
由於在學習過程中對MapReduce有很大的困惑,所以這篇文章主要是針對MR的運行機制進行理解記錄,主要結合網上幾篇博客以及視頻的講解內容進行一個知識的梳理。 MapReduce on Yarn運行原理 Job提交 yarn由兩個重要的jvm進程組成:ResourceManager、NodeMana ...
-
MapReduce on Yarn運行原理
-
Job提交
-
yarn由兩個重要的jvm進程組成:ResourceManager、NodeManager。在客戶端運行MapReduce Job之後,會首先向ResourceManager申請一個唯一的applicationID
-
判斷Job的輸出路徑是否存在,如果存在則報錯退出。這裡之所以這樣設計必須要求要一個新的輸出路徑的原因可以參考博文:https://www.cnblogs.com/sharpxiajun/p/3151395.html
-
根據輸入文件計算input splits
-
將Job需要的依賴資源上傳到HDFS,資源包括程式的jar包、計算好的splits(包括input splits數量、位置)等
-
向ResourceManager提交MapReduce Job
-
-
Job初始化
-
ResourceManager根據提交的資源請求在NodeManager上啟動一個Container(yarn對資源的一個封裝,就是包含一定cpu和記憶體的jvm)運行ApplicationMaster(MRAppMaster)。在這裡需要說明兩點,第一,可以在程式內部添加代碼實現記憶體和cpu的配置(相對於在mapred-site.xml中配置較為靈活),ResourceManager根據資源情況選擇合適的NodeManager啟動一個Container來運行MRAppMaster。第二,之所以要在NodeManager上運行MRAppmaster是為了分散ResourceManager所在主機的運行壓力。
-
MRAppmaste初始化job(多少MapTask、ReduceTask、都在哪些機器上跑)
-
讀取inputsplits信息,為每個inputsplits創建MmapTask,根據程式里的配置確定需要創建多少個ReduceTask,MRAppmaste就是負責管理Task運行的
-
-
Task分配
-
MRAppmaste為每一個MapTask、ReduceTask向ResourceManager申請資源
-
-
Task執行
-
在申請完資源之後在數據所在的節點啟動一個Container,在其中運行一個YarnChild
-
MapTask、ReduceTask都是運行在YarnChild上的,運行過程中會給MRAppmaste發送運行狀態信息
-
以上基本描述了MapReduce on Yarn的一個基本運行過程,可以參考以下的圖示進行理解。


-
-
MapReduce 的運行機制
巨集觀角度來看,整個MapReduce 程式運行的核心是MapTask和ReduceTask,分階段來看主要分為三個階段:map階段、shuffle階段、reduce階段,這其中shuffle是核心。
-
map階段:實際上是運行編寫好的map方法就可以,一般會在相應的splits節點機器上本地運行。
-
shuffle階段:shuffle階段的操作橫跨MapTask和ReduceTask
-
在經過map方法之後數據會以key-value的形式保存在記憶體中,如果在程式中設置了要用多個ReduceTask的話,接下來MapReduce提供Partitioner介面進行分區,也就是決定哪些數據會最終在哪一個ReduceTask上跑。預設情況下是HashPartitioner,也可以自定義。之後,需要將數據寫入記憶體緩衝區中,緩衝區的作用是批量收集map結果。我們的key-value對以及Partition的結果都會被寫入緩衝區。當然寫入之前,key與value值都會被序列化成位元組數組。緩衝區是一個環形數據結構中,使用環形數據結構是為了更有效地使用記憶體空間,在記憶體中放置儘可能多的數據。
-
這個緩衝區的預設大小是100MB,那麼當數據量較大的時候,緩衝區就不夠用了,這個時候就需要向磁碟中寫入,但是這裡不是說完全達到100MB才會觸發向磁碟寫的操作,預設情況下會有一個0.8的閾值繫數,也就是說當占用了80MB的空間之後,就會觸發向磁碟寫的操作,稱為spill。當溢寫線程觸發之後,需要對這80MB空間內的key做排序(Sort),在spill的過程中還可以利用剩餘的20MB空間繼續向緩存區存入數據,這兩個過程之間互不影響。如果client設置過Combiner,那麼現在就是使用Combiner的時候了,將有相同key的key/value對的value加起來,減少溢寫到磁碟的數據量,但是combiner要慎用,使用它的原則是combiner的輸入不會影響到reduce計算的最終輸入,例如:如果計算只是求總數,最大值,最小值可以使用combiner,但是做平均值計算使用combiner的話,最終的reduce計算結果就會出錯。每次spill操作也就是寫入磁碟操作時候就會寫一個溢出文件,也就是說在做map輸出有幾次spill就會產生多少個溢出文件。
-
由於最終的輸出文件只有一個,所以需要將這些溢寫文件歸併到一起,這個過程就叫做Merge。這裡可能也會出現多個相同key的情況,設置過combiner的話這裡也會進行合併。
以上就是MapTask階段的shuffle操作。
-
拉取MapTask的輸出文件,主要通過HTTP的方式請求數據
-
merge和sort,數據拉取過來之後會先放在記憶體緩衝區中,與map端的spill類似也會向磁碟寫如溢出文件,同時進行排序,最後在硬碟中合併為一個最終文件
-
-
reduce階段:生成的最終文件作為reduce的輸入,然後調用編寫的reduce方法最終完成ReduceTask階段。
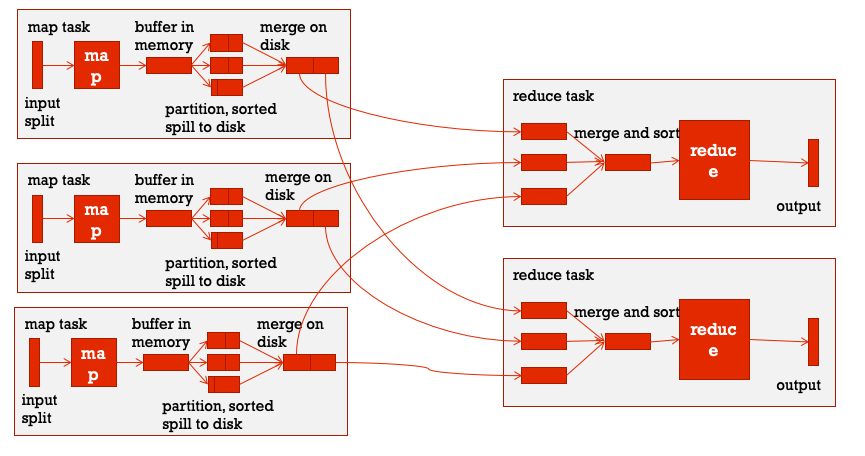

通過上述分析可以發現,在整個環節中shuffle的操作最為複雜真正涉及到記憶體以及磁碟的讀寫,所以shuffle階段是一個主要系統調優的點。
參考:
【1】https://www.cnblogs.com/sharpxiajun/p/3151395.html
【2】https://blog.csdn.net/sunshingheavy/article/details/75849554
【3】https://langyu.iteye.com/blog/992916
-


