
概述 眼下wepack似乎已經成了前端開發中不可缺少的工具之一,而他的一切皆模塊的思想隨著webpack版本不斷的迭代(webpack 4)使其打包速度更快,效率更高的為我們的前端工程化服務 相信大家使用webpack已經很熟練了,他通過一個配置對象,其中包括對入口,出口,插件的配置等,然後內部根據 ...
概述
眼下wepack似乎已經成了前端開發中不可缺少的工具之一,而他的一切皆模塊的思想隨著webpack版本不斷的迭代(webpack 4)使其打包速度更快,效率更高的為我們的前端工程化服務
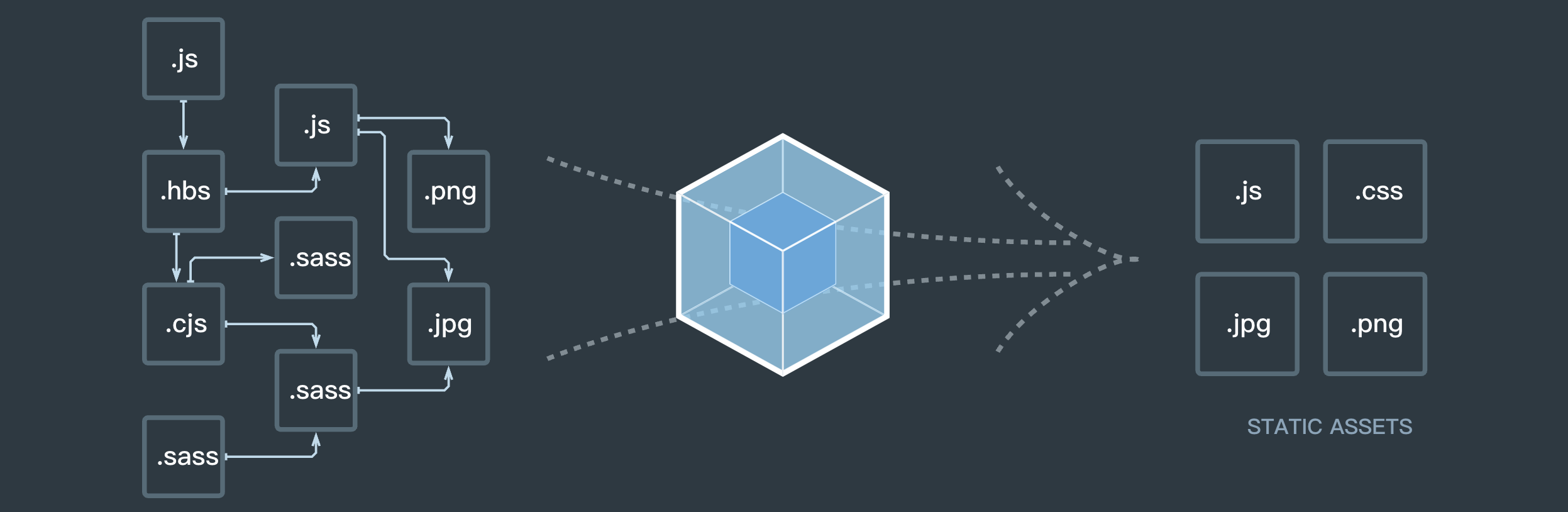
相信大家使用webpack已經很熟練了,他通過一個配置對象,其中包括對入口,出口,插件的配置等,然後內部根據這個配置對象去對整個項目工程進行打包,從一個js文件切入(此為單入口,當然也可以設置多入口文件打包),將該文件中所有的依賴的文件通過特定的loader和插件都會按照我們的需求為我們打包出來,這樣在面對當前的ES6、scss、less、postcss就可以暢快的儘管使用,打包工具會幫助我們讓他們正確的運行在瀏覽器上。可謂是省時省力還省心啊。
那當下的打包工具的核心原理是什麼呢?今天就來通過模擬實現一個小小的打包工具來為探究一下他的核心原理嘍。文中有些知識是點到,沒有深挖,如果有興趣的可以自行查閱資料。
功力尚淺,只是入門級的瞭解打包工具的核心原理,簡單的功能
項目地址
Pack:https://github.com/liuchengying/Pack
原理
當我們更加深入的去瞭解javascript這門語言時,去知道javascript更底層的一些實現,對我們理解好的開源項目是由很多幫助的,當然對我們自身技術提高會有更大的幫助。
javascript是一門弱類型的解釋型語言,也就是說在我們執行前不需要編譯器來編譯出一個版本供我們執行,對於javascript來說也有編譯的過程,只不過大部分情況下編譯發生在代碼執行前的幾微秒,編譯完成後會儘快的執行。也就是根據代碼的執行去動態的編譯。而在編譯過程中通過語法和詞法的分析得出一顆語法樹,我們可以將它稱為AST【抽象語法樹(Abstract Syntax Tree)也稱為AST語法樹,指的是源代碼語法所對應的樹狀結構。也就是說,一種編程語言的源代碼,通過構建語法樹的形式將源代碼中的語句映射到樹中的每一個節點上。】。而這個AST卻恰恰使我們分析打包工具的重點核心。
我們都熟悉babel,他讓前端程式員很爽的地方在於他可以讓我們暢快的去書寫ES6、ES7、ES8.....等等,而他會幫我們統統都轉成瀏覽器能夠執行的ES5版本,它的核心就是通過一個babylon的js詞法解析引擎來分析我們寫的ES6以上的版本語法來得到AST(抽象語法樹),再通過對這個語法樹的深度遍歷來對這棵樹的結構和數據進行修改。最終轉通過整理和修改後的AST生成ES5的語法。這也就是我們使用babel的主要核心。一下是語法樹的示例
需要轉換的文件(index.js)
// es6 index.js
import add from './add.js'
let sum = add(1, 2);
export default sum
// ndoe build.js
const fs = require('fs')
const babylon = require('babylon')
// 讀取文件內容
const content = fs.readFileSync(filePath, 'utf-8')
// 生成 AST 通過babylon
const ast = babylon.parse(content, {
sourceType: 'module'
})
console.log(ast)執行文件(在node環境下build.js)
// node build.js
// 引入fs 和 babylon引擎
const fs = require('fs')
const babylon = require('babylon')
// 讀取文件內容
const content = fs.readFileSync(filePath, 'utf-8')
// 生成 AST 通過babylon
const ast = babylon.parse(content, {
sourceType: 'module'
})
console.log(ast)生成的AST
ast = {
...
...
comments:[],
tokens:[Token {
type: [KeywordTokenType],
value: 'import',
start: 0,
end: 6,
loc: [SourceLocation] },
Token {
type: [TokenType],
value: 'add',
start: 7,
end: 10,
loc: [SourceLocation] },
Token {
type: [TokenType],
value: 'from',
start: 11,
end: 15,
loc: [SourceLocation] },
Token {
type: [TokenType],
value: './add.js',
start: 16,
end: 26,
loc: [SourceLocation] },
Token {
type: [KeywordTokenType],
value: 'let',
start: 27,
end: 30,
loc: [SourceLocation] },
Token {
type: [TokenType],
value: 'sum',
start: 31,
end: 34,
loc: [SourceLocation] },
...
...
Token {
type: [KeywordTokenType],
value: 'export',
start: 48,
end: 54,
loc: [SourceLocation] },
Token {
type: [KeywordTokenType],
value: 'default',
start: 55,
end: 62,
loc: [SourceLocation] },
Token {
type: [TokenType],
value: 'sum',
start: 63,
end: 66,
loc: [SourceLocation] },
]
}上面的示例就是分析出來的AST語法樹。babylon在分析源代碼的時候,會逐個字母的像掃描機一樣讀取,然後分析得出語法樹。(關於語法樹和babylon可以參考 https://www.jianshu.com/p/019d449a9282)。通過遍歷對他的屬性或者值進行修改根據相應的演算法規則重新組成代碼。當分析我們正常的js文件時,往往得到的AST會很大甚至幾萬、幾十萬行,所以需要很優秀的演算法才能保證速度和效率。下麵本項目中用到的是babel-traverse來解析AST。對演算法的感興趣的可以去瞭解一下。以上部分講述的知識點並沒有深入,原因如題目,只是要探索出打包工具的原理,具體知識點感興趣的自己去瞭解下吧。原理部分大概介紹到這裡吧,下麵開始施實戰。
項目目錄
├── README.md
├── package.json
├── src
│ ├── lib
│ │ ├── bundle.js // 生成打包後的文件
│ │ ├── getdep.js // 從AST中獲得文件依賴關係
│ │ └── readcode.js //讀取文件代碼,生成AST,處理AST,並且轉換ES6代碼
│ └── pack.js // 向外暴露工具入口方法
└── yarn.lock思維導圖
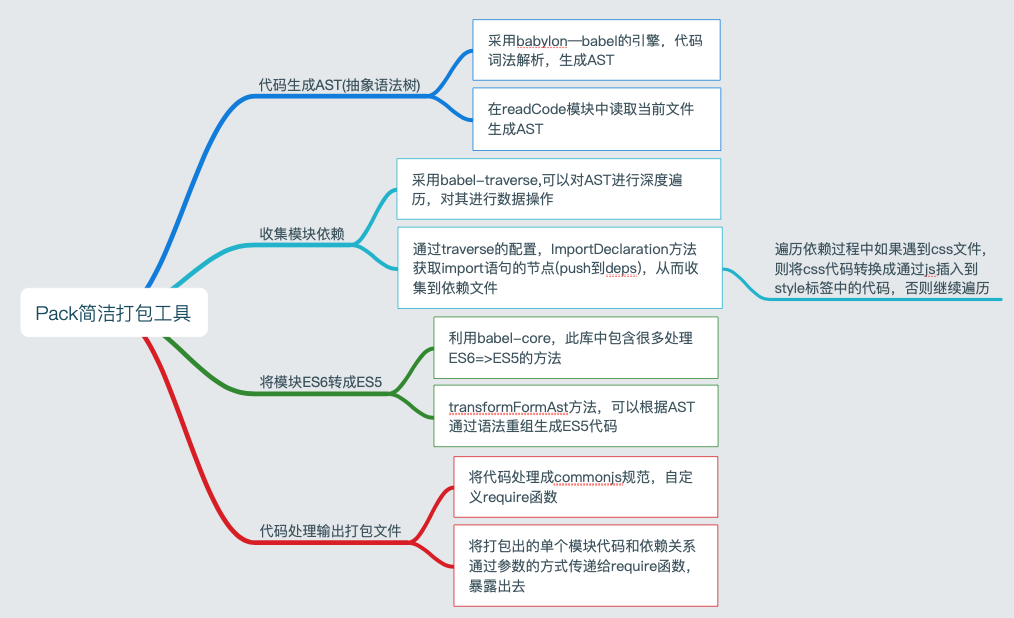
通過思維導圖可以更清楚羅列出來思路
具體實現
流程梳理中發現,重點是找到每個文件中的依賴關係,我們用deps來收集依賴。從而通過依賴關係來模塊化的把依賴關係中一層一層的打包。下麵一步步的來實現
主要通過 代碼 + 解釋 的梳理過程
讀取文件代碼
首先,我們需要一個入口文件的路徑,通過node的fs模塊來讀取指定文件中的代碼,然後通過以上提到的babylon來分析代碼得到AST語法樹,然後通過babel-traverse庫來從AST中獲得代碼中含有import的模塊(路徑)信息,也就是依賴關係。我們把當前模塊的所有依賴文件的相對路徑都push到一個deps的數組中。以便後面去遍歷查找依賴。
const fs = require('fs')
// 分析引擎
const babylon = require('babylon')
// traverse 對語法樹遍歷等操作
const traverse = require('babel-traverse').default
// babel提供的語法轉換
const { transformFromAst } = require('babel-core')
// 讀取文件代碼函數
const readCode = function (filePath) {
if(!filePath) {
throw new Error('No entry file path')
return
}
// 當前模塊的依賴收集
const deps = []
const content = fs.readFileSync(filePath, 'utf-8')
const ast = babylon.parse(content, { sourceType: 'module' })
// 分析AST,從中得到import的模塊信息(路徑)
// 其中ImportDeclaration方法為當遍歷到import時的一個回調
traverse(ast, {
ImportDeclaration: ({ node }) => {
// 將依賴push到deps中
// 如果有多個依賴,所以用數組
deps.push(node.source.value)
}
})
// es6 轉化為 es5
const {code} = transformFromAst(ast, null, {presets: ['env']})
// 返回一個對象
// 有路徑,依賴,轉化後的es5代碼
// 以及一個模塊的id(自定義)
return {
filePath,
deps,
code,
id: deps.length > 0 ? deps.length - 1 : 0
}
}
module.exports = readCode相信上述代碼是可以理解的,代碼中的註釋寫的很詳細,這裡就不在多啰嗦了。需要註意的是,babel-traverse這個庫關於api以及詳細的介紹很少,可以通過其他途徑去瞭解這個庫的用法。
另外需要在強調一下的是最後函數的返回值,是一個對象,該對象中包含的是當前這個文件(模塊)中的一些重要信息,deps中存放的就是當前模塊分析得到的所有依賴文件路徑。最後我們需要去遞歸遍歷每個模塊的所有依賴,以及代碼。後面的依賴收集的時候會用到。
依賴收集
通過上面的讀取文件方法我們得到返回了一個關於單個文件(模塊)的一些重要信息。filePath(文件路徑),deps(該模塊的所有依賴),code(轉化後的代碼),id(該對象模塊的id)
我們通過定義deps為一個數組,來存放所有依賴關係中每一個文件(模塊)的以上重要信息對象
接下來我們通過這個單文件入口的依賴關係去搜集該模塊的依賴模塊的依賴,以及該模塊的依賴模塊的依賴模塊的依賴......我們通過遞歸和迴圈的方式去執行readCode方法,每執行一次將readCode返回的對象push到deps數組中,最終得到了所有的在依賴關係鏈中的每一個模塊的重要信息以及依賴。
const readCode = require('./readcode.js')
const fs = require('fs')
const path = require('path')
const getDeps = function (entry) {
// 通過讀取文件分析返回的主入口文件模塊的重要信息 對象
const entryFileObject = readCode(entry)
// deps 為每一個依賴關係或者每一個模塊的重要信息對象 合成的數組
// deps 就是我們提到的最終的核心數據,通過他來構建整個打包文件
const deps = [entryFileObject ? entryFileObject : null]
// 對deps進行遍歷
// 拿到filePath信息,判斷是css文件還是js文件
for (let obj of deps) {
const dirname = path.dirname(obj.filePath)
obj.deps.forEach(rPath => {
const aPath = path.join(dirname, rPath)
if (/\.css/.test(aPath)) {
// 如果是css文件,則不進行遞歸readCode分析代碼,
// 直接將代碼改寫成通過js操作寫入到style標簽中
const content = fs.readFileSync(aPath, 'utf-8')
const code = `
var style = document.createElement('style')
style.innerText = ${JSON.stringify(content).replace(/\\r\\n/g, '')}
document.head.appendChild(style)
`
deps.push({
filePath: aPath,
reletivePaht: rPath,
deps,
code,
id: deps.length > 0 ? deps.length : 0
})
} else {
// 如果是js文件 則繼續調用readCode分析該代碼
let obj = readCode(aPath)
obj.reletivePaht = rPath
obj.id = deps.length > 0 ? deps.length : 0
deps.push(obj)
}
})
}
// 返回deps
return deps
}
module.exports = getDeps可能在上述代碼中有疑問也許是在對deps遍歷收集全部依賴的時候,又迴圈又重覆調用的可能有一點繞,還有一點可能就是對於deps這個數組最後究竟要乾什麼用,沒關係,繼續往下看,後面就會懂了。
輸出文件
到現在,我們已經可以拿到了所有文件以及對應的依賴以及文件中的轉換後的代碼以及id,是的,就是我們上一節中返回的deps(就靠它了),可能在上一節還會有人產生疑問,接下來,我們就直接上代碼,慢慢道來慢慢解開你的疑惑。
const fs = require('fs')
// 壓縮代碼的庫
const uglify = require('uglify-js')
// 四個參數
// 1. 所有依賴的數組 上一節中返回值
// 2. 主入口文件路徑
// 3. 出口文件路徑
// 4. 是否壓縮輸出文件的代碼
// 以上三個參數,除了第一個deps之外,其他三個都需要在該項目主入口方法中傳入參數,配置對象
const bundle = function (deps, entry, outPath, isCompress) {
let modules = ''
let moduleId
deps.forEach(dep => {
var id = dep.id
// 重點來了
// 此處,通過deps的模塊「id」作為屬性,而其屬性值為一個函數
// 函數體為 當前遍歷到的模塊的「code」,也就是轉換後的代碼
// 產生一個長字元
// 0:function(......){......},
// 1: function(......){......}
// ...
modules = modules + `${id}: function (module, exports, require) {${dep.code}},`
});
// 自執行函數,傳入的剛纔拼接的對象,以及deps
// 其中require使我們自定義的,模擬commonjs中的模塊化
let result = `
(function (modules, mType) {
function require (id) {
var module = { exports: {}}
var module_id = require_moduleId(mType, id)
modules[module_id](module, module.exports, require)
return module.exports
}
require('${entry}')
})({${modules}},${JSON.stringify(deps)});
function require_moduleId (typelist, id) {
var module_id
typelist.forEach(function (item) {
if(id === item.filePath || id === item.reletivePaht){
module_id = item.id
}
})
return module_id
}
`
// 判斷是否壓縮
if(isCompress) {
result = uglify.minify(result,{ mangle: { toplevel: true } }).code
}
// 寫入文件 輸出
fs.writeFileSync(outPath + '/bundle.js', result)
console.log('打包完成【success】(./bundle.js)')
}
module.exports = bundle這裡還是要在詳細的敘述一下。因為我們要輸出文件,顧出現了大量的字元串。
解釋1:modules字元串
modules字元串最後通過遍歷deps得到的字元串為
modules = `
0:function (module, module.exports, require){相應模塊的代碼},
1: function (module, module.exports, require){相應模塊的代碼},
2: function (module, module.exports, require){相應模塊的代碼},
3: function (module, module.exports, require){相應模塊的代碼},
...
...
`如果我們在字元串的兩端分別加上”{“和”}“,如果當成代碼執行的話那不就是一個對象了嗎?對啊,這樣0,1,2,3...就變成了屬性,而屬性的值就是一個函數,這樣就可以通過屬性直接調用函數了。而這個函數的內容就是我們需要打包的每個模塊的代碼經過babel轉換之後的代碼啊。
解釋2:result字元串
// 自執行函數 將上面的modules字元串加上{}後傳入(對象)
(function (modules, mType) {
// 自定義require函數,模擬commonjs中的模塊化
function require (id) {
// 定義module對象,以及他的exports屬性
var module = { exports: {}}
// 轉化路徑和id,已調用相關函數
var module_id = require_moduleId(mType, id)
// 調用傳進來modules對象的屬性的函數
modules[module_id](module, module.exports, require)
return module.exports
}
require('${entry}')
})({${modules}},${JSON.stringify(deps)});
// 路徑和id對應轉換,目的是為了調用相應路徑下對應的id屬性的函數
function require_moduleId (typelist, id) {
var module_id
typelist.forEach(function (item) {
if(id === item.filePath || id === item.reletivePaht){
module_id = item.id
}
})
return module_id
}至於為什麼我們要通過require_modulesId函數來轉換路徑和id的關係呢,這要先從babel吧ES6轉成ES5說起,下麵列出一個ES6轉ES5的例子
ES6代碼:
import a from './a.js'
let b = a + a
export default bES5代碼:
'use strict';
Object.defineProperty(exports, "__esModule", {
value: true
});
var _a = require('./a.js');
var _a2 = _interopRequireDefault(_a);
function _interopRequireDefault(obj) { return obj && obj.__esModule ? obj : { default: obj }; }
var b = _a2.default + _a2.default;
exports.default = b;1.以上代碼為轉化前和轉換後,有興趣的可以去babel官網試試,可以發現轉換後的這一行代碼**var _a = require('./a.js');**,他為我們轉換出來的require的參數是文件的路徑,而我們需要調用的相對應的模塊的函數其屬性值都是以id(0,1,2,3...)命名的,所以需要轉換
2.還有一點可能有疑問的就是為什麼會用function (module, module.exports, require){...}這樣的commonjs模塊化的形式呢,原因是babel為我們轉後後的代碼模塊化採用的就是commonjs的規範。
最後
最後一步就是我們去封裝一下,向外暴露一個入口函數就可以了。這一步效仿一下webpack的api,一個pack方法傳入一個config配置對象。這樣就可以在package.json中寫scripts腳本來npm/yarn來執行了。
const getDeps = require('./lib/getdep')
const bundle = require('./lib/bundle')
const pack = function (config) {
if(!config.entryPath || !config.outPath) {
throw new Error('pack工具:請配置入口和出口路徑')
return
}
let entryPath = config.entryPath
let outPath = config.outPath
let isCompress = config.isCompression || false
let deps = getDeps(entryPath)
bundle(deps, entryPath, outPath, isCompress)
}
module.exports = pack傳入的config只有是三個屬性,entryPath,outPath,isCompression。
總結
一個簡單的實現,只為了探究一下原理,並沒有完善的功能和穩定性。希望對看到的人能有幫助
打包工具,首先通過我們代碼文件進行詞法和語法的分析,生成AST,再通過處理AST,最終變換成我們想要的以及瀏覽器能相容的代碼,收集每一個文件的依賴,最終形成一個依賴鏈,然後通過這個依賴關係最後輸出打包後的文件。
初來乍到,穩重有解釋不當或錯的地方,還請多理解,有問題可以在評論區交流。還有別忘了你的

