
1.概述 jupyter記事本是一個基於Web的前端,被分成單個的代碼塊或單元。根據需要,單元可以單獨運行,也可以一次全部運行。這使得我們可以運行某個場景,看到輸出結果,然後回到代碼,根據輸出結果對代碼做出相應的調整(說白了就是可以直接在瀏覽器中編寫Python程式,然後執行程式並輸出結果,是不是感 ...
1.概述
jupyter記事本是一個基於Web的前端,被分成單個的代碼塊或單元。根據需要,單元可以單獨運行,也可以一次全部運行。這使得我們可以運行某個場景,看到輸出結果,然後回到代碼,根據輸出結果對代碼做出相應的調整(說白了就是可以直接在瀏覽器中編寫Python程式,然後執行程式並輸出結果,是不是感覺很方便呀!)。jupyter記事本對於數據探索是非常理想的選擇。
2.安裝
前提條件:Python環境已搭建好和pip已安裝好(pip是 Python 包管理工具,該工具提供了對Python 包的查找、下載、安裝、卸載的功能)。
2.1 安裝IPython及IPython Notebook
1) pip install IPython
2) pip install urllib3 --安裝IPython Notebook的依賴
3) pip install jupyter --安裝IPython Notebook
2.2 安裝科學計算包
安裝這些計算包是為了做數據分析
1) pip install numpy
2) pip install matplotlib
3) pip install pandas
4) pip install scipy
5) pip install scikit-learn
6) pip install seaborn
3.啟動
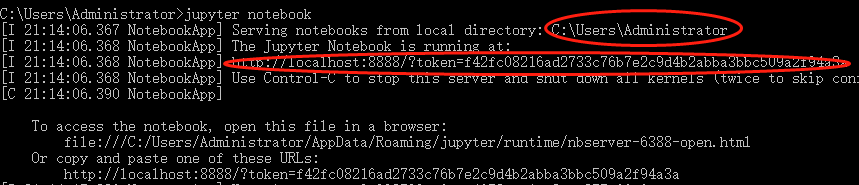
輸入啟動指令:jupyter notebook
我們可以在啟動信息中看到存放記事本文件的本地路徑還有Web應用地址
4.Demo
打開Web應用,然後我新建了一個名為PycharmProjects的文件夾
然後我在PycharmProjects的文件夾中新建了一個記事本,然後我們就可以通過記事本進行開發工作了。
這裡,我通過調用API介面的方式,獲取到樣例數據,並將該數據存放至本地文件,然後將文件中的數據輸出至電子錶格
import os import pandas as pd import requests import seaborn as sns PATH = 'C:/Users/Administrator/Desktop/' r = requests.get('https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data') with open(PATH + 'iris.data','w') as f: f.write(r.text) os.chdir(PATH) df = pd.read_csv(PATH + 'iris.data',names=['sepal length','sepal width','pepal length','pepal width','class']) df.head()

對數據做可視化操作
sns.pairplot(df,hue="class")



