
1.1 五種I/O模型 1)阻塞I/O2)非阻塞I/O3)I/O復用4)事件(信號)驅動I/O5)非同步I/O1.2 為什麼要發起系統調用?因為進程想要獲取磁碟中的數據,而能和磁碟打交道的只能是內核, 進程通知內核,說要磁碟中的數據此過程就是系統調用1.3 一次I/O完成的步驟當進程發起系統調用時候,...
1.1 五種I/O模型
1)阻塞I/O
2)非阻塞I/O
3)I/O復用
4)事件(信號)驅動I/O
5)非同步I/O
1.2 為什麼要發起系統調用?
因為進程想要獲取磁碟中的數據,而能和磁碟打交道的只能是內核, 進程通知內核,說要磁碟中的數據
此過程就是系統調用
1.3 一次I/O完成的步驟
當進程發起系統調用時候,這個系統調用就進入內核模式, 然後開始I/O操作
I/O操作分為倆個步驟:
1) 磁碟把數據裝載進內核的記憶體空間
2) 內核的記憶體空間的數據copy到用戶的記憶體空間中(此過程才是真正I/O發生的地方)
註意: io調用大多數都是阻塞的
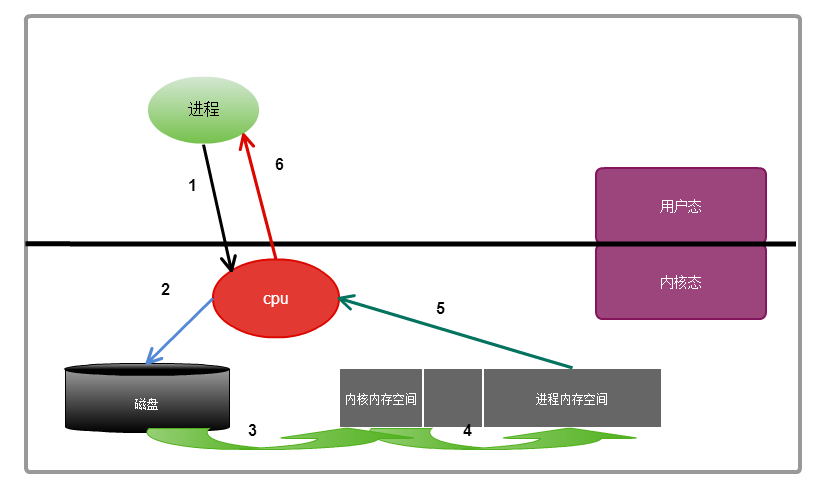
過程分析
整個過程:此進程需要對磁碟中的數據進行操作,則會向內核發起一個系統調用,然後此進程,將會被切換出去,
此進程會被掛起或者進入睡眠狀態,也叫不可中 斷的睡眠,因為數據還沒有得到,只有等到系統調用的結果完成後,
則進程會被喚醒,繼續接下來的操作,從系統調用的開始到系統調用結束經過的步驟:
①進程向內核發起一個系統調用,
②內核接收到系統調用,知道是對文件的請求,於是告訴磁碟,把文件讀取出來
③磁碟接收到來著內核的命令後,把文件載入到內核的記憶體空間裡面
④內核的記憶體空間接收到數據之後,把數據copy到用戶進程的記憶體空間(此過程是I/O發生的地方)
⑤進程記憶體空間得到數據後,給內核發送通知
⑥內核把接收到的通知回覆給進程,此過程為喚醒進程,然後進程得到數據,進行下一步操作
2.1 阻塞
是指調用結果返回之前,當前線程會被掛起(線程進入睡眠狀態) 函數只有在得到結果之後,才會返回,才能繼續執行
阻塞I/O系統怎麼通知進程?
I/O 完成後, 系統直接通知進程, 則進程被喚醒
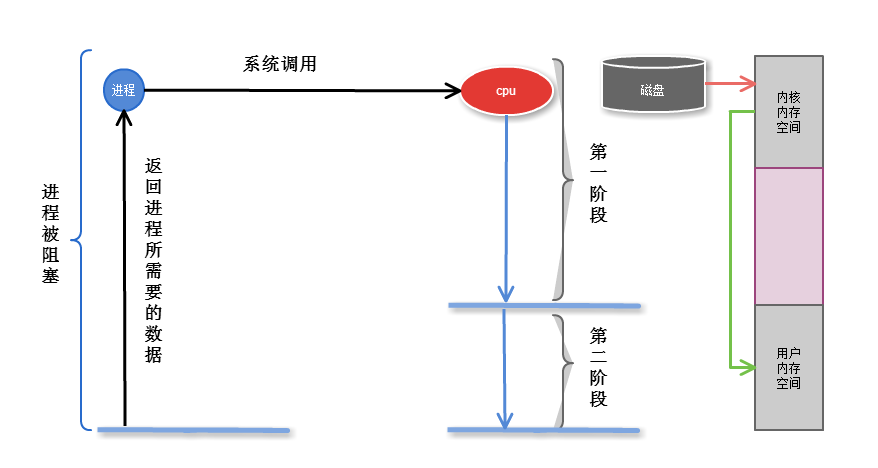
第一階段是指磁碟把數據裝載到內核的記憶體中空間中
第二階段是指內核的記憶體空間的數據copy到用戶的記憶體空間 (這個才是真實I/O操作)
2.2 非阻塞
非阻塞:進程發起I/O調用,I/O自己知道需過一段時間完成,就立即通知進程進行別的操作,則為非阻塞I/O
非阻塞I/O,系統怎麼通知進程?
每隔一段時間,問內核數據是否準備完成,系統完成後,則進程獲取數據,繼續執行(此過程也稱盲等待)
缺點: 無法處理多個I/O,比如用戶打開文件,ctrl+C想終止這個操作,是無法停掉的
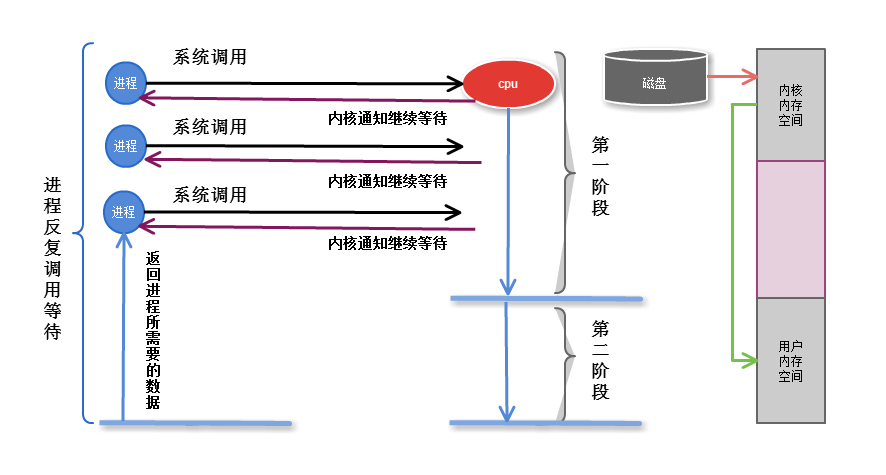
第一階段是指磁碟把數據裝載到內核的記憶體中空間中
第二階段是指內核的記憶體空間的數據copy到用戶的記憶體空間 (這個才是真實I/O操作)
2.3 I/O多路復用 select
為什麼要用I/O多路復用
某個進程阻塞多個io上 ,一個進程即要等待從鍵盤輸入信息, 另一個準備從硬碟裝入信息
比如通過read這樣的命令, 調用了來個io操作,一個io完成了,一個io沒有完成, 阻塞著鍵盤io,磁碟io完成了 ,
這個進程也是不能響應, 因為鍵盤io還沒有完成,還在阻塞著 , 這個進程還在睡眠狀態 ,這個時候怎麼辦 ?
由此需要I/O多路復用。
執行過程
以後進程在調用io的時候, 不是直接調用io的功能,在系統內核中, 新增了一個系統調用, 幫助進程監控多個io,
一旦一個進程需要系統調用的時候, 向內核的一個特殊的系統調用,發起申請時,這個進程會被阻塞在這個復用器的調用上,
所以復用這個功能會監控這些io操作,任何一個io完成了,它都會告訴進程,其中某個io完成,如果進程依賴某個io操作,
那麼這個時候,進程就可以繼續後面的操作. 能夠幫組進程監控這些io的工具叫做io復用器
Linux中 I/O 復用器
select: 就是一種實現,進程需要調用的時候,把請求發送給select ,可以發起多個,但是最多只能支持1024個,先天性的限制
poll: 沒有限制,但是多餘1024個性能會下降
所以早期的apache 本身prefork mpm模型,主進程在接受多個用戶請求的時候,線上請求數超過1024個,就不工作了.
那麼io復用會比前倆種好嗎?
本來進程和系統內核直接溝通的 ,在中間加一個i/o復用select, 如果是傳話,找人傳話,那麼這個傳話最後會是什麼樣的呢?
雖然解決了多個系統調用的問題,多路io復用本身的後半段依然是阻塞的,阻塞在select 上, 而不是阻塞在系統調用上,
但是他第二段仍然是阻塞的,由於要掃描所有多個io操作, 多了一個處理機制,性能未必上升, 性能上也許不會有太大的改觀
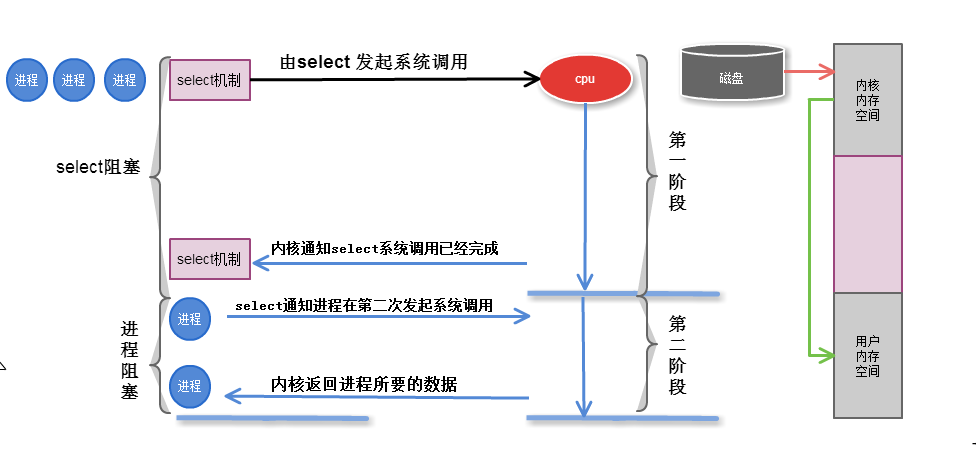
第一階段是指磁碟把數據裝載到內核的記憶體中空間中
第二階段是指內核的記憶體空間的數據copy到用戶的記憶體空間 (這個才是真實I/O操作)
2.4 事件驅動
進程發起調用,通過回調函數, 內核會記住是那個進程申請的,一旦第一段完成了,就可以向這個進程發起通知,
這樣第一段就是非阻塞的,進程不需要盲等了, 但是第二段依然是阻塞的
事件驅動機制(event-driven)
正是由於事件驅動機制 ,才能同時相應多個請求的
比如: 一個web伺服器. 一個進程響應多個用戶請求
缺陷: 第二段仍然是阻塞的
倆種機制
如果一個事件通知一個進程,進程正在忙, 進程沒有聽見, 這個怎麼辦?
水平觸發機制: 內核通知進程來讀取數據,進程沒來讀取數據,內核需要一次一次的通知進程
邊緣觸發機制: 內核只通知一次讓進程來取數據,進程在超時時間內,隨時可以來取數據, 把這個事件信息狀態發給進程,好比發個短息給進程,
nginx
nginx預設採用了邊緣觸發驅動機制
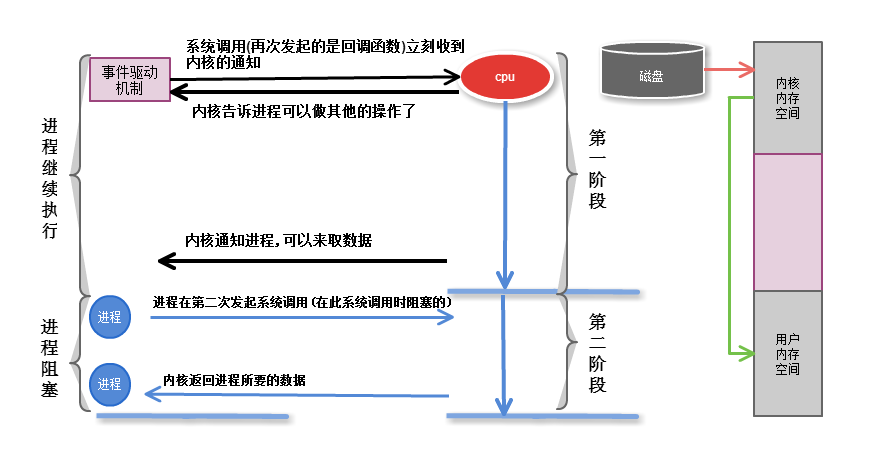
第一階段是指磁碟把數據裝載到內核的記憶體中空間中
第二階段是指內核的記憶體空間的數據copy到用戶的記憶體空間 (這個才是真實I/O操作)
2.5 非同步AIO
無論第一第二段, 不再向系統調用提出任何反饋, 只有數據完全複製到服務進程記憶體中後, 才向服務進程返回ok的信息,其它時間,
進程可以隨意做自己的事情,直到內核通知ok信息
註意: 只在文件中可以實現AIO, 網路非同步IO 不可能實現
nginx:
nginxfile IO 文件非同步請求的
一個進程響應N個請求
靜態文件界別: 支持sendfile
避免浪費複製時間: mmap 支持記憶體映射,內核記憶體複製到進程記憶體這個過程, 不需要複製了, 直接映射到進程記憶體中
支持邊緣觸發
支持非同步io
解決了c10k的問題
c10k : 有一萬個同時的併發連接
c100k: 你懂得
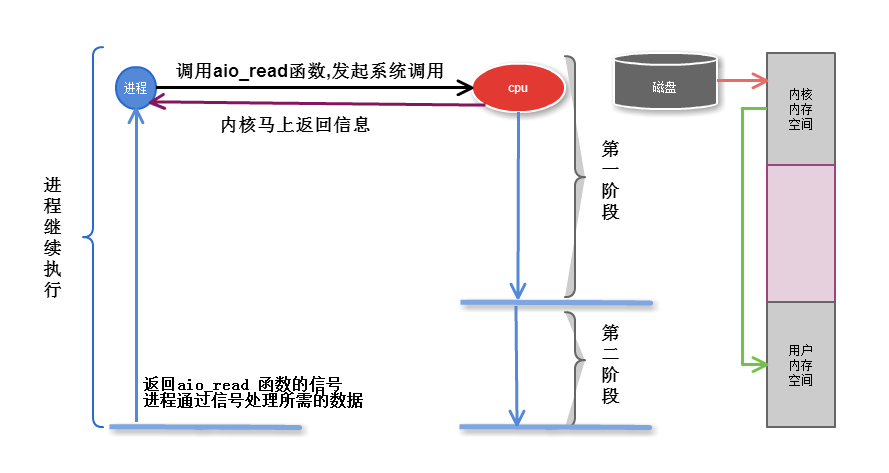
第一階段是指磁碟把數據裝載到內核的記憶體中空間中
第二階段是指內核的記憶體空間的數據copy到用戶的記憶體空間 (這個才是真實I/O操作)
前四種I/O模型屬於同步操作,最後一個AIO則屬於非同步操作
2.6 五種模型比較
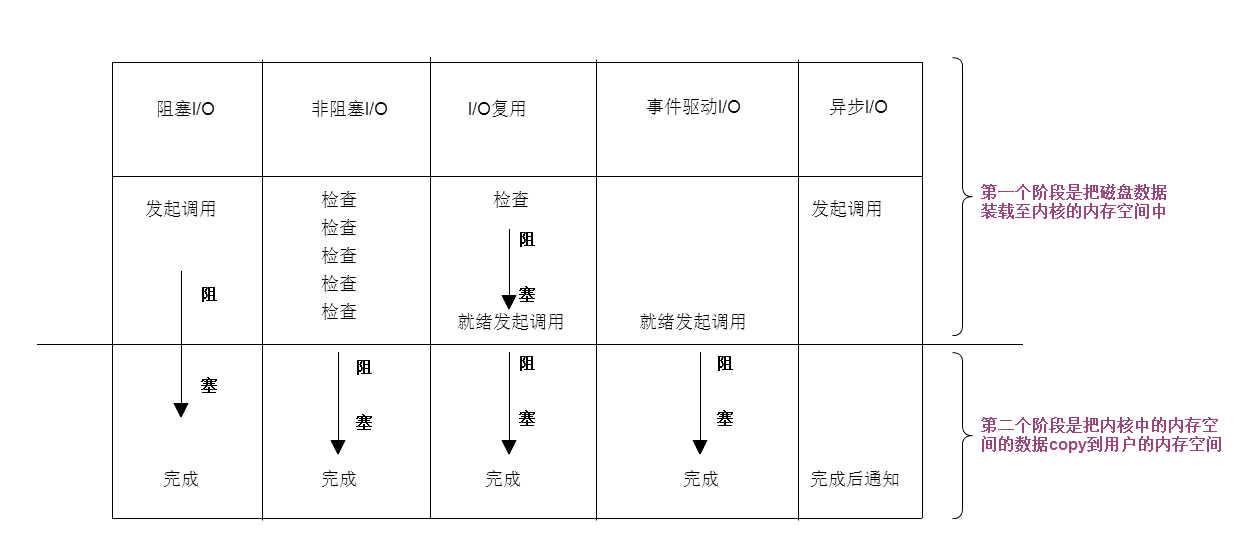

同步阻塞
倆段都是阻塞的,所有數據準備完成後,才響應
同步非阻塞
磁碟從磁碟複製到內核記憶體中的時候, 不停詢問內核數據是否準備完成. 盲等
性能有可能更差 ,看上去他可以做別的事情了, 但是其實他在不停的迴圈.
但還是有一定的靈活性的
缺點: 無法處理多個I/O,比如用戶打開文件,ctrl+C想終止這個操作,是無法停掉的
同步IO
如果第二段是阻塞的 ,代表是同步的
第一種,第二種,io復用,事件驅動,都是同步的.
非同步IO
內核後臺自己處理 ,把大量時間拿來處理用戶請求
來自為知筆記(Wiz)


