
隨著互聯網信息技術日新月異的發展,一個海量數據爆炸的時代已經到來。如何有效地處理、分析這些海量的數據資源,成為各大技術廠商爭在激烈的競爭中脫穎而出的一個利器。可以說,如果不能很好的快速處理分析這些海量的數據資源,將很快被市場無情地所淘汰。當然,處理分析這些海量數據目前可以借鑒的方案有很多:首先,在分 ...
隨著互聯網信息技術日新月異的發展,一個海量數據爆炸的時代已經到來。如何有效地處理、分析這些海量的數據資源,成為各大技術廠商爭在激烈的競爭中脫穎而出的一個利器。可以說,如果不能很好的快速處理分析這些海量的數據資源,將很快被市場無情地所淘汰。當然,處理分析這些海量數據目前可以借鑒的方案有很多:首先,在分散式計算方面有Hadoop裡面的MapReduce並行計算框架,它主要針對的是離線的數據挖掘分析。此外還有針對實時線上流式數據處理方面的,同樣也是分散式的計算框架Strom,也能很好的滿足數據實時性分析、處理的要求。最後還有Spring Batch,這個完全面向批處理的框架,可以大規模的應用於企業級的海量數據處理。
在這裡,我就不具體展開說明這些框架如何部署、以及如何開發使用的詳細教程說明。我想在此基礎上更進一步:我們能否借鑒這些開源框架背後的技術背景,為服務的企業或者公司,量身定製一套符合自身數據處理要求的批處理框架。
首先我先描述一下,目前我所服務的公司所面臨的一個用戶數據存儲處理的一個現狀背景。目前移動公司一個省內在網用戶數據規模達到幾千萬的規模數量級,而且每個省已經根據地市區域對用戶數據進行劃分,我們把這批數據存儲在傳統的關係型資料庫上面(基於Oracle,地市是分區)。移動公司的計費結算系統會根據用戶手機話費的餘額情況,實時的通知業務處理系統,給手機用戶進行停機、復機的操作。業務處理系統收到計費結算系統的請求,會把要處理的用戶數據往具體的交換機網元上派發不同的交換機指令,這裡簡單的可以稱為Hlr停復機指令(下麵開始本文都簡稱Hlr指令)。目前面臨的現狀是,在日常情況下,傳統的C++多進程的後臺處理程式還能勉強的“準實時”地處理這些數據請求,但是,如果一旦到了每個月的月初幾天,要處理的數據量往往會暴增,而C++後臺程式處理的效率並不高。這時問題來了,往往會有用戶投訴,自己繳費了,為什麼沒有復機?或者某些用戶明明已經欠費了,但是還沒有及時停機。這樣的結果會直接降低客戶對移動運營商支撐的滿意度,於此同時,移動運營商本身也可能流失這些客戶資源。
自己認真評估了一下,造成上述問題的幾個瓶頸所在。
- 一個省所有的用戶數據都放在資料庫的一個實體表中,資料庫伺服器,滿打滿算達到頂級小型機配置,也可能無法滿足月初處理量激增的性能要求,可以說頻繁的在一臺伺服器上讀寫IO開銷非常巨大,整個伺服器處理的性能低下。
- 處理這些數據的時候,會同步地往交換機物理設備上發送Hlr指令,在交換機沒有處理成功這個請求指令的時候,只能阻塞等待,進一步造成後續待處理數據的積壓。
針對上述的問題,本人想到了幾個優化方案。
- 資料庫中的實體表,能不能根據用戶的歸屬地市進行表實體的拆分。即把一臺或者幾台伺服器的壓力,進行水平拆分。一臺資料庫伺服器就重點處理某一個或者幾個地市的數據請求?降低IO開銷。
- 由於交換機處理Hlr指令的時候,存在阻塞操作,我們能不能改成:通過非同步返回處理的方式,把處理任務隊列中的任務先下達通知給交換機,然後交換機通過非同步回調機制,反向通知處理模塊,彙報任務的執行情況。這樣處理模塊就從主動的任務輪詢等待,變成等待交換機執行結果的非同步通知,這樣它就可以專註地進行處理數據的派發,不會受到某幾個任務處理時長的限制,從而影響到後面整批次的數據處理。
- 資料庫的實體表由於進行水平拆解,能不能做到並行載入?這樣就會大大節約串列數據載入的處理時長。
- 並行載入出來的待處理數據最好能放到一個批處理框架裡面,批處理框架能很好地根據要處理數據的情況,進行配置參數調整,從而很好地滿足實時性的要求。比如月初期間,可以加大處理參數的值,提高處理效率。平常的時候,可以適當降低處理參數的取值,降低系統的CPU/IO開銷。
基於以上幾點考慮,得出如下圖所示的設計方案的組件圖:
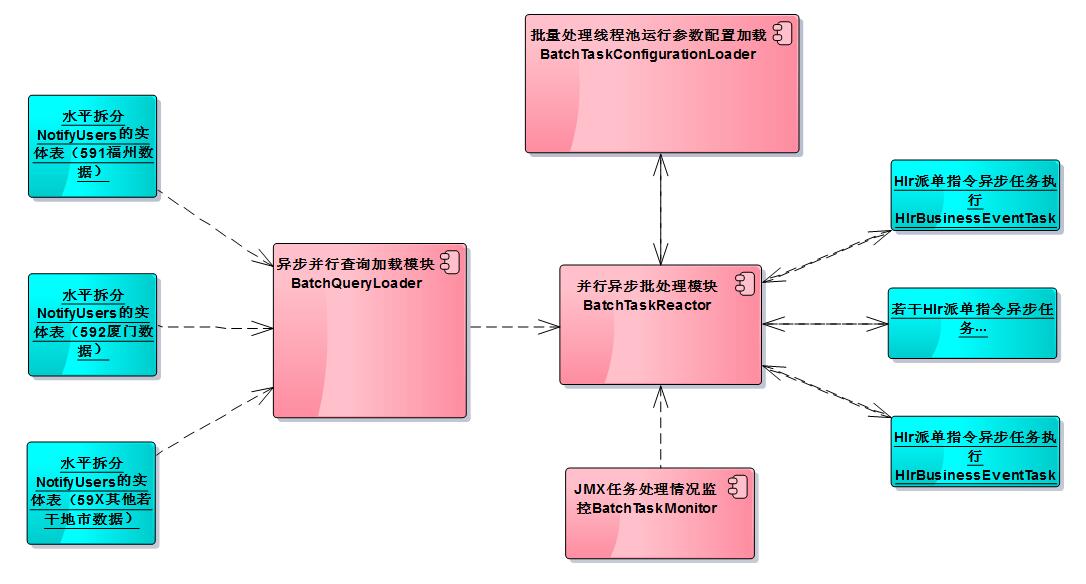
下麵就具體說明一下,其中關鍵模塊如何協同工作的。
- 非同步並行查詢載入模塊BatchQueryLoader:支持傳入多個數據源對象,同時利用google-guava庫中對於Future介面的擴展ListenableFuture,來實現批量查詢數據的並行載入。Future介面主要是用來表示非同步計算的結果,並且計算完成的時候,只能用get()方法獲取結果,get方法裡面其中有一個方法是可以設置超時時間的。在並行載入模塊裡面,批量並行地載入多個數據源裡面的實體表中的數據,並最終反饋載入的結果集合。並行數據載入和串列數據載入所用的耗時可以簡單用下麵的圖例來說明:串列載入的總耗時是每個數據源載入耗時的總和。而並行載入的總耗時,取決於最大載入的那個數據源耗時時長。(註:我們把每天要進行停復機處理的用戶數據通過採集程式,分地市分佈採集到水平分庫的notify_users提醒用戶表)

- 並行非同步批處理模塊BatchTaskReactor:內部是通過線程池機制來實現的,接受非同步並行查詢載入模塊BatchQueryLoader得到的載入結果數據,放入線程池中進行任務的非同步派發,它最終就是通過Hlr派單指令非同步任務執行HlrBusinessEventTask模塊下髮指令任務,然後自己不斷的從阻塞隊列中獲取,待執行的任務列表進行任務的分派。與此同時,他通過Future介面,非同步得到HlrBusinessEventTask派髮指令的執行反饋結果。
- 批量處理線程池運行參數配置載入BatchTaskConfigurationLoader:載入線程池運行參數的配置,把結果通知並行非同步批處理模塊BatchTaskReactor,配置文件batchtask-configuration.xml的內容如下所示。
<?xml version="1.0" encoding="GBK"?> <batchtask> <!-- 批處理非同步線程池參數配置 --> <jobpool name="newlandframework_batchtask"> <attribute name="corePoolSize" value="15" /> <attribute name="maxPoolSize" value="30" /> <attribute name="keepAliveTime" value="1000" /> <attribute name="workQueueSize" value="200" /> </jobpool> </batchtask>
其中corePoolSize表示保留的線程池大小,workQueueSize表示的是阻塞隊列的大小,maxPoolSize表示的是線程池的最大大小,keepAliveTime指的是空閑線程結束的超時時間。其中創建線程池方法ThreadPoolExecutor裡面有個參數是unit,它表示一個枚舉,即keepAliveTime的單位。說了半天,這幾個參數到底什麼關係呢?我舉一個例子說明一下,當出現需要處理的任務的時候,ThreadPoolExecutor會分配corePoolSize數量的線程池去處理,如果不夠的話,會把任務放入阻塞隊列,阻塞隊列的大小是workQueueSize,當然這個時候還可能不夠,怎麼辦。只能叫來“臨時工線程”幫忙處理一下,這個時候“臨時工線程”的數量是maxPoolSize-corePoolSize,當然還會繼續不夠,這個時候ThreadPoolExecutor線程池會採取4種處理策略。
-
現在具體說一下是那些處理策略。首先是ThreadPoolExecutor.AbortPolicy 中,處理程式遭到拒絕將拋出運行時 RejectedExecutionException。然後是ThreadPoolExecutor.CallerRunsPolicy 中,線程調用運行該任務的 execute 本身。此策略提供簡單的反饋控制機制,能夠減緩新任務的提交速度。其次是,ThreadPoolExecutor.DiscardPolicy 中,不能執行的任務將被刪除。最後是ThreadPoolExecutor.DiscardOldestPolicy 中,如果執行程式尚未關閉,則位於工作隊列頭部的任務將被刪除,然後重試執行程式(如果再次失敗,則重覆此過程)。如果要處理的任務沒有那麼多了,ThreadPoolExecutor線程池會根據keepAliveTime設置的時間單位來回收多餘的“臨時工線程”。你可以把keepAliveTime理解成專門是為maxPoolSize-corePoolSize的“臨時工線程”專用的。
-
線程池參數的設定。正常情況下我們要如何設置線程池的參數呢?我們應該這樣設置:I、workQueueSize阻塞隊列的大小至少大於等於corePoolSize的大小。II、maxPoolSize線程池的大小至少大於等於corePoolSize的大小。III、corePoolSize是你期望處理的預設線程數,個人覺得線程池機制的話,至少大於1吧?不然的話,你這個線程池等於單線程處理任務了,這樣就失去了線程池設計存在的意義了。
- JMX(Java Management Extensions)批處理任務監控模塊BatchTaskMonitor:實時地監控線程池BatchTaskReactor中任務的執行處理情況(具體就是任務成功/失敗情況)。
介紹完畢了幾個核心模塊主要的功能,那下麵就依次介紹一下主要模塊的詳細設計思路。
- 我們把每天要進行停復機處理的用戶數據通過採集程式,採集到notify_users表。首先定義的是,我們要處理採集的通知用戶數據對象的結構描述,它對應水平分庫的表notify_users的JavaBean對象。notify_users的表結構為了演示起見,簡單設計如下(基於Oracle資料庫):
create table notify_users
對應JavaBean實體類NotifyUsers,具體代碼定義如下:
(
home_city number(3) /*手機用戶的歸屬地市編碼*/,
msisdn number(15) /*手機號碼*/,
user_id number(15) /*手機用戶的用戶標識*/
);/** * @filename:NotifyUsers.java * * Newland Co. Ltd. All rights reserved. * * @Description:要進行批處理通知的用戶對象 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.model; import org.apache.commons.lang.builder.ToStringBuilder; import org.apache.commons.lang.builder.ToStringStyle; public class NotifyUsers { public NotifyUsers() { } // 用戶歸屬地市編碼(這裡具體是:591表示福州/592表示廈門) private Integer homeCity; // 用戶的手機號碼 private Integer msisdn; // 用戶標識 private Integer userId; public Integer getHomeCity() { return homeCity; } public void setHomeCity(Integer homeCity) { this.homeCity = homeCity; } public Integer getMsisdn() { return msisdn; } public void setMsisdn(Integer msisdn) { this.msisdn = msisdn; } public Integer getUserId() { return userId; } public void setUserId(Integer userId) { this.userId = userId; } public String toString() { return new ToStringBuilder(this, ToStringStyle.SHORT_PREFIX_STYLE) .append("homeCity", homeCity).append("userId", userId) .append("msisdn", msisdn).toString(); } }
- 非同步並行查詢載入模塊BatchQueryLoader的類圖結構:
 我們通過並行查詢載入模塊BatchQueryLoader調用非同步並行查詢執行器BatchQueryExecutor,來並行地載入不同數據源的查詢結果集合。StatementWrapper則是對JDBC裡面Statement的封裝。具體代碼如下所示:
我們通過並行查詢載入模塊BatchQueryLoader調用非同步並行查詢執行器BatchQueryExecutor,來並行地載入不同數據源的查詢結果集合。StatementWrapper則是對JDBC裡面Statement的封裝。具體代碼如下所示: -
/** * @filename:StatementWrapper.java * * Newland Co. Ltd. All rights reserved. * * @Description:Statement封裝類 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.parallel; import java.sql.Connection; import java.sql.Statement; public class StatementWrapper { private final String sql; private final Statement statement; private final Connection con; public StatementWrapper(String sql, Statement statement, Connection con) { this.sql = sql; this.statement = statement; this.con = con; } public String getSql() { return sql; } public Statement getStatement() { return statement; } public Connection getCon() { return con; } }
定義兩個並行載入的異常類BatchQueryInterruptedException、BatchQueryExecutionException
/** * @filename:BatchQueryInterruptedException.java * * Newland Co. Ltd. All rights reserved. * * @Description:並行查詢載入InterruptedException異常類 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.parallel; public class BatchQueryInterruptedException extends RuntimeException { public BatchQueryInterruptedException(final String errorMessage, final Object... args) { super(String.format(errorMessage, args)); } public BatchQueryInterruptedException(final Exception cause) { super(cause); } }
/** * @filename:BatchQueryExecutionException.java * * Newland Co. Ltd. All rights reserved. * * @Description:並行查詢載入ExecutionException異常類 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.parallel; public class BatchQueryExecutionException extends RuntimeException { public BatchQueryExecutionException(final String errorMessage, final Object... args) { super(String.format(errorMessage, args)); } public BatchQueryExecutionException(final Exception cause) { super(cause); } }
再抽象出一個批量查詢介面,主要是為了後續能擴展在不同的資料庫之間進行批量載入。介面類BatchQuery定義如下
/** * @filename:BatchQuery.java * * Newland Co. Ltd. All rights reserved. * * @Description:非同步查詢介面定義 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.parallel; public interface BatchQuery<IN, OUT> { OUT query(IN input) throws Exception; }
好了,現在封裝一個非同步並行查詢執行器BatchQueryExecutor
/** * @filename:BatchQueryExecutor.java * * Newland Co. Ltd. All rights reserved. * * @Description:非同步並行查詢執行器 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.parallel; import com.google.common.util.concurrent.ListenableFuture; import com.google.common.util.concurrent.ListeningExecutorService; import com.google.common.util.concurrent.FutureCallback; import com.google.common.util.concurrent.Futures; import com.google.common.util.concurrent.MoreExecutors; import org.apache.commons.collections.Closure; import org.apache.commons.collections.CollectionUtils; import org.apache.commons.collections.functors.ForClosure; import java.util.concurrent.Callable; import java.util.concurrent.ExecutionException; import java.util.concurrent.Executors; import java.util.Collection; import java.util.HashSet; import java.util.List; import java.util.Set; public class BatchQueryExecutor { private final static int FUTUREQUERYNUMBER = 1; public BatchQueryExecutor() { } public <IN, OUT> List<OUT> executeQuery(final Collection<IN> inputs,final BatchQuery<IN, OUT> executeUnit) { ListenableFuture<List<OUT>> futures = submitBatchTaskFutures(inputs,executeUnit); delegateAsynTask(futures); return getAsynResults(futures); } private <IN, OUT> ListenableFuture<List<OUT>> submitBatchTaskFutures( final Collection<IN> inputs, final BatchQuery<IN, OUT> executeUnit) { final Set<ListenableFuture<OUT>> result = new HashSet<ListenableFuture<OUT>>( inputs.size()); final ListeningExecutorService service = MoreExecutors .listeningDecorator(Executors.newFixedThreadPool(inputs.size())); Closure futureQuery = new Closure() { public void execute(Object input) { final IN p = (IN) input; result.add(service.submit(new Callable<OUT>() { @Override public OUT call() throws Exception { return executeUnit.query(p); } })); } }; Closure parallelTask = new ForClosure(FUTUREQUERYNUMBER, futureQuery); CollectionUtils.forAllDo(inputs, parallelTask); service.shutdown(); return Futures.allAsList(result); } private <OUT> OUT getAsynResults(final ListenableFuture<OUT> futures) { try { return futures.get(); } catch (InterruptedException ex) { throw new BatchQueryInterruptedException(ex); } catch (ExecutionException ex) { throw new BatchQueryExecutionException(ex); } } private <TYPE> void delegateAsynTask( final ListenableFuture<TYPE> allFutures) { Futures.addCallback(allFutures, new FutureCallback<TYPE>() { @Override public void onSuccess(final TYPE result) { System.out.println("並行載入查詢執行成功"); } @Override public void onFailure(final Throwable thrown) { System.out.println("並行載入查詢執行失敗"); } }); } }
最後的並行查詢載入模塊BatchQueryLoader直接就是調用上面的非同步並行查詢執行器BatchQueryExecutor,完成不同數據源的數據並行非同步載入,代碼如下
/** * @filename:BatchQueryLoader.java * * Newland Co. Ltd. All rights reserved. * * @Description:並行查詢載入模塊 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.parallel; import java.sql.Connection; import java.sql.ResultSet; import java.sql.SQLException; import java.sql.Statement; import java.util.ArrayList; import java.util.Arrays; import java.util.Collection; import java.util.Iterator; import java.util.List; public class BatchQueryLoader { private final Collection<StatementWrapper> statements = new ArrayList<StatementWrapper>(); public void attachLoadEnv(final String sql, final Statement statement, final Connection con) { statements.add(new StatementWrapper(sql, statement, con)); } public Collection<StatementWrapper> getStatements() { return statements; } public void close() throws SQLException { Iterator<StatementWrapper> iter = statements.iterator(); while (iter.hasNext()) { iter.next().getCon().close(); } } public List<ResultSet> executeQuery() throws SQLException { List<ResultSet> result; if (1 == statements.size()) { StatementWrapper entity = statements.iterator().next(); result = Arrays.asList(entity.getStatement().executeQuery( entity.getSql())); return result; } else { BatchQueryExecutor query = new BatchQueryExecutor(); result = query.executeQuery(statements, new BatchQuery<StatementWrapper, ResultSet>() { @Override public ResultSet query(final StatementWrapper input) throws Exception { return input.getStatement().executeQuery( input.getSql()); } }); return result; } } }
- 批量處理線程池運行參數配置載入BatchTaskConfigurationLoader模塊,主要從負責從batchtask-configuration.xml中載入線程池的運行參數。BatchTaskConfiguration批處理線程池運行參數對應的JavaBean結構
/** * @filename:BatchTaskConfiguration.java * * Newland Co. Ltd. All rights reserved. * * @Description:批處理線程池參數配置 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.parallel; import org.apache.commons.lang.builder.EqualsBuilder; import org.apache.commons.lang.builder.HashCodeBuilder; import org.apache.commons.lang.builder.ToStringBuilder; import org.apache.commons.lang.builder.ToStringStyle; public class BatchTaskConfiguration { private String name; private int corePoolSize; private int maxPoolSize; private int keepAliveTime; private int workQueueSize; public void setName(String name) { this.name = name; } public String getName() { return this.name; } public int getCorePoolSize() { return corePoolSize; } public void setCorePoolSize(int corePoolSize) { this.corePoolSize = corePoolSize; } public int getMaxPoolSize() { return maxPoolSize; } public void setMaxPoolSize(int maxPoolSize) { this.maxPoolSize = maxPoolSize; } public int getKeepAliveTime() { return keepAliveTime; } public void setKeepAliveTime(int keepAliveTime) { this.keepAliveTime = keepAliveTime; } public int getWorkQueueSize() { return workQueueSize; } public void setWorkQueueSize(int workQueueSize) { this.workQueueSize = workQueueSize; } public int hashCode() { return new HashCodeBuilder(1, 31).append(name).toHashCode(); } public String toString() { return new ToStringBuilder(this, ToStringStyle.SHORT_PREFIX_STYLE) .append("name", name).append("corePoolSize", corePoolSize) .append("maxPoolSize", maxPoolSize) .append("keepAliveTime", keepAliveTime) .append("workQueueSize", workQueueSize).toString(); } public boolean equals(Object o) { boolean res = false; if (o != null && BatchTaskConfiguration.class.isAssignableFrom(o.getClass())) { BatchTaskConfiguration s = (BatchTaskConfiguration) o; res = new EqualsBuilder().append(name, s.getName()).isEquals(); } return res; } }
當然了,你進行參數配置的時候,還可以指定多個線程池,於是要設計一個:批處理線程池工廠類BatchTaskThreadFactoryConfiguration,來依次迴圈保存若幹個線程池的參數配置
/** * @filename:BatchTaskThreadFactoryConfiguration.java * * Newland Co. Ltd. All rights reserved. * * @Description:線程池參數配置工廠 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.parallel; import java.util.Map; import java.util.HashMap; public class BatchTaskThreadFactoryConfiguration { // 批處理線程池參數配置 private Map<String, BatchTaskConfiguration> batchTaskMap = new HashMap<String, BatchTaskConfiguration>(); public BatchTaskThreadFactoryConfiguration() { } public void joinBatchTaskConfiguration(BatchTaskConfiguration batchTaskConfiguration) { if (batchTaskMap.containsKey(batchTaskConfiguration.getName())) { return; }else{ batchTaskMap.put(batchTaskConfiguration.getName(), batchTaskConfiguration); } } public Map<String, BatchTaskConfiguration> getBatchTaskMap() { return batchTaskMap; } }
剩下的是,載入運行時參數配置模塊BatchTaskConfigurationLoader
/** * @filename:BatchTaskConfigurationLoader.java * * Newland Co. Ltd. All rights reserved. * * @Description:線程池參數配置載入 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.parallel; import java.io.InputStream; import org.apache.commons.digester.Digester; public final class BatchTaskConfigurationLoader { private static final String BATCHTASK_THREADPOOL_CONFIG = "./newlandframework/batchtask/parallel/batchtask-configuration.xml"; private static BatchTaskThreadFactoryConfiguration config = null; private BatchTaskConfigurationLoader() { } // 單例模式為了控制併發要進行同步控制 public static BatchTaskThreadFactoryConfiguration getConfig() { if (config == null) { synchronized (BATCHTASK_THREADPOOL_CONFIG) { if (config == null) { try { InputStream is = getInputStream(); config = (BatchTaskThreadFactoryConfiguration) getDigester().parse(getInputStream()); } catch (Exception e) { e.printStackTrace(); } } } } return config; } private static InputStream getInputStream() { return BatchTaskConfigurationLoader.class.getClassLoader() .getResourceAsStream(BATCHTASK_THREADPOOL_CONFIG); } private static Digester getDigester() { Digester digester = new Digester(); digester.setValidating(false); digester.addObjectCreate("batchtask", BatchTaskThreadFactoryConfiguration.class); // 載入批處理非同步批處理線程池參數配置 digester.addObjectCreate("*/jobpool", BatchTaskConfiguration.class); digester.addSetProperties("*/jobpool"); digester.addSetProperty("*/jobpool/attribute", "name", "value"); digester.addSetNext("*/jobpool", "joinBatchTaskConfiguration"); return digester; } }
上面的這些模塊主要是針對線程池的運行參數可以調整而設計準備的。
- 並行非同步批處理模塊BatchTaskReactor主要類圖結構如下
 BatchTaskRunner這個介面,主要定義了批處理框架要初始化和回收資源的動作。
BatchTaskRunner這個介面,主要定義了批處理框架要初始化和回收資源的動作。
/** * @filename:BatchTaskRunner.java * * Newland Co. Ltd. All rights reserved. * * @Description:批處理資源管理定義介面 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.parallel; import java.io.Closeable; public interface BatchTaskRunner extends Closeable { public void initialize(); public void close(); }
我們還要重新實現一個線程工廠類BatchTaskThreadFactory,用來管理我們線程池當中的線程。我們可以把線程池當中的線程放到線程組裡面,進行統一管理。比如線程池中的線程,它的運行狀態監控等等處理,你可以通過重新生成一個監控線程,
來運行、跟蹤線程組裡麵線程的運行情況。當然你還可以重新封裝一個JMX(Java Management Extensions)的MBean對象,通過JMX方式對線程池進行監控處理,本文的後面,有給出運用JMX技術,進行批處理線程池任務完成情況監控的實現,實現線程池中線程運行狀態的監控可以參考一下。這裡就不具體給出,線程池線程狀態監控的JMX模塊代碼了。言歸正傳,線程工廠類BatchTaskThreadFactory的實現如下/** * @filename:BatchTaskThreadFactory.java * * Newland Co. Ltd. All rights reserved. * * @Description:線程池工廠 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.parallel; import java.util.concurrent.atomic.AtomicInteger; import java.util.concurrent.ThreadFactory; public class BatchTaskThreadFactory implements ThreadFactory { final private static String BATCHTASKFACTORYNAME = "batchtask-pool"; final private String name; final private ThreadGroup threadGroup; final private AtomicInteger threadNumber = new AtomicInteger(0); public BatchTaskThreadFactory() { this(BATCHTASKFACTORYNAME); } public BatchTaskThreadFactory(String name) { this.name = name; SecurityManager security = System.getSecurityManager(); threadGroup = (security != null) ? security.getThreadGroup() : Thread.currentThread().getThreadGroup(); } @Override public Thread newThread(Runnable runnable) { Thread thread = new Thread(threadGroup, runnable); thread.setName(String.format("BatchTask[%s-%d]", threadGroup.getName(), threadNumber.incrementAndGet())); System.out.println(String.format("BatchTask[%s-%d]", threadGroup.getName(), threadNumber.incrementAndGet())); if (thread.isDaemon()) { thread.setDaemon(false); } if (thread.getPriority() != Thread.NORM_PRIORITY) { thread.setPriority(Thread.NORM_PRIORITY); } return thread; } }
下麵是關鍵模塊:並行非同步批處理模塊BatchTaskReactor的實現代碼,主要還是對ThreadPoolExecutor進行地封裝,考慮使用有界的數組阻塞隊列ArrayBlockingQueue,還是為了防止:生產者無休止的請求服務,導致記憶體崩潰,最終做到記憶體使用可控
採取的措施。/** * @filename:BatchTaskReactor.java * * Newland Co. Ltd. All rights reserved. * * @Description:批處理並行非同步線程池處理模塊 * @author tangjie * @version 1.0 * */ package newlandframework.batchtask.parallel; import java.util.Set; import java.util.Map; import java.util.Map.Entry; import java.util.concurrent.ExecutorService; import java.util.concurrent.ThreadPoolExecutor; import java.util.concurrent.ArrayBlockingQueue; import java.util.concurrent.BlockingQueue; import java.util.concurrent.ConcurrentHashMap; import java.util.concurrent.TimeUnit; import java.util.concurrent.locks.Lock; import java.util.concurrent.locks.ReentrantLock; public final class BatchTaskReactor implements BatchTaskRunner { private Map<String, ExecutorService> threadPools = new ConcurrentHashMap<String, ExecutorService>(); private static BatchTaskReactor context; private static Lock REACTORLOCK = new ReentrantLock(); public static final String BATCHTASK_THREADPOOL_NAME = "newlandframework_batchtask"; private BatchTaskReactor() { initialize(); } // 防止併發重覆創建批處理反應器對象 public static BatchTaskReactor getReactor() { if (context == null) { try { REACTORLOCK.lock(); if (context == null) { context = new BatchTaskReactor(); } } finally { REACTORLOCK.unlock(); } } return context; } public ExecutorService getBatchTaskThreadPoolName() { return getBatchTaskThreadPool(BATCHTASK_THREADPOOL_NAME); } public ExecutorService getBatchTaskThreadPool(String poolName) { if (!threadPools.containsKey(poolName)) { throw new IllegalArgumentException(String.format( "批處理線程池名稱:[%s]參數配置不存在", poolName)); } return threadPools.get(poolName); } public Set<String> getBatchTaskThreadPoolNames() { return threadPools.keySet(); } // 關閉線程池,同時等待非同步執行的任務返回執行結果 public void close() { for (Entry<String, ExecutorService> entry : threadPools.entrySet()) { entry.getValue().shutdown(); System.out.println(String.format("關閉批處理線程池:[%s]成功", entry.getKey())); } threadPools.clear(); } // 初始化批處理線程池 public

