
前言 前文介紹過用Python寫爬蟲,但是當任務多的時候就比較慢, 這是由於Python自帶的http庫urllib2發起的http請求是阻塞式的,這意味著如果採用單線程模型,那麼整個進程的大部分時間都阻塞在等待服務端把數據傳輸過來的過程中。所以我們這次嘗試用node.js去做這個爬蟲。 為什麼選擇 ...
前言
前文介紹過用Python寫爬蟲,但是當任務多的時候就比較慢, 這是由於Python自帶的http庫urllib2發起的http請求是阻塞式的,這意味著如果採用單線程模型,那麼整個進程的大部分時間都阻塞在等待服務端把數據傳輸過來的過程中。所以我們這次嘗試用node.js去做這個爬蟲。
為什麼選擇node.js
node.js是一款基於google的V8引擎開發javascript運行環境。在高性能的V8引擎以及事件驅動的單線程非同步非阻塞運行模型的支持下,node.js實現的web服務可以在沒有Nginx的http伺服器做反向代理的情況下實現很高的業務併發量。
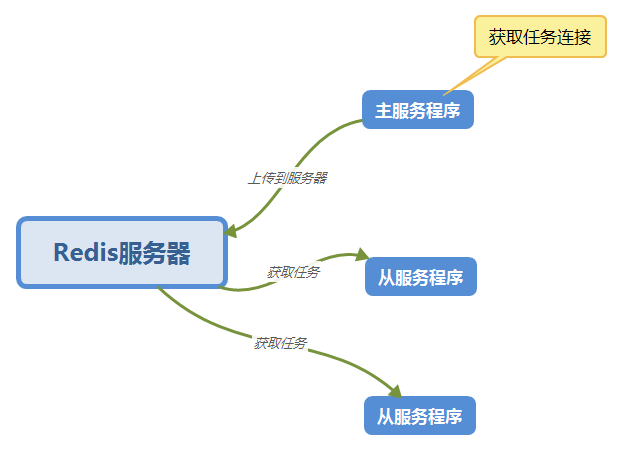
分散式爬蟲設計
這次也用上次的分散式設計,使用Redis伺服器來作為任務隊列。
如圖:
非同步
node.js是基於非同步的寫法,有時一個函數需要上一個函數的返回值做參數,這樣下來一不小心就會陷入回調地獄的陷阱中。
所以這次我們用async模塊控制流程。
準備工作
- 安裝node.js和Redis
- 安裝request、async與Redis相關的庫
代碼
主函數(master.js)
"use strict"
const request = require('request')
const cheerio = require('cheerio')
const fs = require('fs')
const utils = require('./utils')
const log = utils.log
const config = require('./config')
const task_url_head = config.task_url_head
const main_url = config.main_url
const proxy_url = config.proxy_url
const redis_cache = require('./redis_cache')
const redis_client = redis_cache.client
const Task = function() {
this.id = 0
this.title = ''
this.url = ''
this.file_name = ''
this.file_url = 0
this.is_download = false
}
//總下載數
var down_cont = 0
//當前下載數
var cur_cont = 0
const taskFromBody = function(task_url, body) {
const task = new Task()
// cheerio.load 用字元串作為參數返回一個可以查詢的特殊對象
// body 就是 html 內容
const e = cheerio.load(body)
// 查詢對象的查詢語法和 DOM API 中的 querySelector 一樣
const title = e('.controlBar').find('.epi-title').text()
const file_url = e('.audioplayer').find('audio').attr('src')
const ext = file_url.substring(file_url.length-4)
const task_id = task_url.substring(task_url.length-5)
const file_name = task_id+'.'+title+ext
task.id = task_id
task.title = title
task.url = task_url
task.file_name = file_name.replace(/\//g,"-").replace(/:/g,":")
task.file_url = file_url
task.is_download = false
redis_client.set('Task:id:'+task_id,JSON.stringify(task),function (error, res) {
if (error) {
log('Task:id:'+task_id, error)
} else {
log('Task:id:'+task_id, res)
}
cur_cont = cur_cont + 1
if (down_cont == cur_cont) {
// 操作完成,關閉redis連接
redis_client.end(true);
log('已完成')
}
})
}
const taskFromUrl = function(task_url) {
request({
'url':task_url,
'proxy':proxy_url,
},
function(error, response, body) {
// 回調函數的三個參數分別是 錯誤, 響應, 響應數據
// 檢查請求是否成功, statusCode 200 是成功的代碼
if (error === null && response.statusCode == 200) {
taskFromBody(task_url, body)
} else {
log('*** ERROR 請求失敗 ', error)
}
})
}
const parseLink = function(div) {
let e = cheerio.load(div)
let href = e('a').attr('href')
return href
}
const dataFromUrl = function(url) {
// request 從一個 url 下載數據並調用回調函數
request({
'url' : url,
'proxy' : proxy_url,
},
function(error, response, body) {
// 回調函數的三個參數分別是 錯誤, 響應, 響應數據
// 檢查請求是否成功, statusCode 200 是成功的代碼
if (error === null && response.statusCode == 200) {
// cheerio.load 用字元串作為參數返回一個可以查詢的特殊對象
// body 就是 html 內容
const e = cheerio.load(body)
// 查詢對象的查詢語法和 DOM API 中的 querySelector 一樣
const itmeDivs = e('.epiItem.video')
for(let i = 0; i < itmeDivs.length; i++) {
let element = itmeDivs[i]
// 獲取 div 的元素並且用 itmeFromDiv 解析
// 然後加入 link_list 數組中
const div = e(element).html()
// log(div)
const url_body = parseLink(div)
const task_url = task_url_head+url_body
down_cont = itmeDivs.length
taskFromUrl(task_url)
// redis_client.set('Task:id:'+task_id+':url', task_link, )
}
// 操作完成,關閉redis連接
// redis_client.end(true)
log('*** success ***')
} else {
log('*** ERROR 請求失敗 ', error)
}
})
}
const __main = function() {
// 這是主函數
const url = main_url
dataFromUrl(url)
}
__main()從函數(salver.js)
"use strict"
const http = require("http")
const fs = require("fs")
const path = require("path")
const redis = require('redis')
const async = require('async')
const utils = require('./utils')
const log = utils.log
const config = require('./config')
const save_dir_path = config.save_dir_path
const redis_cache = require('./redis_cache')
const redis_client = redis_cache.client
//總下載數
var down_cont = 0
//當前下載數
var cur_cont = 0
const getHttpReqCallback = function(fileUrl, dirName, fileName, downCallback) {
log('getHttpReqCallback fileName ', fileName)
var callback = function (res) {
log("request: " + fileUrl + " return status: " + res.statusCode)
if (res.statusCode != 200) {
startDownloadTask(fileUrl, dirName, fileName, downCallback)
return
}
var contentLength = parseInt(res.headers['content-length'])
var fileBuff = []
res.on('data', function (chunk) {
var buffer = new Buffer(chunk)
fileBuff.push(buffer)
})
res.on('end', function () {
log("end downloading " + fileUrl)
if (isNaN(contentLength)) {
log(fileUrl + " content length error")
return
}
var totalBuff = Buffer.concat(fileBuff)
log("totalBuff.length = " + totalBuff.length + " " + "contentLength = " + contentLength)
if (totalBuff.length < contentLength) {
log(fileUrl + " download error, try again")
startDownloadTask(fileUrl, dirName, fileName, downCallback)
return
}
fs.appendFile(dirName + "/" + fileName, totalBuff, function (err) {
if (err){
throw err;
}else{
log('download success')
downCallback()
}
})
})
}
return callback
}
var startDownloadTask = function (fileUrl, dirName, fileName, downCallback) {
log("start downloading " + fileUrl)
var option = {
host : '127.0.0.1',
port : '8087',
method:'get',//這裡是發送的方法
path : fileUrl,
headers:{
'Accept-Language':'zh-CN,zh;q=0.8',
'Host':'maps.googleapis.com'
}
}
var req = http.request(option, getHttpReqCallback(fileUrl, dirName, fileName, downCallback))
req.on('error', function (e) {
log("request " + fileUrl + " error, try again")
startDownloadTask(fileUrl, dirName, fileName, downCallback)
})
req.end()
}
const beginTask = function(task_key, callback) {
log('beginTask', task_key)
redis_client.get(task_key,function (err,v){
let task = JSON.parse(v)
// log('task', task)
let file_url = task.file_url
let dir_path = save_dir_path
let file_name = task.file_name
if (task.is_download === false) {
startDownloadTask(file_url, dir_path, file_name,function(){
task.is_download = true
redis_client.set(task_key, JSON.stringify(task), function (error, res) {
log('update redis success', task_key)
// cur_cont = cur_cont + 1
// if(cur_cont == down_cont){
// redis_client.end(true)
// }
callback(null,"successful !");
})
})
}else{
callback(null,"successful !");
}
})
}
const mainTask = function() {
redis_client.keys('Task:id:[0-9]*',function (err,v){
// log(v.sort())
let task_keys = v.sort()
down_cont = task_keys.length
log('down_cont', down_cont)
//控制非同步
async.mapLimit(task_keys, 2, function(task_key,callback){
beginTask(task_key, callback)
},function(err,result){
if(err){
log(err);
}else{
// log(result); //會輸出多個“successful”字元串的數組
log("all down!");
redis_client.end(true)
}
});
})
}
const initDownFile = function() {
fs.readdir(save_dir_path, function(err, files){
if (err) {
return console.error(err)
}
let file_list = []
files.forEach( function (file){
file_list.push(file.substring(0, 5))
})
// log(file_list)
redis_client.keys('Task:id:[0-9]*',function (err,v){
let task_keys = v
// log(task_keys)
let unfinish_len = task_keys.filter((item)=>file_list.includes(item.substring(item.length - 5)) == false).length
let cur_unfinish_lent = 0
task_keys.forEach(function (task_key){
let task_id = task_key.substring(task_key.length - 5)
if (file_list.includes(task_id) == false) {
// log(task_key)
redis_client.get(task_key,function (err,v){
let task = JSON.parse(v)
task.is_download = false
// log(task)
// log(task_key)
redis_client.set(task_key, JSON.stringify(task), function (error, res) {
cur_unfinish_lent++
// log('cur_unfinish_lent', cur_unfinish_lent)
if (cur_unfinish_lent == unfinish_len) {
redis_client.end(true)
log('init finish')
}
})
})
}
})
})
})
}
const __main = function() {
// 這是主函數
// initDownFile()
mainTask()
}
__main()完整代碼的地址
https://github.com/zhourunliang/nodejs_crawler


