
6.5 事務實現原理之1:Redo Log 介紹事務怎麼用後,下麵探討事務的實現原理。事務有ACID四個核心屬性:A:原子性。事務要麼不執行,要麼完全執行。如果執行到一半,宕機重啟,已執行的一半要回滾回去。C:一致性。各種約束條件,比如主鍵不能為空、參照完整性等。I:隔離性。隔離性和併發性密切相關, ...
6.5 事務實現原理之1:Redo Log
介紹事務怎麼用後,下麵探討事務的實現原理。事務有ACID四個核心屬性:
A:原子性。事務要麼不執行,要麼完全執行。如果執行到一半,宕機重啟,已執行的一半要回滾回去。
C:一致性。各種約束條件,比如主鍵不能為空、參照完整性等。
I:隔離性。隔離性和併發性密切相關,因為如果事務全是串列的(第四個隔離級別),也不需要隔離。
D:持久性。這個很容易理解,一旦事務提交了,數據就不能丟。
在這四個屬性中,D比較容易,C主要是由上層的各種規則來約束,也相對簡單。而A和I牽涉併發問題、崩潰恢復的問題,將是討論的重點。
說到事務的實現原理,會追溯到ARIES演算法理論,ARIES(Algorithms for Recovery AndIsolation Expoliting Semantics)是20世紀90年代由IBM的幾位研究員提出的一個演算法集,主論文是ARIES: A TransactionRecovery Method Supporting Fine-Granularity Locking and Partial Rollbacks UsingWrite-Ahead Loggging。ARIES的思想影響深遠,現代的關係型資料庫(DB2、MySQL、InnoDB、SQL Server、Oracle)在事務實現的很多方面都吸收了該思想,在大學的教科書上如果講到事務的實現,也都會介紹AREIS方法。
接下來,就以InnoDB為背景,分析事務的ACID其中的三個屬性(A、I、D)是如何實現的。先從最簡單的D開始(I/O問題),然後是A,最後討論I。
6.5.1 Write-Ahead
一個事務要修改多張表的多條記錄,多條記錄分佈在不同的Page裡面,對應到磁碟的不同位置。如果每個事務都直接寫磁碟,一次事務提交就要多次磁碟的隨機I/O,性能達不到要求。怎麼辦呢?不寫磁碟,在記憶體中進行事務提交。然後再通過後臺線程,非同步地把記憶體中的數據寫入到磁碟中。但有個問題:機器宕機,記憶體中的數據還沒來得及刷盤,數據就丟失了。
為此,就有了Write-aheadLog的思路:先在記憶體中提交事務,然後寫日誌(所謂的Write-ahead Log),然後後臺任務把記憶體中的數據非同步刷到磁碟。日誌是順序地在尾部Append,從而也就避免了一個事務發生多次磁碟隨機I/O的問題。明明是先在記憶體中提交事務,後寫的日誌,為什麼叫作Write-Ahead呢?這裡的Ahead,其實是指相對於真正的數據刷到磁碟,因為是先寫的日誌,後把記憶體數據刷到磁碟,所以叫Write-Ahead Log。
記憶體操作數據 +Write-Ahead Log的這種思想非常普遍,後面講LSM樹的時候,還會再次提到這個思想。在多備份一致性中,複製狀態機的模型也是基於此。
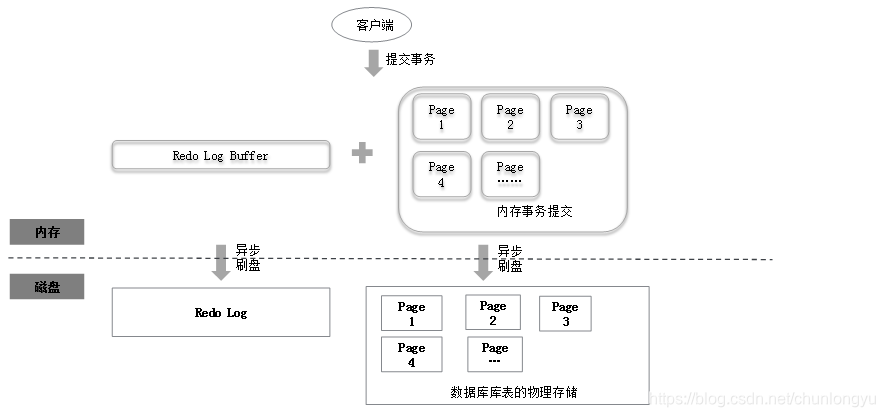
具體到InnoDB中,Write-Ahead Log是Redo Log。在InnoDB中,不光事務修改的資料庫表數據是非同步刷盤的,連Redo Log的寫入本身也是非同步的。如圖6-7所示,在事務提交之後,Redo Log先寫入到記憶體中的Redo Log Buffer中,然後非同步地刷到磁碟上的Redo Log。
為此,InnoDB有個關鍵的參數innodb_flush_log_at_trx_commit控制Redo Log的刷盤策略,該參數有三個取值:
0:每秒刷一次磁碟,把Redo Log Buffer中的數據刷到Redo Log(預設為0)。
1:每提交一個事務,就刷一次磁碟(這個最安全)。
2:不刷盤。然後根據參數innodb_flush_log_at_timeout設置的值決定刷盤頻率。
很顯然,該參數設置為0或者2都可能丟失數據。設置為1最安全,但性能最差。InnoDB設置此參數,也是為了讓應用在數據安全性和性能之間做一個權衡。
圖6-7 Redo Log的非同步刷盤示意圖
6.5.2 Redo Log的邏輯與物理結構
知道了Redo Log的基本設計思想,下麵來看Redo Log的詳細結構。
從邏輯上來講,日誌就是一個無限延長的位元組流,從資料庫安裝好並啟動的時間點開始,日誌便源源不斷地追加,永無結束。
但從物理上來講,日誌不可能是一個永不結束的位元組流,日誌的物理結構和邏輯結構,有兩個非常顯著的差異點:
(1)磁碟的讀取和寫入都不是按一個個位元組來處理的,磁碟是“塊”設備,為了保證磁碟的I/O效率,都是整塊地讀取和寫入。對於Redo Log來說,就是Redo Log Block,每個Redo Log Block是512位元組。為什麼是512位元組呢?因為早期的磁碟,一個扇區(最細粒度的磁碟存儲單位)就是存儲512位元組數據。
(2)日誌文件不可能無限制膨脹,過了一定時期,之前的歷史日誌就不需要了,通俗地講叫“歸檔”,專業術語是Checkpoint。所以Redo Log其實是一個固定大小的文件,迴圈使用,寫到尾部之後,回到頭部覆寫(實際Redo Log是一組文件,但這裡就當成一個大文件,不影響對原理的理解)。之所以能覆寫,因為一旦Page數據刷到磁碟上,日誌數據就沒有存在的必要了。
圖6-8展示了Redo Log邏輯與物理結構的差異,LSN(Log Sequence Number)是邏輯上日誌按照時間順序從小到大的編號。在InnoDB中,LSN是一個64位的整數,取的是從資料庫安裝啟動開始,到當前所寫入的總的日誌位元組數。實際上LSN沒有從0開始,而是從8192開始,這個是InnoDB源代碼裡面的一個常量LOG_START_LSN。因為事務有大有小,每個事務產生的日誌數據量是不一樣的,所以日誌是變長記錄,因此LSN是單調遞增的,但肯定不是呈單調連續遞增。
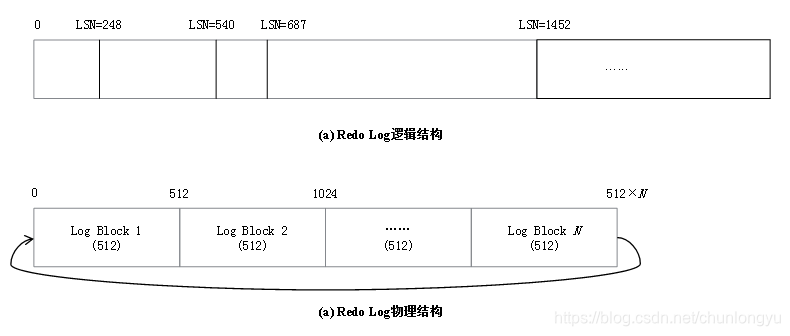
圖6-8 Redo Log邏輯結構與物理結構的差異
物理上面,一個固定的文件大小,每512個位元組一個Block,迴圈使用。顯然,很容易通過LSN換算出所屬的Block。反過來,給定Redo Log,也很容易算出第一條日誌在什麼位置。假設在Redo Log中,從頭到尾所記錄的LSN依次如下所示:
(200,289,378,478,30,46,58,69,129)
很顯然,第1條日誌是30,最後1條日誌是478,30以前的已經被覆蓋。
6.5.3 Physiological Logging
知道了Redo Log的整體結構,下麵進一步來看每個Log Block裡面Log的存儲格式。這個問題很關鍵,是資料庫事務實現的一個核心點。
(1)記法1。類似Binlog的statement格式,記原始的SQL語句,insert/delete/update。
(2) 記法2。類似Binlog的RAW格式,記錄每張表的每條記錄的修改前的值、修改後的值,類似(表,行,修改前的值,修改後的值)。
(3) 記法3。記錄修改的每個Page的位元組數據。由於每個Page有16KB,記錄這16KB里哪些部分被修改了。一個Page如果被修改了多個地方,就會有多條物理日誌,如下所示:
(Page ID,offset1,len1,改之前的值,改之後的值)
(Page ID,offset2,len2,改之前的值,改之後的值)
前兩種記法都是邏輯記法;第三種是物理記法。Redo Log採用了哪種記法呢?它採用了邏輯和物理的綜合體,就是先以Page為單位記錄日誌,每個Page裡面再採取邏輯記法(記錄Page裡面的哪一行被修改了)。這種記法有個專業術語,叫PhysiologicalLogging。
要搞清楚為什麼要採用PhysiologicalLogging,就得知道邏輯日誌和物理日誌的對應關係:
(1)一條邏輯日誌可能產生多個Page的物理日誌。比如往某個表中插入一條記錄,邏輯上是一條日誌,但物理上可能會操作兩個以上的Page?為什麼呢,因為一個表可能有多個索引,每個索引都是一顆B+樹,插入一條記錄,同時更新多個索引,自然可能修改多個Page。
如果Redo Log採用邏輯日誌的記法,一條記錄牽涉的多個Page寫到一半系統宕機了,要恢復的時候很難知道到底哪個Page寫成功了,哪個失敗了。
(2)即使1條邏輯日誌只對應一個Page,也可能要修改這個Page的多個地方。因為一個Page裡面的記錄是用鏈表串聯的,所以如果在中間插入一條記錄,不僅要插入數據,還要修改記錄前後的鏈表指針。對應到Page就是多個位置要修改,會產生多條物理日誌。
所以純粹的邏輯日誌宕機後不好恢復;物理日誌又太大,一條邏輯日誌就可能對應多條物理日誌。Physiological Logging綜合了兩種記法的優點,先以Page為單位記錄日誌,在每個Page裡面再採用邏輯記法。
6.5.4 I/O寫入的原子性(Double Write)
要實現事務的原子性,先得考慮磁碟I/O的原子性。一個LogBlock是512個位元組。假設調用操作系統的一次Write,往磁碟上寫入一個Log Block(512個位元組),如果寫到一半機器宕機後再重啟,請問寫入成功的位元組數是0,還是[0,512]之間的任意一個數值?
這個問題的答案並不唯一,可能與操作系統底層和磁碟的機制有關,如果底層實現了512個位元組寫入的原子性,上層就不需要做什麼事情;否則,在上層就需要考慮這個問題。假設底層沒有保證512個位元組的原子性,可以通過在日誌中加入checksum解決。通過checksum能判斷出宕機之後重啟,一個Log Block是否完整。如果不完整,就可以丟棄這個LogBlock,對日誌來說,就是做截斷操作。
除了日誌寫入有原子性問題,數據寫入的原子性問題更大。一個Page有16KB,往磁碟上刷盤,如果刷到一半系統宕機再重啟,請問這個Page是什麼狀態?在這種情況下,Page既不是一個髒的Page,也不是一個乾凈的Page,而是一個損壞的Page。既然已經有Redo Log了,不能用Redo Log恢復這個Page嗎?
因為Redo Log也恢復不了。因為Redo Log是Physiological Logging,裡面只是一個對Page的修改的邏輯記錄,Redo Log記錄了哪個地方修改了,但不知道哪個地方損壞了。另外,即使為這個Page加了checksum,也只能判斷出Page損壞了,只能丟棄,但無法恢複數據。有兩個解決辦法:
(1)讓硬體支持16KB寫入的原子性。要麼寫入0個位元組,要麼16KB全部成功。
(2)Doublewrite。把16KB寫入到一個臨時的磁碟位置,寫入成功後再拷貝到目標磁碟位置。
這樣,即使目標磁碟位置的16KB因為宕機被損壞了,還可以用備份去恢復。
Redo Log的原理比較複雜,在接下來的1篇中,將接著這個話題繼續探討。
後記: 本文節選自作者書籍《軟體架構設計:大型網站技術架構與業務架構融合之道》。
作者微信公眾號:架構之道與術。公眾號底部菜單有書友群可以加入,與作者和其他讀者進行深入討論。也可以在京東、天貓上購買紙質書籍。


