
恢復內容開始 運用jieba庫分詞 一、jieba庫基本介紹 1、jieba庫概述 jieba是優秀的中文分詞第三方庫 - 中文文本需要通過分詞獲得單個的詞語 - jieba是優秀的中文分詞第三方庫,需要額外安裝 - jieba庫提供三種分詞模式,最簡單隻需掌握一個函數 2、jieba分詞的原理 J ...
運用jieba庫分詞
一、jieba庫基本介紹
1、jieba庫概述
jieba是優秀的中文分詞第三方庫
- 中文文本需要通過分詞獲得單個的詞語
- jieba是優秀的中文分詞第三方庫,需要額外安裝
- jieba庫提供三種分詞模式,最簡單隻需掌握一個函數
2、jieba分詞的原理
Jieba分詞依靠中文詞庫
- 利用一個中文詞庫,確定漢字之間的關聯概率
- 漢字間概率大的組成片語,形成分詞結果
- 除了分詞,用戶還可以添加自定義的片語
3、jieba庫使用說明
(1)、jieba分詞的三種模式
精確模式、全模式、搜索引擎模式
- 精確模式:把文本精確的切分開,不存在冗餘單詞
- 全模式:把文本中所有可能的詞語都掃描出來,有冗餘
- 搜索引擎模式:在精確模式基礎上,對長詞再次切分
(2)、jieba庫常用函數

二、安裝jieba庫
點擊電腦中的‘開始’,然後在搜索欄中輸入‘cmd’,點擊‘命令指示符’,出現界面後在輸入‘pip install jieba’,剛開始的時候,我的電腦出現了這樣的情況,安裝不了。
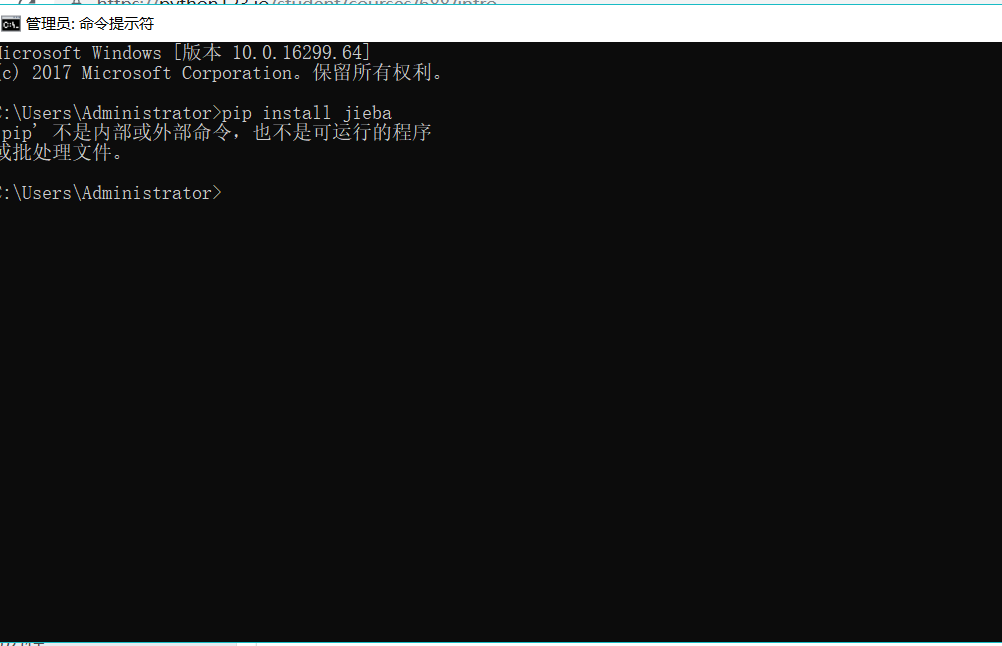
後來在老師的幫助下,就安裝成功了。而且在安裝其他庫的時候也不會再出現第一次的情況。

這樣就安裝成功啦~~~
三、jieba庫的使用用例
1、分詞
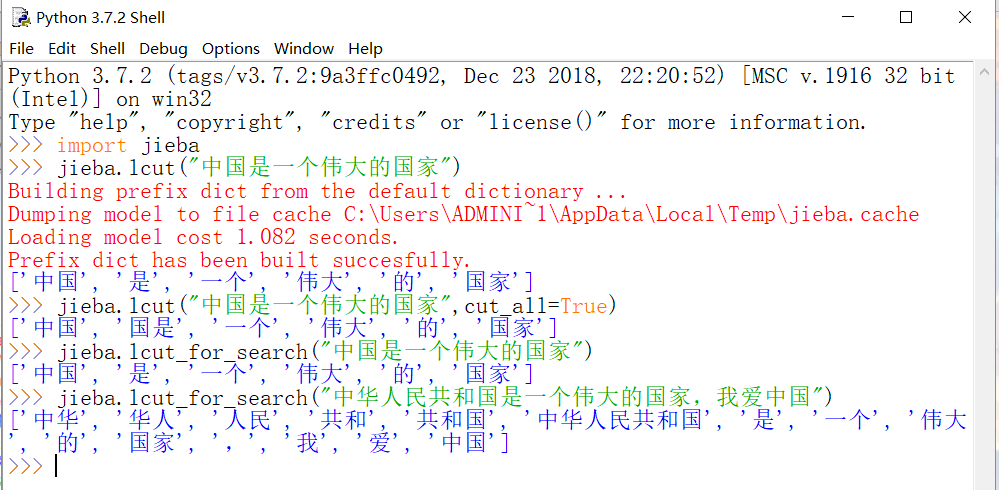
2、詞雲
這是我在網上找的詞雲的一個例子:
1 # 如果您需要使用此代碼,os.chdir路經需要指定到txt文本所在路徑 2 # 使用Zipin函數,需要txt有read()函數可以打開的正確的編碼格式 3 # 使用Cipin函數需要安裝jieba庫 4 # 使用word cloud函數需要安裝wordcloud與matplotlib庫 5 import os 6 import codecs 7 import jieba 8 import pandas as pd 9 from wordcloud import WordCloud 10 from scipy.misc import imread 11 import matplotlib.pyplot as plt 12 os.chdir("/Users/Zhaohaibo/Desktop") 13 14 class Hlm(object): 15 16 # ————————————————————— 17 # Zipin(self, readdoc, writedoc) 18 # readdoc: 要讀取的文件名 19 # writedoc:要寫入的文件名 20 21 # output 22 # 字頻前100,並寫入writedoc 23 # ————————————————————— 24 def Zipin(self, readdoc, writedoc): 25 word_lst = [] 26 word_dict = {} 27 exclude_str = ",。!?、()【】<>《》=:+-*—“”…" 28 with open(readdoc,"r") as fileIn ,open(writedoc,'w') as fileOut: 29 30 # 添加每一個字到列表中 31 for line in fileIn: 32 for char in line: 33 word_lst.append(char) 34 35 # 用字典統計每個字出現的個數 36 for char in word_lst: 37 if char not in exclude_str: 38 if char.strip() not in word_dict: # strip去除各種空白 39 word_dict[char] = 1 40 else : 41 word_dict[char] += 1 42 43 # 排序x[1]是按字頻排序,x[0]則是按字排序 44 lstWords = sorted(word_dict.items(), key=lambda x:x[1], reverse=True) 45 46 # 輸出結果 (前100) 47 print ('字元\t字頻') 48 print ('=============') 49 for e in lstWords[:100]: 50 print ('%s\t%d' % e) 51 fileOut.write('%s, %d\n' % e) 52 53 54 # ————————————————————— 55 # Cipin(self, doc) 56 # doc: 要讀取的文件名 57 58 # return: 59 # 詞頻表(DataFrame格式) 60 # ————————————————————— 61 def Cipin(self, doc): 62 wdict = {} 63 f = open(doc,"r") 64 for line in f.readlines(): 65 words = jieba.cut(line) 66 for w in words: 67 if(w not in wdict): 68 wdict[w] = 1 69 else: 70 wdict[w] += 1 71 # 導入停用詞表 72 stop = pd.read_csv('stoplist.txt', encoding = 'utf-8', sep = 'zhao', header = None,engine = 'python') #sep:分割符號(需要用一個確定不會出現在停用詞表中的單詞) 73 stop.columns = ['word'] 74 stop = [' '] + list(stop.word) #python讀取時不會讀取到空格。但空格依舊需要去除。所以加上空格; 讀取後的stop是series的結構,需要轉成列表 75 for i in range(len(stop)): 76 if(stop[i] in wdict): 77 wdict.pop(stop[i]) 78 79 ind = list(wdict.keys()) 80 val = list(wdict.values()) 81 ind = pd.Series(ind) 82 val = pd.Series(val) 83 data = pd.DataFrame() 84 data['詞'] = ind 85 data['詞頻'] = val 86 return data 87 88 # ————————————————————— 89 # Ciyun(self, doc) 90 # doc: 要讀取的文件名 91 92 # output: 93 # 詞雲圖 94 # ————————————————————— 95 def Ciyun(self,doc): 96 g = open(doc,"r").read() 97 back_pic = imread("aixin.jpg") # 設置背景圖片 98 wc = WordCloud( font_path='/System/Library/Fonts/STHeiti Medium.ttc',#設置字體 99 background_color="white", #背景顏色 100 max_words=2000,# 詞雲顯示的最大詞數 101 mask=back_pic,#設置背景圖片 102 max_font_size=200, #字體最大值 103 random_state=42, 104 ).generate(g) 105 plt.figure(figsize=(64,32)) 106 plt.imshow(wc) 107 plt.axis('off') 108 plt.savefig("ciyun.jpg") 109 plt.show() 110 111 112 def main(self,readdoc): 113 # self.Zipin(readdoc,writedoc) 114 df = self.Cipin(readdoc) 115 #self.Ciyun(readdoc) 116 return df 117 118 119 if __name__ == '__main__': 120 hlm = Hlm() 121 hlm.Zipin("紅樓夢.txt","紅樓夢字頻.txt") 122 df_hlm1 = hlm.main("紅樓夢.txt") 123 --------------------- 124 作者:Iovebecky 125 來源:CSDN 126 原文:https://blog.csdn.net/zhaohaibo_/article/details/81902456 127 版權聲明:本文為博主原創文章,轉載請附上博文鏈接!
代碼顯示如下:

到這裡就結束啦啦啦啦啦~~~~~~~

