串列調度的充分條件,並非必要條件,詳細展開可以看這篇blog,而我們實際的資料庫系統中實現可串列化調度也是解決衝突串列化問題。主要有兩種,一種是基於S2PL(Strict 2 Phrase Locking),事務操作過程中,對讀加讀鎖,對寫加寫鎖,事務提交時,才將鎖釋放,為了避免幻讀,還需要實現間歇鎖等;另外一種,是基於Snapshot的SSI隔離級別,這種實現與S2PL的主要區別在於,讀仍然採用快照讀,不加鎖,讀寫不互斥,為了實現可串列化調度,需要收集事務的讀寫操作信息,並判斷是否事務有相互依賴的情況(衝突成環),如有,則將衝突的事務回滾,實際上是first-commit-win原則,最後導致成環的事務會被回滾。具體可以參考論文:Serializable Isolation for Snapshot Databases,目前商業資料庫PG和CockroachDB都是實現了SSI隔離級別。而MySQL的InnoDB存儲引擎則是採用了S2PL實現了可串列化隔離級別。
線性一致性VS可串列化
前面分別介紹了分散式系統中的一致性以及資料庫中的可串列化隔離級別,分散式資料庫顯然是分散式系統,也是資料庫系統,那麼是否能做到線性一致性+可串列化,就是所謂的“Strong Consistency”。這個定義來源於Jepsen的一篇blog,具體可以看下圖。
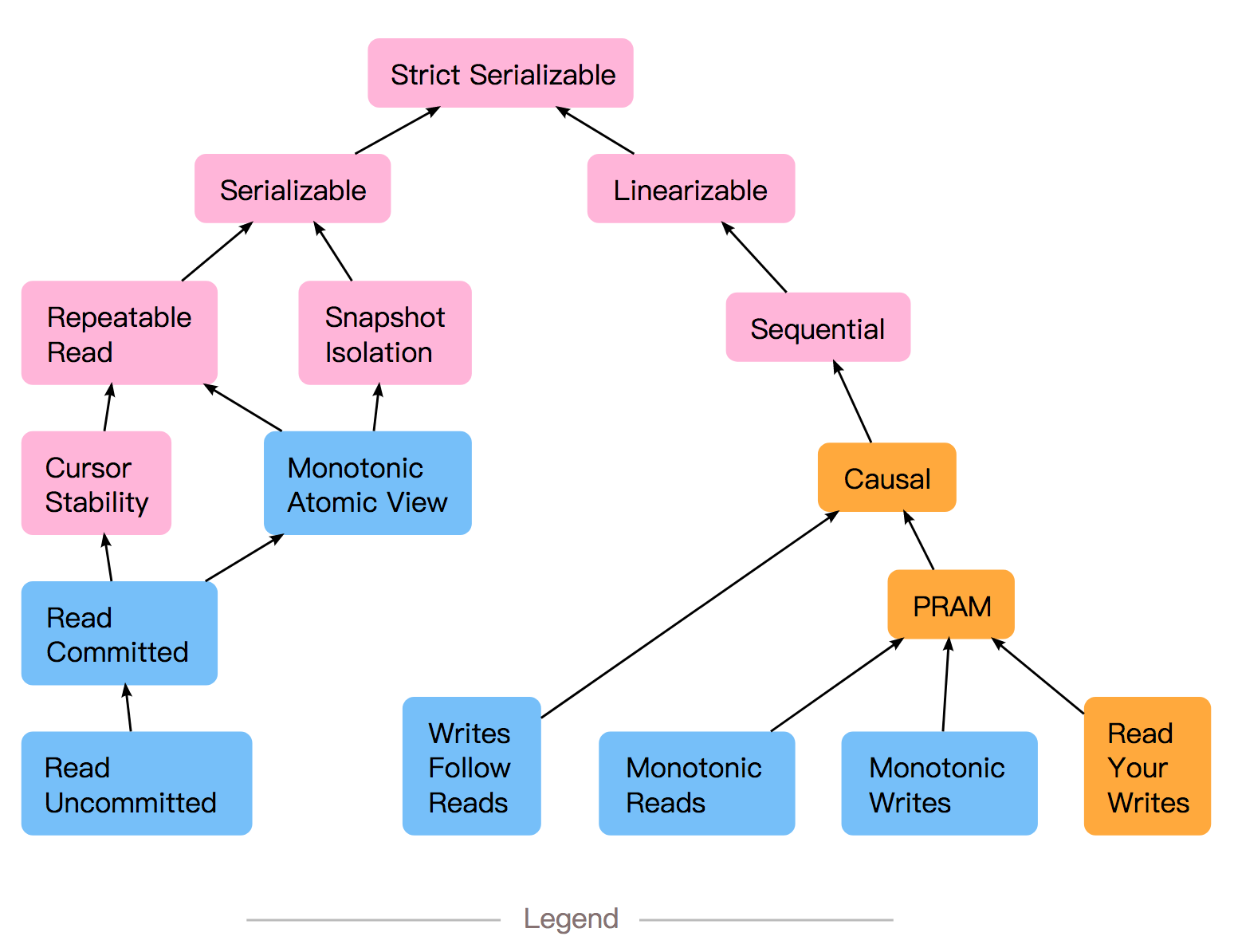
我們要註意到,討論線性一致性時,我們討論的粒度是一個操作,操作是否滿足先後關係;而討論隔離級別時,粒度是一個事務,事務是否與某個串列執行的結果相同。所以,這裡就比較特殊了,事務中包含了若幹讀寫操作,我們要保證讀到最新,是說後開啟的事務的讀能讀到之前的提交;還是事務中的每個讀都能讀到讀開始之前的提交(讀提交)。至少從DDIA(Designing Data-Intensive Application)[2]這本書介紹來看,應該是後者,所以它認為基於S2PL協議實現的可串列化,可以做到線性一致性兼得;而SSI由於是快照讀,導致讀不能讀到最新,所以不滿足線性一致性的。

資料庫要實現“線性一致性”,需要保證事務操作按全局時鐘的先後順序。對於寫而言,通過一個統一的地方分配時間戳,顯然先後執行的事務分配的時間戳也滿足先後關係。這裡實際上需要一個統一“全局時間源”,也就是業內常用的TSO(TimeStampOracle)方案,TSO能保證所有事務全局有序。對於讀而言,讀採用加鎖當前讀,也能保證讀到最新,所以結合S2PL可以兼得可串列化+線性一致性,也就是實現Strict Serializable。
External Consistency(外部一致性)
google Spanner論文還提到一個外部一致性的概念,

Spanner通過GPS+原子鐘保證了所有事務的寫有序,實現了類似TSO的功能,但是避免了TSO的單點可用性和性能問題。它提到External Consistency相比linearizability,主要是約束了非相關併發事務的提交順序與物理時鐘要保持一致,因為linearizability並不約束併發執行的操作。論文中沒有提到Spanner如何實現Serializable隔離級別,我猜測是類似SSI的實現,那麼仍然做不到Strict Serializable。
總結
分散式資料庫中的一致性概念有很多,但含義都不太一樣,ACID中的一致性主要強調應用邏輯的一致性,需要應用參與保證一致性,CAP中的一致性則主要強調多個副本的一致性,寫後讀是否能讀到最新,這裡面就衍生了幾種一致性,包括線性一致性,順序一致性,因果一致性等。資料庫有隔離級別的概念,對於可串列化隔離級別也要求順序,實際上與分散式系統的一致性沒有什麼關係,它更強調隔離,不強調事務執行的順序是否與真實執行先後順序保持一致。因此,資料庫可能實現了可串列化隔離級別,但是並不一定實現了線性一致性,比如基於SSI實現的可串列化就是這類系統。
參考文檔
[1].spanner論文
[2].https://jepsen.io/consistency
[3].http://www.bailis.org/blog/linearizability-versus-serializability/
[4].Spanner存儲層實現
[5].Serializable Isolation for Snapshot Databases
[6].《Distributed Computing,Principles, Algorithms, and Systems》
[7].《Designing Data-Intensive Applications》


