
本文節選自《軟體架構設計:大型網站技術架構與業務架構融合之道》第6.3章節。 作者微信公眾號: 架構之道與術。進入後,可以加入書友群,與作者和其他讀者進行深入討論。也可以在京東、天貓上購買紙質書。 關係型資料庫在查詢方面有一些重要特性,是KV型的資料庫或者緩存所不具備的,比如:(1)範圍查詢。(2) ...
本文節選自《軟體架構設計:大型網站技術架構與業務架構融合之道》第6.3章節。
作者微信公眾號: 架構之道與術。進入後,可以加入書友群,與作者和其他讀者進行深入討論。也可以在京東、天貓上購買紙質書。
關係型資料庫在查詢方面有一些重要特性,是KV型的資料庫或者緩存所不具備的,比如:
(1)範圍查詢。
(2)首碼匹配模糊查詢。
(3)排序和分頁。
這些特性的支持,要歸功於B+樹這種數據結構。下麵來分析B+樹是如何支持這些查詢特性的。
6.3.1 B+樹邏輯結構
圖6-1展示了資料庫的主鍵對應的B+樹的邏輯結構,這個結構有幾個關鍵特征:
(1)在葉子節點一層,所有記錄的主鍵按照從小到大的順序排列,並且形成了一個雙向鏈表。葉子節點的每一個Key指向一條記錄。
(2)非葉子節點取的是葉子節點裡面Key的最小值。這意味著所有非葉子節點的Key都是冗餘的葉子節點。同一層的非葉子節點也互相串聯,形成了一個雙向鏈表。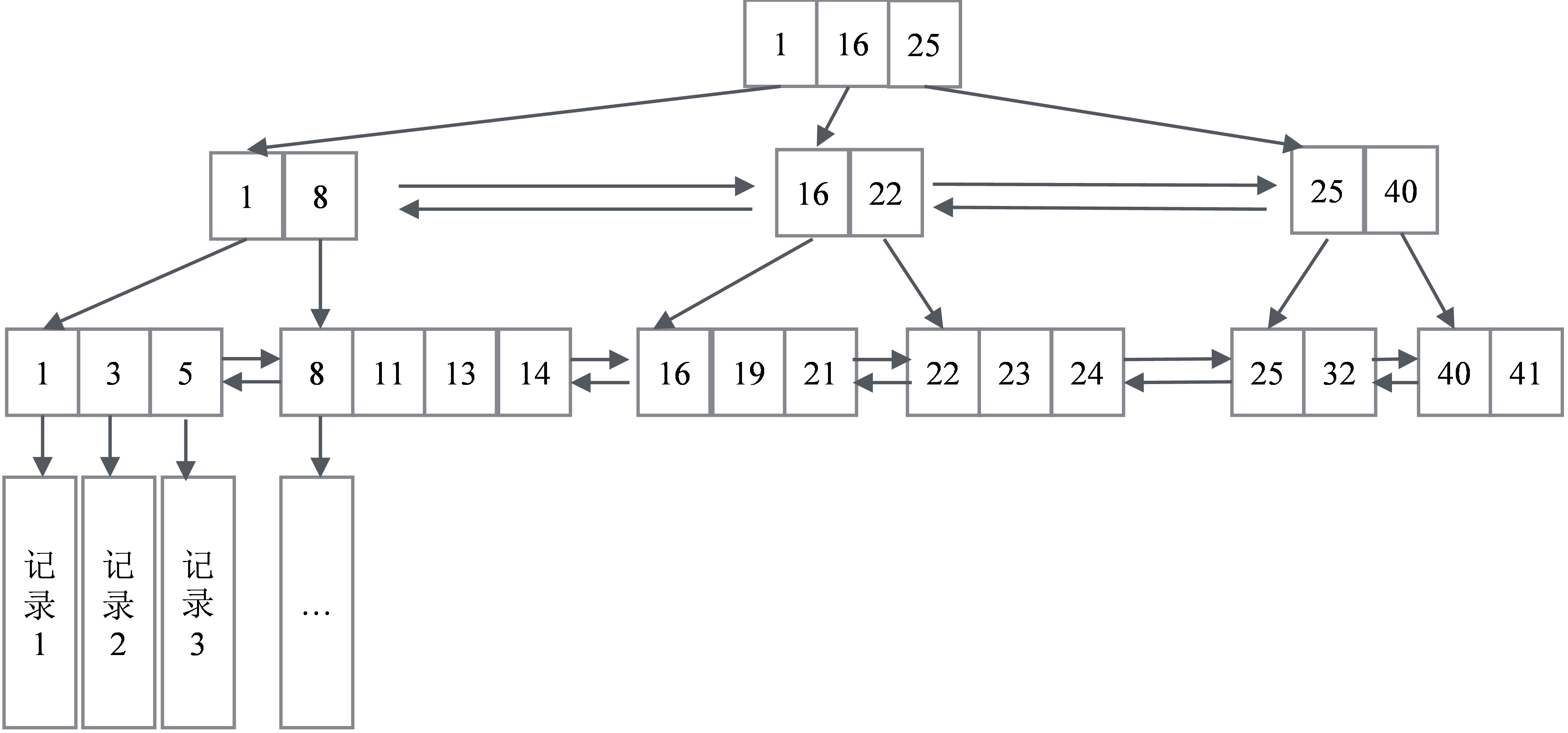
圖6-1 資料庫的主鍵對應的B+樹的邏輯結構
基於這樣一個數據結構,要實現上面的幾個特性就很容易了:
(1)範圍查詢:比如要查主鍵在[1,17]之間的記錄。二次查詢,先查找1所在的葉子節點的記錄位置,再查找17所在的葉子節點記錄的位置(就是16所處的位置),然後順序地從1遍歷鏈表直到16所在的位置。
(2)首碼匹配模糊查詢。假設主鍵是一個字元串類型,要查詢where Key like abc%,其實可以轉化成一個範圍查詢Key in [abc,abcz]。當然,如果是尾碼匹配模糊查詢,或者諸如where Key like %abc%這樣的中間匹配,則沒有辦法轉化成範圍查詢,只能挨個遍歷。
(3)排序與分頁。葉子節點天然是排序好的,支持排序和分頁。
另外,基於B+樹的特性,會發現對於offset這種特性,其實是用不到索引的。比如每頁顯示10條數據,要展示第101頁,通常會寫成select xxx where xxx limit 1000, 10,從offset = 1000的位置開始取10條。
雖然只取了10條數據,但實際上資料庫要把前面的1000條數據都遍歷才能知道offset = 1000的位置在哪。對於這種情況,合理的辦法是不要用offset,而是把offset = 1000的位置換算成某個max_id,然後用where語句實現,就變成了select xxx where xxx and id > max_id limit 10,這樣就可以利用B+樹的特性,快速定位到max_id所在的位置,即是offset=1000所在的位置。
6.3.2 B+樹物理結構
上面的樹只是一個邏輯結構,最終要存儲到磁碟上。下麵就以MySQL中最常用的InnoDB引擎為例,看一下如何實現B+樹的存儲。
對於磁碟來說,不可能一條條地讀寫,而都是以“塊”為單位進行讀寫的。InnoDB預設定義的塊大小是16KB,通過innodb_page_size參數指定。這裡所說的“塊”,是一個邏輯單位,而不是指磁碟扇區的物理塊。塊是InnoDB讀寫磁碟的基本單位,InnoDB每一次磁碟I/O,讀取的都是16KB的整數倍的數據。無論葉子節點,還是非葉子節點,都會裝在Page里。InnoDB為每個Page賦予一個全局的32位的編號,所以InnoDB的存儲容量的上限是64TB(2316KB)。
16KB是一個什麼概念呢?如果用來裝非葉子節點,一個Page大概可以裝1000個Key(16K,假設Key是64位整數,8個位元組,再加上各種其他欄位),意味著B+樹有1000個分叉;如果用來裝葉子節點,一個Page大概可以裝200條記錄(記錄和索引放在一起存儲,假設一條記錄大概100個位元組)。基於這種估算,一個三層的B+樹可以存儲多少數據量呢?如圖6-2所示。
第一層:一個節點是一個Page,裡面存放了1000個Key,對應1000個分叉。
第二層:1000個節點,1000個Page,每個Page裡面裝1000個Key。
第三層:10001000個節點(Page),每個Page裡面裝200條記錄,即是10001000200 = 2億條記錄,總容量是16KB10001000,約16GB。
把第一層和第二層的索引全裝入記憶體里,即(1+1000)16KB,也即約16MB的記憶體。三層B+樹就可以支撐2億條記錄,並且一次基於主鍵的等值查詢,只需要一次I/O(讀取葉子節點)。由此可見B+樹的強大!
基於Page,最終整個B+樹的物理存儲類似圖6-3所示。
Page與Page之間組成雙向鏈表,每一個Page頭部有兩個關鍵欄位:前一個Page的編號,後一個Page的編號。Page裡面存儲一條條的記錄,記錄之間用單向鏈表串聯,最終所有的記錄形成圖6-1所示的雙向鏈表的邏輯結構。對於記錄來說,定位到了Page,也就定位到了Page裡面的記錄。因為Page會一次性讀入記憶體,同一個Page裡面的記錄可以在記憶體中順序查找。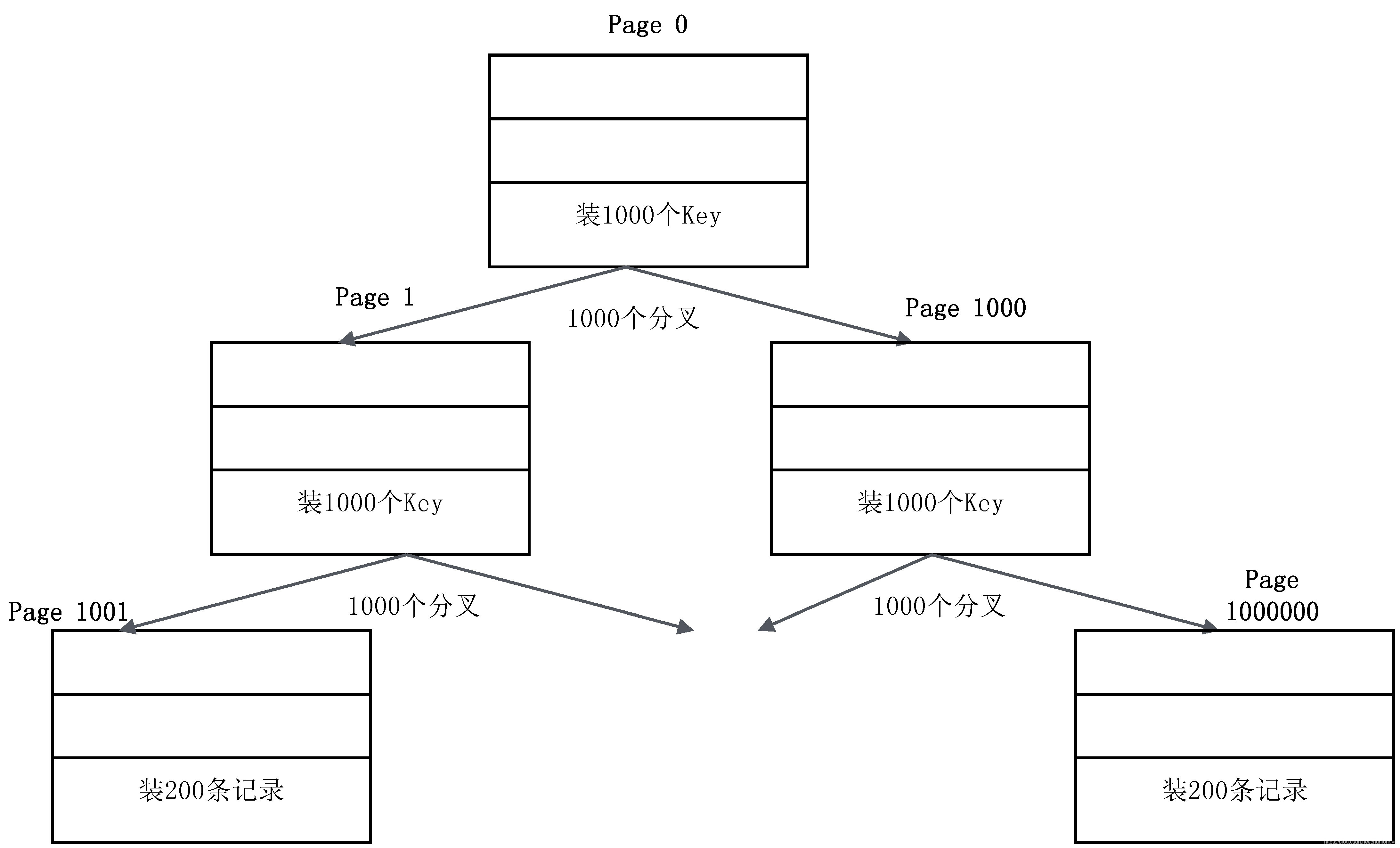
圖6-2 三層的磁碟B+樹示意圖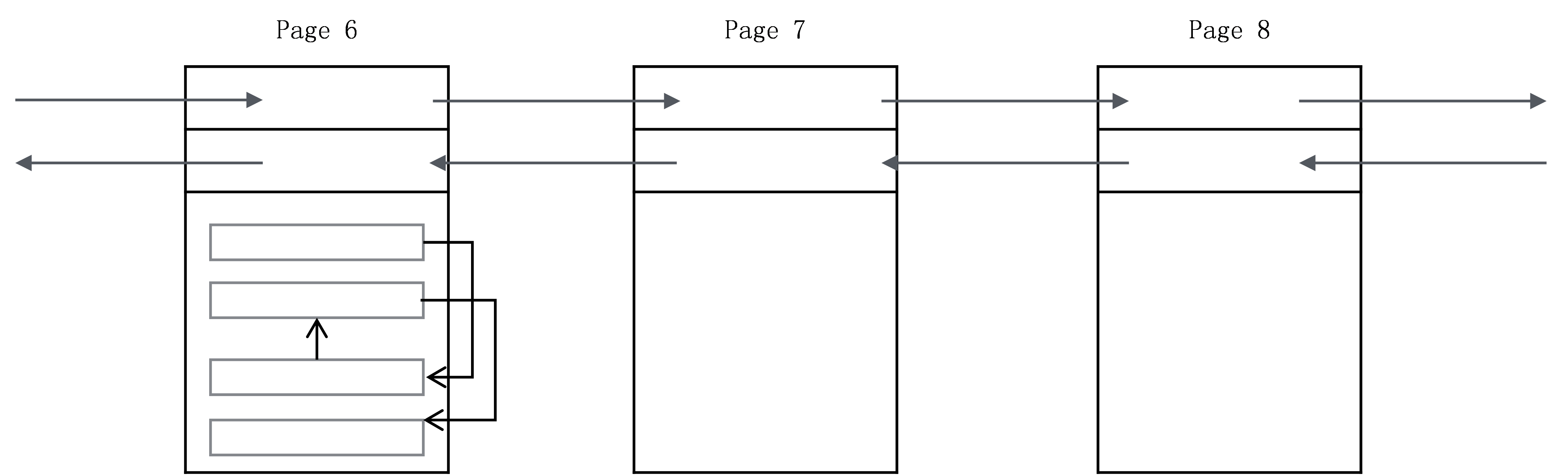
圖6-3 B+樹物理存儲示意圖
在InnoDB的實踐裡面,其中一個建議是按主鍵的自增順序插入記錄,就是為了避免Page Split問題。比如一個Page里依次裝入了Key為(1,3,5,9)四條記錄,並且假設這個Page滿了。接下來如果插入一個Key = 4的記錄,就不得不建一個新的Page,同時把(1,3,5,9)分成兩半,前一半(1,3,4)還在舊的Page中,後一半(5,9)拷貝到新的Page里,並且要調整Page前後的雙向鏈表的指針關係,這顯然會影響插入速度。但如果插入的是Key = 10的記錄,就不需要做Page Split,只需要建一個新的Page,把Key = 10的記錄放進去,然後讓整個鏈表的最後一個Page指向這個新的Page即可。
另外一個點,如果只是插入而不硬刪除記錄(只是軟刪除),也會避免某個Page的記錄數減少進而發生相鄰的Page合併的問題。
6.3.3 非主鍵索引
對於非主鍵索引,同上面類似的結構,每一個非主鍵索引對應一顆B+樹。在InnoDB中,非主鍵索引的葉子節點存儲的不是記錄的指針,而是主鍵的值。所以,對於非主鍵索引的查詢,會查詢兩棵B+樹,先在非主鍵索引的B+樹上定位主鍵,再用主鍵去主鍵索引的B+樹上找到最終記錄。
有一點需要特別說明:對於主鍵索引,一個Key只會對應一條記錄;但對於非主鍵索引,值可以重覆。所以一個Key可能對應多條記錄,如表6-2所示。假設對於欄位1建立索引(欄位1是一個字元類型),一個A會對應1,5,7三條記錄,C對應8、12兩條記錄。這反映在B+樹的數據結構上面就是其葉子節點、非葉子節點的存儲結構,會和主鍵索引的存儲結構稍有不同。
表6-2 非主鍵索引欄位值重覆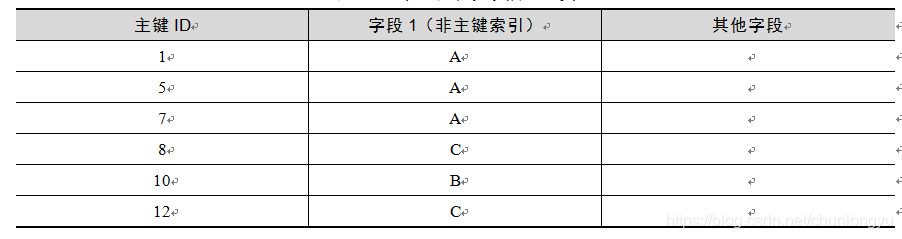
如圖6-4所示,首先,每個葉子節點存儲了主鍵的值;對於非葉子節點,不僅存儲了索引欄位的值,同時也存儲了對應的主鍵的最小值。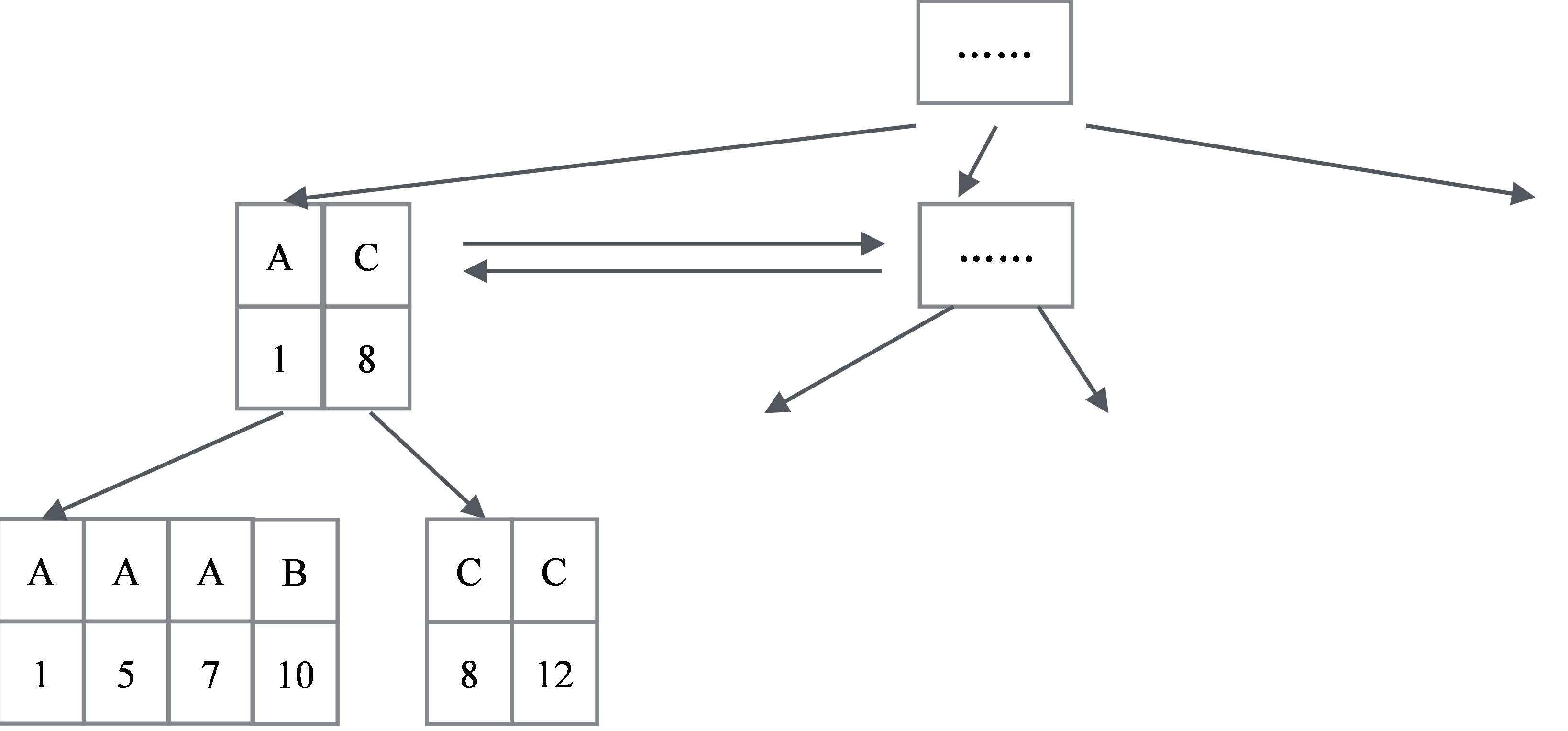
圖6-4 非主鍵索引B+樹示意圖


