
一、 lucene簡介 1. Lucene Lucene是apache下的一個開源的全文檢索引擎工具包。它為軟體開發人員提供一個簡單易用的工具包(類庫),以方便的在目標系統中實現全文檢索的功能。 官網: http://lucene.apache.org/ 2. 全文檢索 全文檢索是指電腦索引程式通 ...
一、 lucene簡介
1. Lucene
Lucene是apache下的一個開源的全文檢索引擎工具包。它為軟體開發人員提供一個簡單易用的工具包(類庫),以方便的在目標系統中實現全文檢索的功能。
2. 全文檢索
全文檢索是指電腦索引程式通過掃描文章中的每一個詞,對每一個詞建立一個索引,指明該詞在文章中出現的次數和位置,當用戶查詢時,檢索程式就根據事先建立的索引進行查找,並將查找的結果反饋給用戶的檢索方式。這個過程類似於通過字典中的檢索字表查字的過程。
總結:先建索引再通過索引進行查詢
3. 全文檢索的應用場景
註意:Lucene和搜索引擎是不同的,Lucene是一套用java或其它語言寫的全文檢索的
工具包。它為應用程式提供了很多個api介面去調用,可以簡單理解為是一套實現全文檢索的類庫。搜索引擎是一個全文檢索系統,它是一個單獨運行的軟體系統。
4. 為什麼要使用全文檢索
1.搜索速度:將數據源中的數據都通過全文索引
2.匹配效果:詞語進行匹配,通過語言分析介面的實現,可以實現對中文等非英語的支持。
3.相關度:有匹配度演算法,將匹配程度(相似度)比較高的結果排在前面。
4.適用場景:關係資料庫中進行模糊查詢時,資料庫自帶的索引將不起作用,此時需要通過全文檢索來提高速度;比如:網站系統中針對內容的模糊查詢select * from article where content like ‘%廣州
5. lucene全文檢索流程
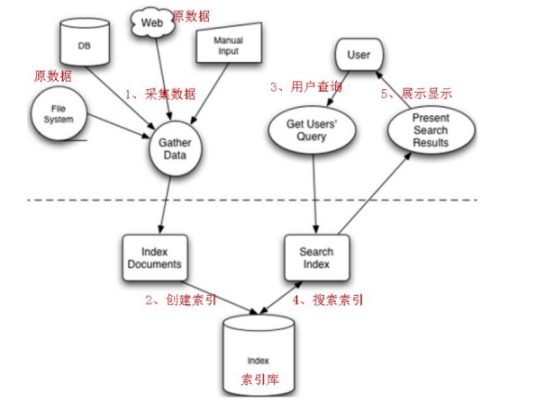
全文檢索的流程分為兩大部分:索引流程、搜索流程。
索引流程:即採集數據構建文檔對象分析文檔(分詞)創建索引。
搜索流程:即用戶通過搜索界面創建查詢執行搜索,搜索器從索引庫搜索渲染搜索結果.
6. 索引流程
對文檔索引的過程,就是將用戶要搜索的文檔內容進行索引,然後把索引存儲在索引庫(index)中。
6.1 採集數據
全文檢索要搜索的數據信息格式多種多樣,拿搜索引擎(百度, google)來說,通過搜索引擎網站能搜索互聯網站上的網頁(html)、互聯網上的音樂(mp3..)、視頻(avi..)、pdf電子書等。
全文檢索搜索的這些數據稱為非結構化數據。
6.1.1 結構化數據和非結構化數
結構化數據:指具有固定格式或有限長度的數據,如資料庫,元數據等。
非結構化數據:指不定長或無固定格式的數據,如郵件,word文檔等。
6.1.2 結構化數據搜索
由於結構化數據是固定格式,所以就可以針對固定格式的數據設計演算法來搜索,比如資料庫like查詢,like查詢採用順序掃描法,使用關鍵字匹配內容,對於內容量大的like查詢速度慢。
6.1.3 非結構化數據搜索
需要將所有要搜索的非結構化數據通過技術手段採集到一個固定的地方,將這些非結構化的數據想辦法組成結構化的數據,再以一定的演算法去搜索。
6.2 採集數據技術有哪些
對於互聯網上網頁採用http將網頁抓取到本地生成html文件。
數據在資料庫中就連接資料庫讀取表中的數據。
數據是文件系統中的某個文件,就通過文件系統讀取文件的內容。
6.2.1 網頁採集(瞭解)
因為目前搜索引擎主要搜索數據的來源是互聯網,搜索引擎使用一種爬蟲程式抓取網頁( 通過http抓取html網頁信息),以下是一些爬蟲項目:
Solr(http://lucene.apache.org/solr) ,solr是apache的一個子項目,支持從關係資料庫、xml文檔中提取原始數據。
Nutch(http://lucene.apache.org/nutch), Nutch是apache的一個子項目,包括大規模爬蟲工具,能夠抓取和分辨web網站數據。
jsoup(http://jsoup.org/ ),jsoup 是一款Java 的HTML解析器,可直接解析某個URL地址、HTML文本內容。它提供了一套非常省力的API,可通過DOM,CSS以及類似於jQuery的操作方法來取出和操作數據。
heritrix(http://sourceforge.net/projects/archive-crawler/files/),Heritrix 是一個由 java 開發的、開源的網路爬蟲,用戶可以使用它來從網上抓取想要的資源。其最出色之處在於它良好的可擴展性,方便用戶實現自己的抓取邏輯。
6.3 資料庫採集(掌握)
針對電商站內搜索功能,全文檢索的數據源在資料庫中,需要通過jdbc或者orm框架訪問資料庫中book表的內容。
6.4 索引文件邏輯結構
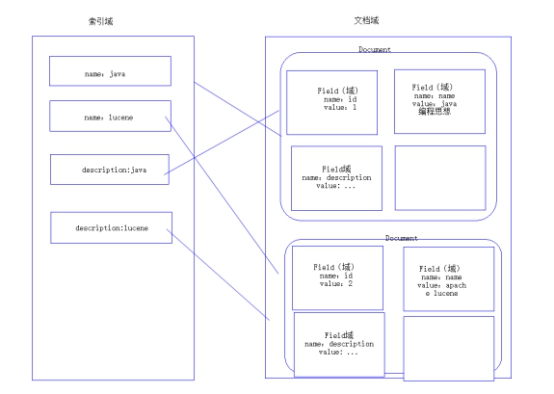
文檔域:對非結構化的數據統一格式為document文檔格式,一個文檔有多個field域,不同的文檔其field的個數可以不同,建議相同類型的文檔包括相同的field。本例子一個document對應一 條 book表的記錄。
索引域:用於搜索,搜索程式將從索引域中搜索一個一個詞,根據詞找到對應的文檔將Document中的Field的內容進行分詞,將分好的詞創建索引,索引=Field功能變數名稱:詞
倒排索引表
傳統方法是先找到文件,如何在文件中找內容,在文件內容中匹配搜索關鍵字,這種方法是順序掃描方法,數據量大就搜索慢。
倒排索引結構是根據內容(詞語)找文檔,倒排索引結構也叫反向索引結構,包括索引和文檔兩部分,索引即辭彙表,它是在索引中匹配搜索關鍵字,由於索引內容量有限並且採用固定優化演算法搜索速度很快,找到了索引中的辭彙,辭彙與文檔關聯,從而最終找到了文件
6.5 創建索引流程

分詞器Analyzer進行分詞 ,主要過程就是分詞、過濾兩步。
分詞就是將採集到的文檔內容切分成一個一個的詞,具體應該說是將Document中Field的value值切分成一個一個的詞。
This is a the book.
過濾包括去除標點符號、去除停用詞(的、是、a、an、the等)、大寫轉小寫、詞的形還原(複數形式轉成單數形參、過去式轉成現在式。。。)等。 (停用詞)
IndexWriter是索引過程的核心組件,通過IndexWriter可以創建新索引、更新索引、刪除索引操作。 IndexWriter需要通過Directory對索引進行存儲操作。
Directory描述了索引的存儲位置,底層封裝了I/O操作,負責對索引進行存儲。它是一個抽象類,它的子類常 用的包括FSDirectory(在文件系統存儲索引)、
RAMDirectory(在記憶體存儲索引)
6.6 lucene的使用
Lucene是開發全文檢索功能的工具包,使用時從官方網站下載,並解壓。
官方網站:http://lucene.apache.org/
下載地址:http://archive.apache.org/dist/lucene/java/
可以使用maven直接添加依賴,本教程使用這一種
7. 搜索流程
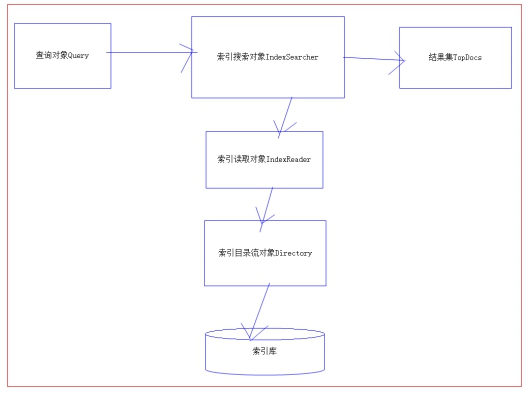
查詢對象Query:用戶定義查詢語句,用戶確定查詢什麼內容(輸入什麼關鍵字)
指定查詢語法,相當於sql語句。
IndexSearcher索引搜索對象,定義了很多搜索方法,程式員調用此方法搜索。
IndexReader索引讀取對象,它對應的索引維護對象IndexWriter,IndexSearcher
通過IndexReader讀取索引目錄中的索引文件
Directory索引流對象,IndexReader需要Directory讀取索引庫,使用
FSDirectory文件系統流對象
IndexSearcher搜索完成,返回一個TopDocs(匹配度高的前邊的一些記錄)
二、 Hello lucene
業務需求:使用Lucene實現電商項目中圖書類商品的索引和搜索功能。
1. 前期準備
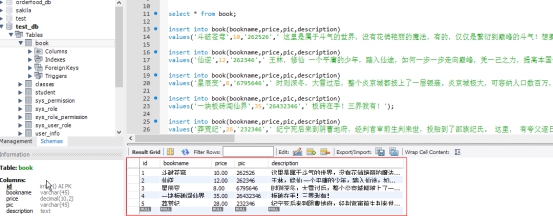
數據初始化準備:
book.sql
導入到資料庫中
操作資料庫準備(使用SpringBoot+MyBatis)
導入book.sql(過程省略,顯示效果)
2. 添加依賴
1 <dependency> 2 <groupId>org.mybatis.spring.boot</groupId> 3 <artifactId>mybatis-spring-boot-starter</artifactId> 4 <version>2.0.0</version> 5 </dependency> 6 7 <dependency> 8 <groupId>mysql</groupId> 9 <artifactId>mysql-connector-java</artifactId> 10 <version>5.1.37</version> 11 <scope>runtime</scope> 12 </dependency> 13 <dependency> 14 <groupId>org.springframework.boot</groupId> 15 <artifactId>spring-boot-starter-test</artifactId> 16 <scope>test</scope> 17 </dependency>
3. 編寫實體bin
public class Book { /** * 編號 */ private int id; /** * 書名 */ private String bookName; /** * 價格 */ private double price; /** * 圖片路徑 */ private String pic; /** * 描述 */ private String description; public int getId() { return id; } public void setId(int id) { this.id = id; } public String getBookName() { return bookName; } public void setBookName(String bookName) { this.bookName = bookName; } public double getPrice() { return price; } public void setPrice(double price) { this.price = price; } public String getPic() { return pic; } public void setPic(String pic) { this.pic = pic; } public String getDescription() { return description; } public void setDescription(String description) { this.description = description; } @Override public String toString() { return "Book{" + "id=" + id + ", bookName='" + bookName + '\'' + ", price=" + price + ", pic='" + pic + '\'' + ", description='" + description + '\'' + '}'; } }
4. MyBatis配置
mybatis.type-aliases-package=com.hx.springbootmybatis spring.datasource.driver-class-name=com.mysql.jdbc.Driver spring.datasource.url=jdbc:mysql://192.168.10.120:3306/test_db?useUnicode=true&characterEncoding=utf-8 spring.datasource.username=root spring.datasource.password=123456 #日誌配置 logging.path=D:/log logging.level.org.springframework.web=INFO logging.level.com.hx.springbootmybatis.domain=DEBUG
5. 編寫Mapper
@Mapper public interface BookMapper { /** * 查詢所有書籍信息 * @return */ @Select("select id,bookname,price,pic,description from book") public List<Book> getAllBook(); }
6. 測試Mybatis
@RunWith(SpringRunner.class) @SpringBootTest public class LuceneApplicationTests { @Autowired private BookMapper bookMapper; @Test public void test1() { List<Book> allBook = bookMapper.getAllBook(); System.out.println(allBook); } }
7. lucene配置
7.1 添加依賴
<!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-core --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> <version>7.5.0</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-queryparser --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-queryparser</artifactId> <version>7.5.0</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-analyzers-common --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-common</artifactId> <version>7.5.0</version> </dependency>
8. 創建索引
@Test public void test2() throws IOException { //1採集數據 List<Book> allBook = bookMapper.getAllBook(); //2創建索引 //Document集合對象 List<Document> documents = new ArrayList<Document>(); //將非結構化數據結構化,創建索引域和文檔域 Document doc; for (Book book : allBook) { doc = new Document(); Field id = new TextField("id", String.valueOf(book.getId()), Field.Store.YES); Field bookName = new TextField("name", book.getBookName().toString(), Field.Store.YES); Field price = new TextField("price", String.valueOf(book.getPrice()), Field.Store.YES); Field pic = new TextField("pic", book.getPic(), Field.Store.YES); Field description = new TextField("description", book.getDescription(), Field.Store.YES); doc.add(id); doc.add(bookName); doc.add(price); doc.add(pic); doc.add(description); documents.add(doc); } //構建分詞器 Analyzer analyzer=new StandardAnalyzer(); //構建存儲目錄和配置參數 Directory directory= FSDirectory.open(Paths.get("D:\\test\\lucene")); //構建存儲目錄和配置 IndexWriterConfig cfg=new IndexWriterConfig(analyzer); //構建IndexWriter索引寫對象並添加文檔對象 IndexWriter indexWriter=new IndexWriter(directory,cfg); for (Document document:documents){ indexWriter.addDocument(document); } //關閉indexWriter indexWriter.close(); }
9. 使用工具Luke查看索引
Luke作為Lucene工具包中的一個工具,可以通過界面來進行索引文件的查詢、修改。
下載網址:http://www.getopt.org/luke/
下載對應版本:https://github.com/DmitryKey/luke/releases
打開Luke方法:


