
一、基於度量對程式結構的分析 1. 第一次作業 1.1 基於類的分析的度量 首先,基於類的屬性個數,方法個數,每個方法的規模,每個方法的控制分支數目,類總代碼規模等特征對本次作業的結構進行分析。 1.2 基於類間內聚和耦合的度量 我使用了MetricsReloaded插件來對代碼的複雜度進行了分析。 ...
一、基於度量對程式結構的分析
1. 第一次作業
1.1 基於類的分析的度量
首先,基於類的屬性個數,方法個數,每個方法的規模,每個方法的控制分支數目,類總代碼規模等特征對本次作業的結構進行分析。

1.2 基於類間內聚和耦合的度量
我使用了MetricsReloaded插件來對代碼的複雜度進行了分析。
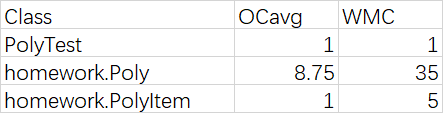
還有對於方法的複雜度分析由於篇幅原因沒有貼出來,主要的指標為ev,iv,v三個指標,分別代表基本複雜度、模塊設計複雜度以及模塊判定結構複雜度,ev大代表代碼非結構化程度高,難以模塊化和維護。iv大代表模塊間耦合度高,模塊間難以隔離與復用,v大表示代碼獨立路徑條數多,難於測試和維護。在做面向對象度量時,我們經常採用ck度量(Chidamber Kemerer)來度量耦合,內聚,封裝等等特征。上表中wmc代表的是類的方法權重,表示一個類中所有方法的複雜度之和。顯然越大說明越複雜。
1.3 UML圖及結構點評
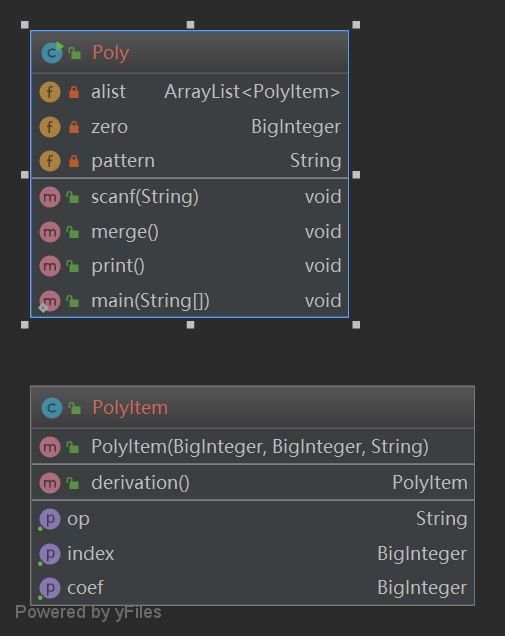 由於是第一次作業,因此對於面向對象的思想還不是特別熟悉,我這次將main類與Poly類寫到了一起,其實應該分離,一個多項式的類,一個項的類,一個main入口類。整體來講結構不是很好,而且有兩個比較長的方法同時分支較多,同時也就造成了它們的獨立路徑數較多,模塊複雜度較高。
由於是第一次作業,因此對於面向對象的思想還不是特別熟悉,我這次將main類與Poly類寫到了一起,其實應該分離,一個多項式的類,一個項的類,一個main入口類。整體來講結構不是很好,而且有兩個比較長的方法同時分支較多,同時也就造成了它們的獨立路徑數較多,模塊複雜度較高。
2. 第二次作業
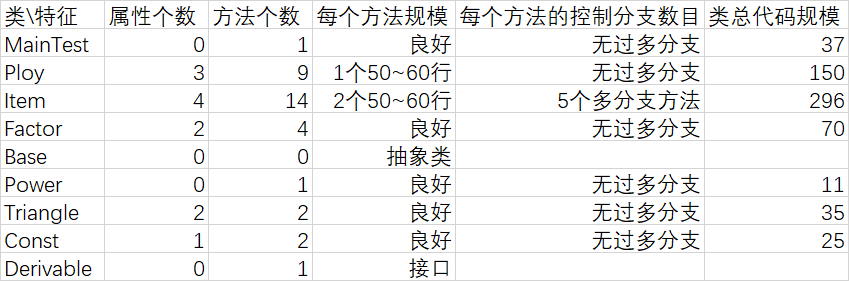
2.1 基於類的分析的度量
2.2 基於類間內聚和耦合的度量

我的高複雜度方法體現在輸入處理,輸出處理以及化簡上,這次作業如何有效的化簡是一個難點。
2.3 UML圖及結構點評
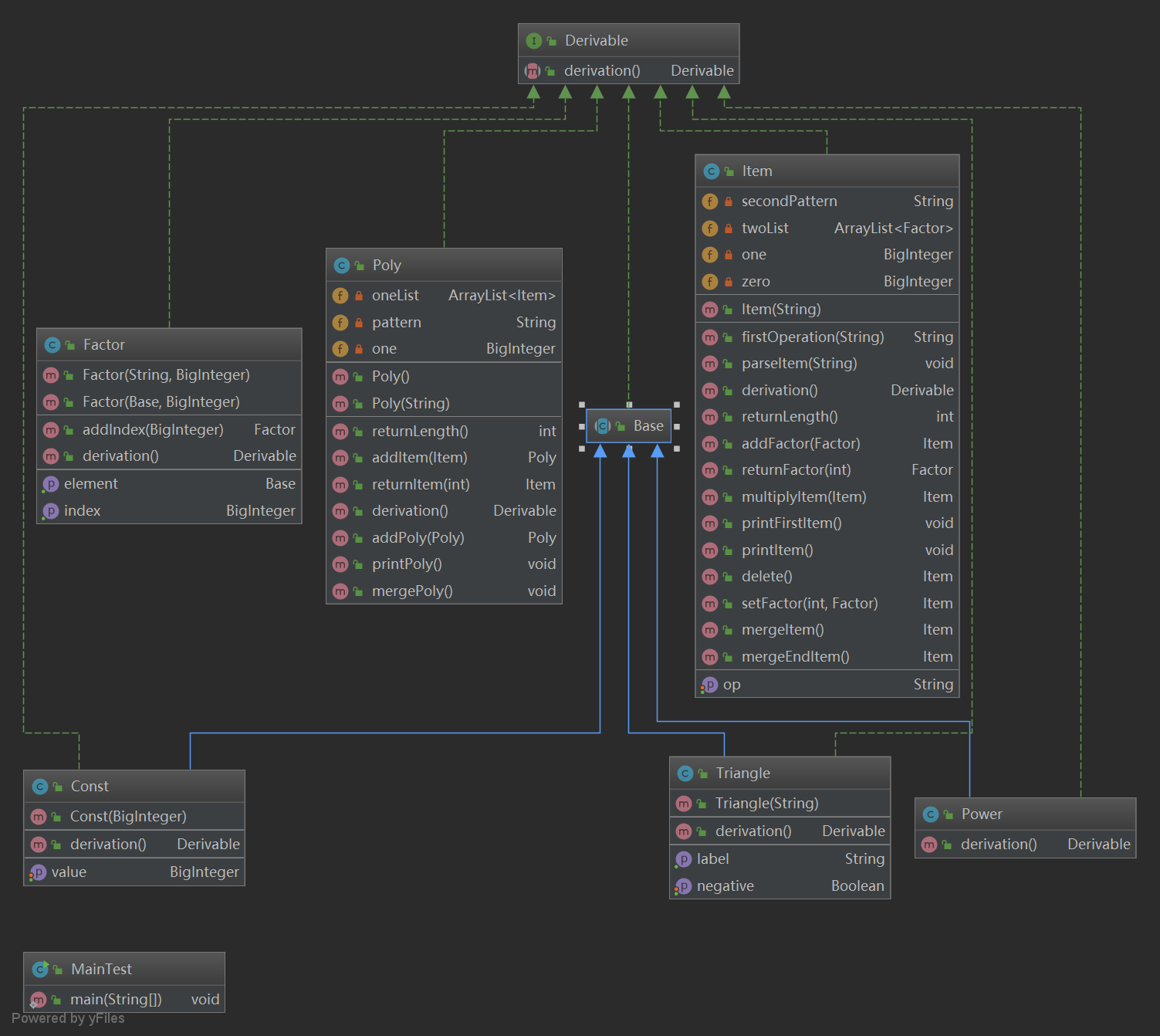 本次作業的設計較為體現了面向對象的思想,設計了一個main入口類,多項式類,項類,因數類,以及其中由於因數是由底數和指數組成的,而指數又有多種形式,故設計了一個底數的抽象類base,將常數類const,冪函數類power,三角函數類triangle作為了base的子類,這樣就可以將一個多項式一點點解析成項,因數,底數,指數等等。同時,由於每一個類都有共同的特點就是可求導,因此我設計了一個求導的介面Derivable,所有的類都實現了這個介面,這符合了java面向介面編程的思想,同時也提升了代碼的規範性。
本次作業的設計較為體現了面向對象的思想,設計了一個main入口類,多項式類,項類,因數類,以及其中由於因數是由底數和指數組成的,而指數又有多種形式,故設計了一個底數的抽象類base,將常數類const,冪函數類power,三角函數類triangle作為了base的子類,這樣就可以將一個多項式一點點解析成項,因數,底數,指數等等。同時,由於每一個類都有共同的特點就是可求導,因此我設計了一個求導的介面Derivable,所有的類都實現了這個介面,這符合了java面向介面編程的思想,同時也提升了代碼的規範性。
3. 第三次作業
3.1 基於類的分析的度量
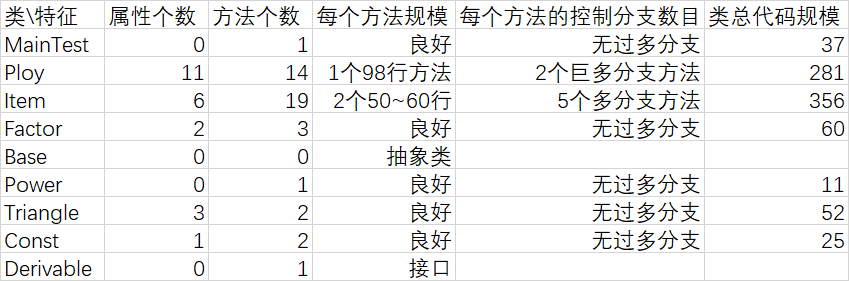
3.2 基於類間內聚和耦合的度量

發現我的高複雜度的方法全部都是對於輸入處理上,由此可見我的輸入處理的不太好,寫的十分面向過程且十分容易出錯。
3.3 UML圖及結構點評
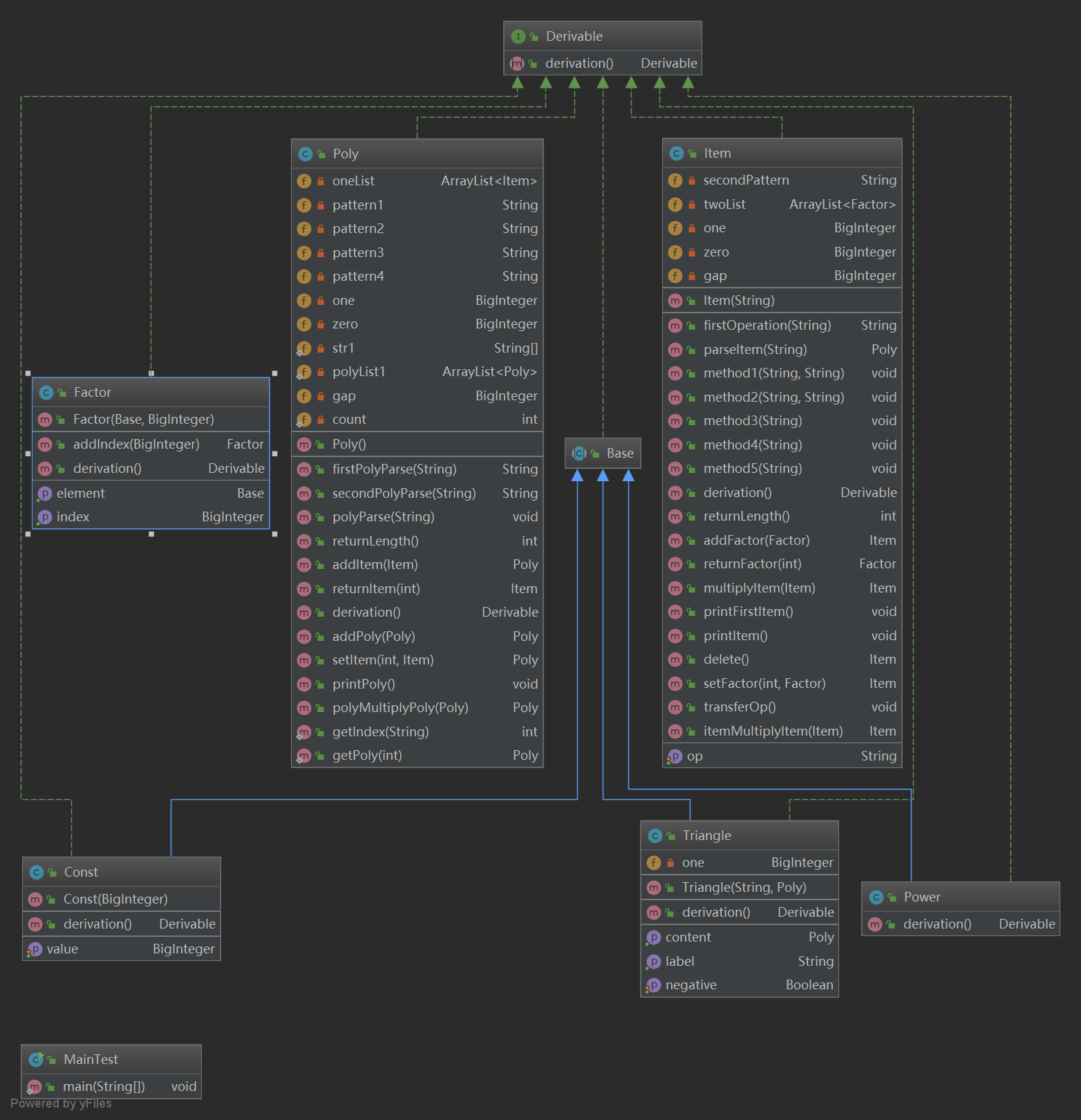 本次作業的架構和上一次作業是完全一致的,因為上次作業時我就考慮到了程式可擴展性的特點。然而本次作業在加了表達式因數和嵌套因數後顯得這個架構有一些問題。求導部分利用遞歸向下求導的方式倒是不難實現,此次作業最難的輸入部分我處理的不是很好。這次輸入的難點主要是出現了表達式因數和嵌套,我們如何用正則表達式來正確的識別和解析。我的想法是先找到所有非三角函數括弧中最內層的括弧,將其解析為一個多項式,這時再解析出該多項式內部的三角函數,把三角函數括弧中嵌套的多項式因數解析到三角函數的屬性中去,重覆這個步驟直到沒有括弧為止。整個過程雖然可以實現但是十分複雜,十分面向過程且會有多分支,行數非常多的方法,複雜的正則表達式的存在。後來在討論課上聽說的用工廠模式或一個parser的類可以更好的實現該輸入解析過程,parser類裡面分別有對poly,item,factor的解析方法,高內聚低耦合避免了一大串if-else的出現。
本次作業的架構和上一次作業是完全一致的,因為上次作業時我就考慮到了程式可擴展性的特點。然而本次作業在加了表達式因數和嵌套因數後顯得這個架構有一些問題。求導部分利用遞歸向下求導的方式倒是不難實現,此次作業最難的輸入部分我處理的不是很好。這次輸入的難點主要是出現了表達式因數和嵌套,我們如何用正則表達式來正確的識別和解析。我的想法是先找到所有非三角函數括弧中最內層的括弧,將其解析為一個多項式,這時再解析出該多項式內部的三角函數,把三角函數括弧中嵌套的多項式因數解析到三角函數的屬性中去,重覆這個步驟直到沒有括弧為止。整個過程雖然可以實現但是十分複雜,十分面向過程且會有多分支,行數非常多的方法,複雜的正則表達式的存在。後來在討論課上聽說的用工廠模式或一個parser的類可以更好的實現該輸入解析過程,parser類裡面分別有對poly,item,factor的解析方法,高內聚低耦合避免了一大串if-else的出現。
二、Bug分析
1. 第一次作業
第一次作業我的強測沒有出現WA的情況,但是被hack了12次(2同質),分別是\\s+匹配到\t和空格外的字元的情況、以及直接輸入空格程式crash的情況,程式crash的原因是我在得到字元串之後直接進行了input.trim()操作,導致輸入input變為空串程式crash,有兩種更改方式,一種是直接把main方法裡面的所有內容用try-catch保住,確保程式不會出現crash(這也是我後面兩次作業的寫法),另一種方法是在trim()後面再判斷一次串是否為空。對於另外一個bug,我的正則裡面寫的是[ \\t]*然而還是出現了bug,這與我程式的設計結構密切相關,因為我再剛剛讀入input的時候就用trim()去掉了兩邊的空白符,這樣導致輸入字元串兩邊的\v和\f無法有效的識別WF,造成了bug的出現。我的修改方式是先看所有的輸入字元是否有非法字元,如果有的話直接輸出WF即可。
2. 第二次作業
第一次作業我的強測沒有出現WA的情況,但是也被hack了3次(2同質),分別是在輸入符號處理中的if表達式中的||手誤寫成了&&,和對於輸入錯誤的匹配沒有識別出WF。仔細想想,這與我的設計結構也有著千絲萬縷的聯繫。我對於輸入的處理是在去掉了輸入兩邊的空白字元後依據此時input.CharAt(0)來確定在前面添加"+"或者"+0",然而我沒考慮到*x若在前面"+0"會造成本來是WF的數據變成合法,因此導致了bug。另外一個bug就是典型的一大段if-else造成的鍵盤誤操作,這也體現了減少分支數量降低代碼複雜度的必要性。
3. 第三次作業
第三次作業我的強測WA兩個點,被hack了10次(強互測加起來2同質),分別是輸入匹配時正則表達式少了一個[ \\t]*造成的有空格導致不匹配以及一個符號出現了問題。這兩個問題的產生就與我的設計非常密切的相關了。我寫了4個正則,其中最大的正則有6行,如此長的正則難免會不小心失誤,寫小正則把問題分開分析是避免這類錯誤的一個很好的方式。而另外一個符號錯誤則完全是由於我的輸入寫得太過複雜,括弧來回匹配的邏輯,比如解析一個item,會返回一個poly.解析一個factor也會返回poly,而每個item都有其固定的符號,這次Bug的出現就是因為在解析item返回poly的時候沒有考慮原來item的符號,而預設"+"造成了錯誤。由此可見,面向對象的設計模式,封裝的好處就是減少耦合,減少出錯點。
三、Hack策略
1. WF
前兩次作業錯誤主要集中在WF上,這時候就可以手動設計測試樣例,比如全空格,空串,只輸入常數,輸入x^0,0*x,si n(x),sin ( x ),+++1,++ 1,\f\v,BigInteger,爆棧,......等等,因為前兩次作業正確性的實現上並不難,主要大家的出錯點在對WF的處理上,因此我的這種策略有效性也很高,前兩次作業共提交7個測試樣例hack18人次。
2. 正確性問題
第三次作業強調正確性的問題,我也從正確性的問題入手,具體方法就是對於指導書上對本次實驗要求的所有功能,先分別構造測試數據,在將各種模式組合起來,比如sin()裡面有表達式,裡面還有嵌套的sin(),再加一些項乘起來之類的。覆蓋所有的情況覆蓋所有的功能就能找出bug。由於第三次作業大家基本都沒怎麼優化,所以直接看輸出結果很難看出正誤,因此可以把每位被測者的輸出結果賦上一個x值(比如x=1.1)比較不同被測者輸出結果的值是否相等,若不相等顯然是出現了問題。
3. 根據程式找bug
這種方法難度較大,主要原因是部分代碼可讀性較差,結構不清晰,等等。當然如果能看懂對方程式的話肯定是更容易從根源處找到bug。通過白盒測試,對複雜的類進行單元測試來尋找bug。
四、Applying Creational Pattern
1. 工廠模式
工廠模式(Factory Pattern)是Java中最常用的設計模式之一,這種類型的設計模式屬於創建型模式,它提供了一種創建對象的最佳方式。在工廠模式中,我們在創建對象時不會對客戶端暴露創建邏輯,並且是通過使用一個共同的介面來指向新創建的對象。因此,對於本次作業可以使用工廠模式來創建表達式,項,因數,我們只需定義一個創建對象的介面,讓實現了該介面的子類自己決定實例化哪一個工廠類。在我們明確地計劃不同條件下創建不同實例時,工廠模式將十分管用。
2. 抽象工廠
抽象工廠模式(Abstract Factory Pattern)是圍繞一個超級工廠創建其他工廠。超級工廠又稱為其他工廠的工廠,在抽象工廠模式中,介面是負責創建一個相關對象的工廠,不需要顯式指定它們的類。每個生成的工廠都能按照工廠模式提供對象。系統的產品有多於一個的產品族,而系統只消費其中某一族的產品時,可以使用抽象工廠作為所有工廠的抽象父類,這樣我們就不用花費時間在選擇介面上了。
五、總結與展望
1. 總結
4周時間過去了,OO也過去了第一單元,早就聽說了OO的恐怖,如今也確實是體驗了一番。總體來講第一單元的學習還算滿意,測試方面仍需加強,另外就是面向對象的思想還需不斷的培養。第一單元其實主要還是java的入門,幫助我們更加熟悉java的使用。還有就是感覺今年的OO確實感覺要比往屆好了不少,公測分占主要的情況下大體上保證了課程的公平,分ABC組互測也避免了一些悲慘的情況,總體來講OO課在不斷變好,在此感謝助教和老師的付出!
2. 展望
前路漫漫,道阻且長。後面還有多線程等等很難的知識和作業在等著我們,希望我們能繼續努力,在本學期結束時能真正有很大的收穫。


