
什麼是rowkey Hbase是一個分散式的、面向列的資料庫,它和一般關係型資料庫的最大區別是:HBase很適合於存儲非結構化的數據,還有就是它基於列的而不是基於行的模式. Hbase是採用K,V存儲的,那Rowkey就是KeyValue的Key了,Rowkey也是一段二進位碼流,最大長度為64KB ...
什麼是rowkey
Hbase是一個分散式的、面向列的資料庫,它和一般關係型資料庫的最大區別是:HBase很適合於存儲非結構化的數據,還有就是它基於列的而不是基於行的模式.
Hbase是採用K,V存儲的,那Rowkey就是KeyValue的Key了,Rowkey也是一段二進位碼流,最大長度為64KB,內容可以由使用的用戶自定義。數據載入時,一般也是根據Rowkey的二進位序由小到大進行的。
HBase是根據Rowkey來進行檢索的,系統通過找到某個Rowkey (或者某個 Rowkey 範圍)所在的Region,然後將查詢數據的請求路由到該Region獲取數據。HBase的檢索支持3種方式:
1 通過單個Rowkey訪問,即按照某個Rowkey鍵值進行get操作,這樣獲取唯一一條記錄;
2 通過Rowkey的range進行scan,即通過設置startRowKey和endRowKey,在這個範圍內進行掃描。這樣可以按指定的條件獲取一批記錄;
3全表掃描,即直接掃描整張表中所有行記錄。
HBASE按單個Rowkey檢索的效率是很高的,耗時在1毫秒以下,每秒鐘可獲取1000~2000條記錄,不過非key列的查詢很慢。
我們常說看一張 HBase 表設計的好不好,就看它的 RowKey 設計的好不好。可見 RowKey 在 HBase 中的地位。那麼 RowKey 到底是什麼?RowKey 的特點如下:
類似於 MySQL、Oracle中的主鍵,用於標示唯一的行;
完全是由用戶指定的一串不重覆的字元串;
HBase 中的數據永遠是根據 Rowkey 的字典排序來排序的。
RowKey的作用
1讀寫數據時通過 RowKey 找到對應的 Region;
2 MemStore 中的數據按 RowKey 字典順序排序;
3 HFile 中的數據按 RowKey 字典順序排序。
Rowkey對查詢的影響
如果我們的 RowKey 設計為 uid+phone+name,那麼這種設計可以很好的支持以下的場景:
uid = 111 AND phone = 123 AND name = zs
uid = 111 AND phone = 123
uid = 111 AND phone = 12?
uid = 111
難以支持的場景:
phone = 123 AND name = zs
phone = 123
name = zs
Rowkey對Region劃分影響
HBase 表的數據是按照 Rowkey 來分散到不同 Region,不合理的 Rowkey 設計會導致熱點問題。熱點問題是大量的 Client 直接訪問集群的一個或極少數個節點,而集群中的其他節點卻處於相對空閑狀態。
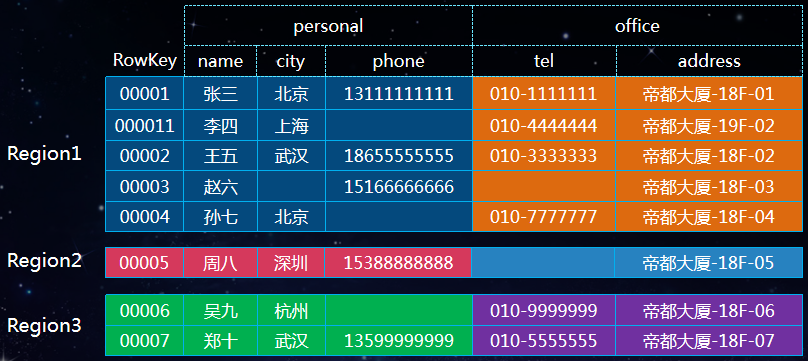
如上圖,Region1 上的數據是 Region 2 的5倍,這樣會導致 Region1 的訪問頻率比較高,進而影響這個 Region 所在機器的其他 Region。
RowKey設計技巧
我們如何避免上面說到的熱點問題呢?這就是這章節談到的三種方法。
一.避免熱點的方法 - Salting
這裡的加鹽不是密碼學中的加鹽,而是在rowkey 的前面增加隨機數。具體就是給 rowkey 分配一個隨機首碼 以使得它和之前排序不同。分配的首碼種類數量應該和你想使數據分散到不同的 region 的數量一致。 如果你有一些 熱點 rowkey 反覆出現在其他分佈均勻的 rwokey 中,加鹽是很有用的。考慮下麵的例子:它將寫請求分散到多個 RegionServers,但是對讀造成了一些負面影響。
假如你有下列 rowkey,你表中每一個 region 對應字母表中每一個字母。 以 'a' 開頭是同一個region, 'b'開頭的是同一個region。在表中,所有以 'f'開頭的都在同一個 region, 它們的 rowkey 像下麵這樣:
|
foo0001 foo0002 foo0003 foo0004 |
現在,假如你需要將上面這個 region 分散到 4個 region。你可以用4個不同的鹽:'a', 'b', 'c', 'd'.在這個方案下,每一個字母首碼都會在不同的 region 中。加鹽之後,你有了下麵的 rowkey:
|
a-foo0003 b-foo0001 c-foo0004 d-foo0002 |
所以,你可以向4個不同的 region 寫。理論上說,如果這四個 Region 存放在不同的機器上,經過加鹽之後你將擁有之前4倍的吞吐量。
現在,如果再增加一行,它將隨機分配a,b,c,d中的一個作為首碼,並以一個現有行作為尾部結束:
|
a-foo0003 b-foo0001 c-foo0003 c-foo0004 d-foo0002 |
因為分配是隨機的,所以如果你想要以字典序取回數據,你需要做更多工作。加鹽這種方式增加了寫時的吞吐量,但是當讀時有了額外代價。
二.避免熱點的方法 - Hashing
Hashing 的原理是計算 RowKey 的 hash 值,然後取 hash 的部分字元串和原來的 RowKey 進行拼接。這裡說的 hash 包含 MD5、sha1、sha256或sha512等演算法。比如我們有如下的 RowKey:
|
foo0001 foo0002 foo0003 foo0004 |
我們使用 md5 計算這些 RowKey 的 hash 值,然後取前 6 位和原來的 RowKey 拼接得到新的 RowKey:
|
95f18cfoo0001 6ccc20foo0002 b61d00foo0003 1a7475foo0004 |
優缺點:可以一定程度打散整個數據集,但是不利於 Scan;比如我們使用 md5 演算法,來計算Rowkey的md5值,然後截取前幾位的字元串。subString(MD5(設備ID), 0, x) + 設備ID,其中x一般取5或6。
三.避免熱點的方法 - Reversing
Reversing 的原理是反轉一段固定長度或者全部的鍵。比如我們有以下 URL ,並作為 RowKey:
|
flink.xiguage.com www.xiguage.com carbondata.xiguage.com def.xiguage.com |
這些 URL 其實屬於同一個功能變數名稱,但是由於前面不一樣,導致數據不在一起存放。我們可以對其進行反轉,如下:
|
moc.egaugix.knilf moc.egaugix.www moc.egaugix.atadnobrac moc.egaugix.fed |
經過這個之後,這些 URL 的數據就可以放一起了。
RowKey的長度
RowKey 可以是任意的字元串,最大長度64KB(因為 Rowlength 占2位元組)。建議越短越好,原因如下:
數據的持久化文件HFile中是按照KeyValue存儲的,如果rowkey過長,比如超過100位元組,1000w行數據,光rowkey就要占用100*1000w=10億個位元組,將近1G數據,這樣會極大影響HFile的存儲效率;
MemStore將緩存部分數據到記憶體,如果rowkey欄位過長,記憶體的有效利用率就會降低,系統不能緩存更多的數據,這樣會降低檢索效率;
目前操作系統都是64位系統,記憶體8位元組對齊,控制在16個位元組,8位元組的整數倍利用了操作系統的最佳特性。
RowKey 設計案例剖析
交易類表 Rowkey 設計
1.查詢某個賣家某段時間內的交易記錄
sellerId + timestamp + orderId
2.查詢某個買家某段時間內的交易記錄
buyerId + timestamp +orderId
3.根據訂單號查詢
orderNo
4.如果某個商家賣了很多商品,可以如下設計 Rowkey 實現快速搜索
salt + sellerId + timestamp 其中,salt 是隨機數。
可以支持的場景:
全表 Scan
按照 sellerId 查詢
按照 sellerId + timestamp 查詢
金融風控 Rowkey 設計
查詢某個用戶的用戶畫像數據
prefix + uid
prefix + idcard
prefix + tele
其中 prefix = substr(md5(uid),0 ,x), x 取 5-6。uid、idcard以及 tele 分別表示用戶唯一標識符、身份證、手機號碼。
車聯網 Rowkey 設計
查詢某輛車在某個時間範圍的交易記錄
carId + timestamp
某批次的車太多,造成熱點
prefix + carId + timestamp 其中 prefix = substr(md5(uid),0 ,x)
查詢最近的數據
查詢用戶最新的操作記錄或者查詢用戶某段時間的操作記錄,RowKey 設計如下:
uid + Long.Max_Value - timestamp
支持的場景
查詢用戶最新的操作記錄
Scan [uid] startRow [uid][000000000000] stopRow [uid][Long.Max_Value - timestamp]
查詢用戶某段時間的操作記錄
Scan [uid] startRow [uid][Long.Max_Value – startTime] stopRow [uid][Long.Max_Value - endTime]
如果 RowKey 無法滿足我們的需求,可以嘗試二級索引。Phoenix、Solr 以及 ElasticSearch 都可以用於構建二級索引。

