
一.自我代碼分析 1.度量: 第一次作業: 第二三次作業(改動很小,給出第三次作業結果): 2.總體自我評價: 第一次作業代碼實現糟糕,可以從代碼統計結果看到這一點,第二三次感覺比較滿意,思路順暢方法簡單可擴展性強但面向對象思想還不夠(甚至沒有繼承和介面),倒算是比較精緻的面向過程,不過類的高內聚低 ...
一.自我代碼分析
1.度量:
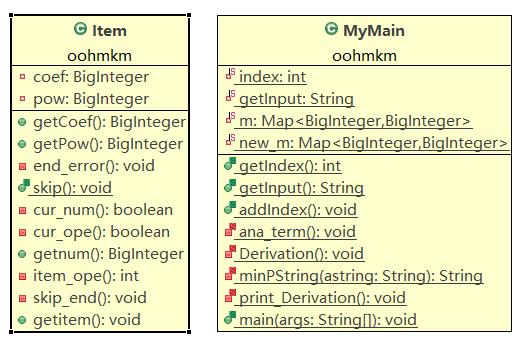
第一次作業:
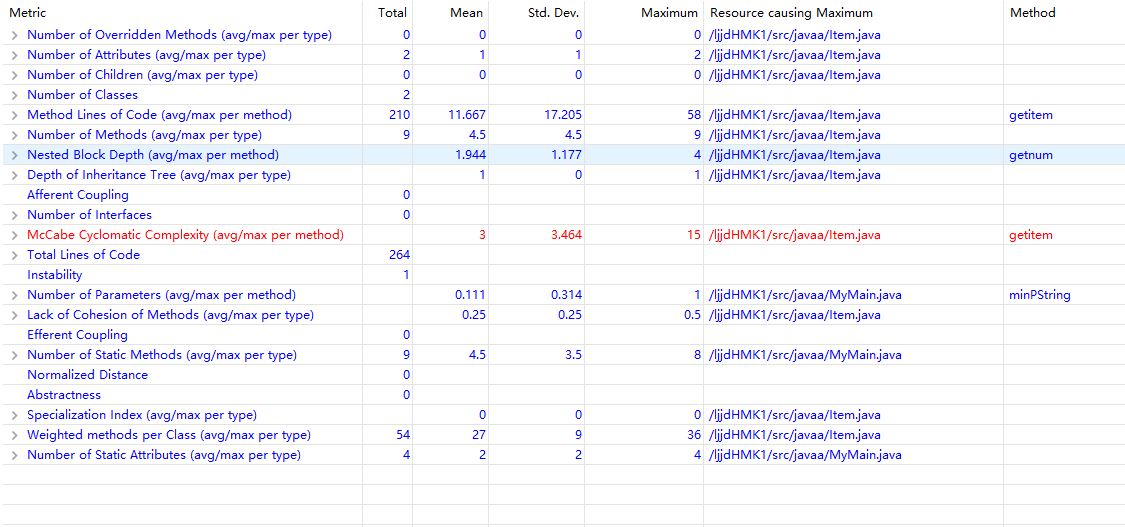
第二三次作業(改動很小,給出第三次作業結果):

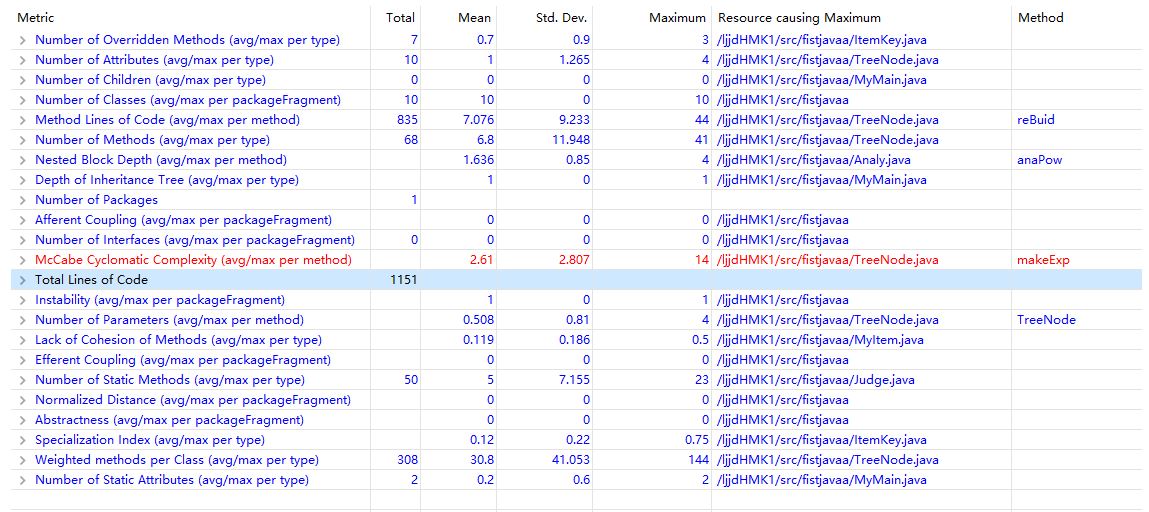
2.總體自我評價:
第一次作業代碼實現糟糕,可以從代碼統計結果看到這一點,第二三次感覺比較滿意,思路順暢方法簡單可擴展性強但面向對象思想還不夠(甚至沒有繼承和介面),倒算是比較精緻的面向過程,不過類的高內聚低耦合倒是實現得不錯
3.詳細分析
總之,我三次小作業的代碼是逐漸迭代優化的,不管是思路上還是結構上。
第一次作業較為簡單,可是我的思路相對於後兩次卻是最複雜的,由於當時沒有確立面向對象思想,整個java項目就是個面向過程的偽c程式——在一個Item類里定義了許多靜態方法,然後在main里調用(沒錯,只有這兩個類),甚至連求導都是在輸出時直接拼湊字元串一項一項輸出,優化也是直接在字元串上操作。
第一次作業較簡單,我實現的也極為糟糕,所以接下來重點談後兩次作業,由於後兩次作業我的思路完全一致,幾乎沒有改動,所以這裡就一起說了。
第二次作業佈置下來後,雖然還沒有要求括弧嵌套(或者說還沒有要求表達式因數的處理)。可是我已經預感到了將來一定是要處理涉及遞歸定義的表達式的(下意識地就想到了編譯課設的表達式)。所以我先寫了一個小小的詞法分析程式來切出運算符、變數等,多虧了上學期的編譯,所以這下寫起來是輕車熟路。詞法分析共定義了以下幾個類:

所有函數的命名和功能都和編譯課設的保持一致(再複習一下),Symenum,枚舉類型,定義了標識符;Judge(裡面全是靜態方法,高內聚),我把所有詞法分析用到的boolean返回類型都放到了這裡;cut,切出帶符號整數、變數的字元串等等(當時未雨綢繆,假設變數不只有x)。需要註意的是我的程式把讀入的表達式作為全局變數(main函數里的public靜態變數),把當前分析到的字元串下標也設置為了public靜態變數,所以可以看到我的這些函數有許多未傳入參數。至於checkindex這個參數本來是想進行預讀的,不過後來也沒用到預讀。
熟悉編譯的同學都知道,詞法分析之後就該語法語義分析了,至於錯誤處理?在這個過程中if else 順手就處理了。可能還是面向過程思想有點重吧,我雖然想到了要定義個表達式類、項類、因數類、運算符類等,可還是沒能實現,而是忍不住順著編譯的思路再寫了個表達式分析:
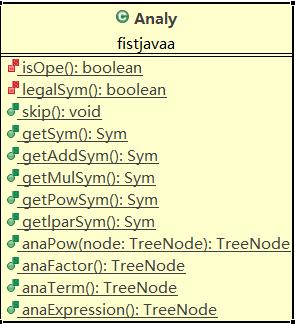
單看返回值就很明瞭了,我用了樹。就是把運算符做中間節點、變數或常量做葉子的樹(一元運算符只有左孩子),這樣設計一來是較為直觀,構造時anafactor等這些函數只需要返回個節點然後讓調用者掛在已有的樹上(這是個遞歸的過程),二來樹結構遞歸求導很方便。上源碼:

這裡只給出了anafactor的代碼,第二次作業不允許表達式因數,就在分析出表達式因數不是x時報錯,第三次作業調用anaexpression函數就是。
這樣,分析完輸入字元串,我就得到了一顆表達式樹,怎麼管理樹呢,自然是再來個類;
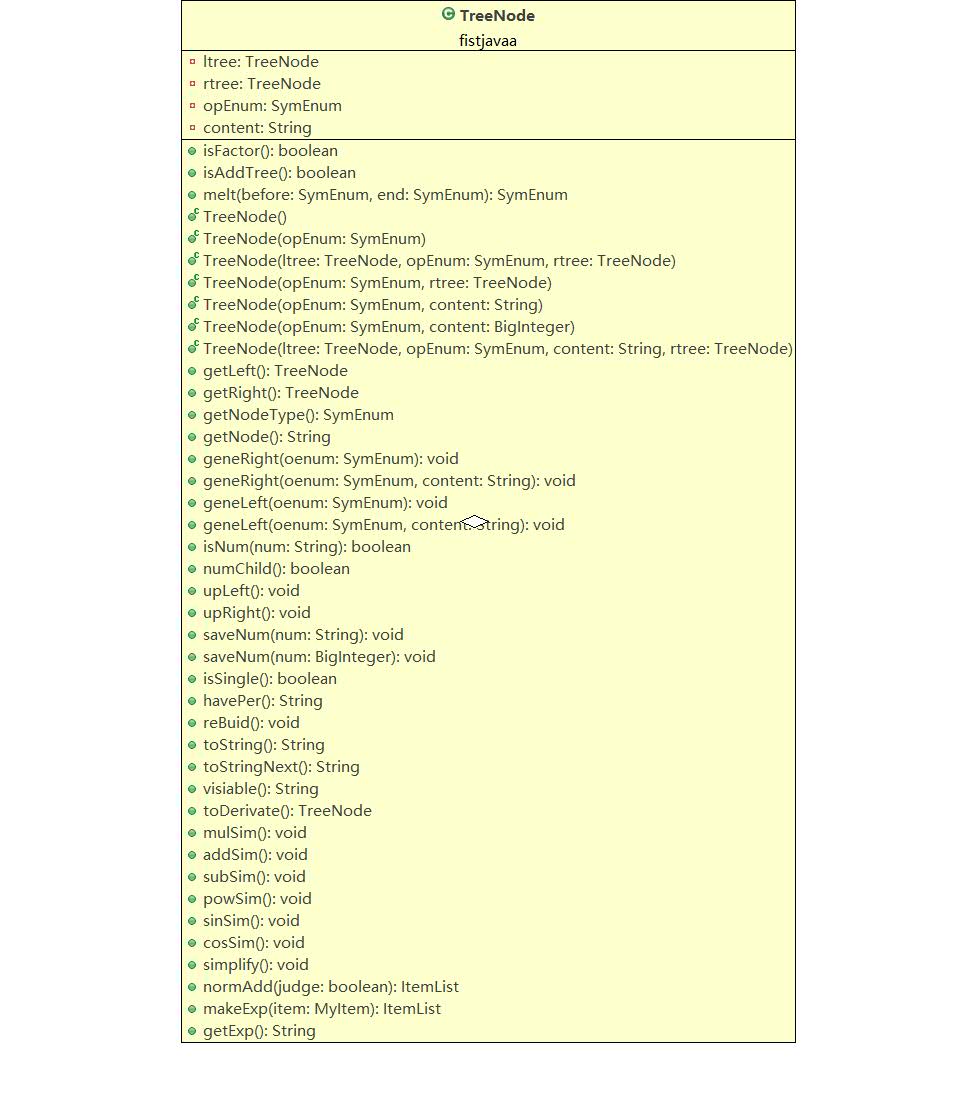
這是個大家伙……直逼上限五百行(489),我程式的核心功能幾乎都在這個樹上(求導、優化、輸出)。先說求導:
在表達式樹上求導是個十分簡單的過程,是個遞歸的過程,我設計的是求導得到一棵新樹,對應不同運算符生成不同的樹就行了:

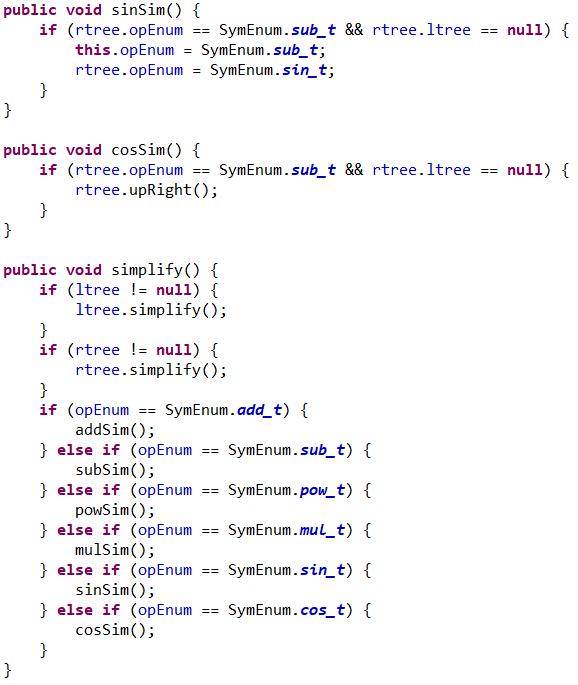
然後是優化,我的優化分為兩部分,一個是剪枝,一個是合併同類項。
剪枝:
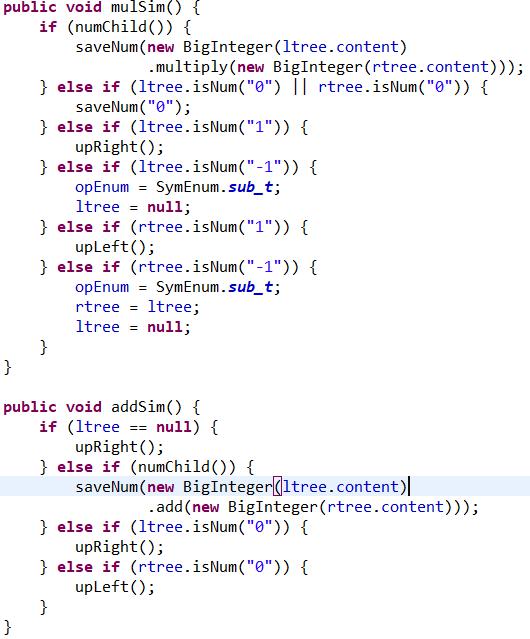

剪枝主要就是剪掉或化簡一些0啊1啊參加運算的的樹枝,這是很有必要的,因為一旦機械地按照求導規則求導,會產生許多乘0啊乘1啊,將他們優化掉會大大提高性能,我第二次作業在這上面吃了大虧,求完導不剪枝,直接重構(一會說重構,這是第二次作業的特殊情況),運算量很大,強測直接有四個點超時,差點掛了。
剛纔提到了重構,這裡解釋一下,重構也就是展開括弧,因為第二次作業括弧里只允許有x,而我的表達式樹直接輸出的話一定要給優先順序低的運算符加括弧的,所以需要在樹上摘摘掛掛變化把低優先順序的運算符提到高優先順序運算符上層,這樣遞歸輸出不必加括弧結果也是正確的。附上代碼,有興趣的同學可以看看(就是小學的乘法分配律):


第二階段的優化就是合併同類項了,我的思路是每個節點有個綜合屬性,有個繼承屬性,繼承屬性從根向下傳遞,遇到加減號停止傳遞,遇到乘號繼續向兩顆子樹下傳遞;綜合屬性從葉子向上傳,遇到加減號繼續向上傳,遇到乘號乘入乘號的繼承屬性並停止下傳。用形象點的語言說,就是每個運算符先得到它左孩子的表達式,再得到它右孩子的表達式(這裡的表達式不是string,是數據結構),然後根據這個運算符的類別進行兩個表達式的合併,將合併後的表達式向上傳(因為是遞歸程式,所以可以自下向上傳遞)。代碼:


二.bug分析
我此次測試出的bug分為兩種:其一為對規則理解不透徹準確的bug,其二為自己手抖的“筆誤型”bug。
第一類bug印象較深的有兩處,一次是第二次作業的弱測有一個輸入是“什麼都不輸入”,註意這還不是輸入空串,我是用try catch解決的。第二次就是對輸出的字元串格式要求和輸入一致,我一開始沒仔細理解這句話,導致輸出的格式不對,所以後來我會把每次的輸出字元串再扔進程式跑一遍,二次迭代(二階導)也正確就說明程式出bug的可能性更小。
第二類bug就是我把一處“cos”寫成了“sin”,為此還跟蹤了挺長時間,以後要更仔細些。
值得慶幸的是並沒有因為程式錯誤或混亂而出現的bug,我覺得這種bug可能更難解決吧,所以編程前一定要有清晰的構思,確保自己的方案是正確的。
總體來說,bug在輸入輸出處理及邏輯較複雜、代碼較長的方法里出現的頻率更高些,我的解決方法一般是寫完一個小功能(如詞法分析)就測試一下,防止bug積累,日後面對長長的幾千行代碼,bug就更難找。
另外關於測試的一點體會,其實測試樣例也不一定要越複雜越好,尤其是涉及到遞歸程式時,其實只要一層對了、兩層對了,bug出現的概率也不大了,更深層的測試也不能說明更多,反而一味追求輸入複雜度可能漏掉其他的一些分支,因此要理智地分析不同類型、不同分支的輸入,爭取實現全覆蓋(至於代碼覆蓋,eclipse有自帶的插件,還是很方便的)。
三.嘗試重構
仍然採用樹結構,但是樹節點及頁節點定義一個父類,對不同的運算符、數字、變數定義不同的子類,重載求導、優化等方法,減少自己的判斷語句及分支。

