
前言: 對於一個簡單的資料庫應用,由於對於資料庫的訪問不是很頻繁。這時可以簡單地在需要訪問資料庫時,就新創建一個連接,用完後就關閉它,這樣做也不會帶來什麼明顯的性能上的開銷。但是對於一個複雜的資料庫應用,情況就完全不同了。頻繁的建立、關閉連接,會極大的減低系統的性能,因為對於連接的使用成了系統性能的 ...
前言:
對於一個簡單的資料庫應用,由於對於資料庫的訪問不是很頻繁。這時可以簡單地在需要訪問資料庫時,就新創建一個連接,用完後就關閉它,這樣做也不會帶來什麼明顯的性能上的開銷。但是對於一個複雜的資料庫應用,情況就完全不同了。頻繁的建立、關閉連接,會極大的減低系統的性能,因為對於連接的使用成了系統性能的瓶頸。
連接復用。通過建立一個資料庫連接池以及一套連接使用管理策略,使得一個資料庫連接可以得到高效、安全的復用,避免了資料庫連接頻繁建立、關閉的開銷。
對於共用資源,有一個很著名的設計模式:資源池。該模式正是為瞭解決資源頻繁分配、釋放所造成的問題的。把該模式應用到資料庫連接管理領域,就是建立一個資料庫連接池,提供一套高效的連接分配、使用策略,最終目標是實現連接的高效、安全的復用。
資料庫連接池的基本原理是在內部對象池中維護一定數量的資料庫連接,並對外暴露資料庫連接獲取和返回方法。如:
外部使用者可通過getConnection 方法獲取連接,使用完畢後再通過releaseConnection 方法將連接返回,註意此時連接並沒有關閉,而是由連接池管理器回收,併為下一次使用做好準備。
資料庫連接池技術帶來的優勢:
1. 資源重用
由於資料庫連接得到重用,避免了頻繁創建、釋放連接引起的大量性能開銷。在減少系統消耗的基礎上,另一方面也增進了系統運行環境的平穩性(減少記憶體碎片以及資料庫臨時進程/線程的數量)。
2. 更快的系統響應速度
資料庫連接池在初始化過程中,往往已經創建了若幹資料庫連接置於池中備用。此時連接的初始化工作均已完成。對於業務請求處理而言,直接利用現有可用連接,避免了資料庫連接初始化和釋放過程的時間開銷,從而縮減了系統整體響應時間。
3. 新的資源分配手段
對於多應用共用同一資料庫的系統而言,可在應用層通過資料庫連接的配置,實現資料庫連接池技術,幾年錢也許還是個新鮮話題,對於目前的業務系統而言,如果設計中還沒有考慮到連接池的應用,那麼…….快在設計文檔中加上這部分的內容吧。某一應用最大可用資料庫連接數的限制,避免某一應用獨占所有資料庫資源。
4. 統一的連接管理,避免資料庫連接泄漏
在較為完備的資料庫連接池實現中,可根據預先的連接占用超時設定,強制收回被占用連接。從而避免了常規資料庫連接操作中可能出現的資源泄漏。一個最小化的資料庫連接池實現.
連接池類是對某一資料庫所有連接的“緩衝池”,主要實現以下功能:①從連接池獲取或創建可用連接;②使用完畢之後,把連接返還給連接池;③在系統關閉前,斷開所有連接並釋放連接占用的系統資源;④還能夠處理無效連接(原來登記為可用的連接,由於某種原因不再可用,如超時,通訊問題),並能夠限制連接池中的連接總數不低於某個預定值和不超過某個預定值。
DBCP連接池參數:
|
參數 |
預設值 |
說明 |
|
username |
root |
傳遞給JDBC驅動的用於建立連接的用戶名 |
|
password |
root |
傳遞給JDBC驅動的用於建立連接的密碼 |
|
url |
傳遞給JDBC驅動的用於建立連接的URL |
|
|
driverClassName |
com.mysql.jdbc.Driver |
使用的JDBC驅動的完整有效的Java 類名 |
|
initialSize |
0 |
初始化連接:連接池啟動時創建的初始化連接數量,1.2版本後支持 |
|
maxActive |
8 |
最大活動連接:連接池在同一時間能夠分配的最大活動連接的數量, 如果設置為非正數則表示不限制 |
|
maxIdle |
8 |
最大空閑連接:連接池中容許保持空閑狀態的最大連接數量,超過的空閑連接將被釋放,如果設置為負數表示不限制 |
|
minIdle |
0 |
最小空閑連接:連接池中容許保持空閑狀態的最小連接數量,低於這個數量將創建新的連接,如果設置為0則不創建 |
|
maxWait |
無限 |
最大等待時間:當沒有可用連接時,連接池等待連接被歸還的最大時間(以毫秒計數)超過時間則拋出異常,如果設置為-1表示無限等待 |
|
testOnReturn |
false |
是否在歸還到池中前進行檢驗 |
|
testWhileIdle |
false |
連接是否被空閑連接回收器(如果有)進行檢驗.如果檢測失敗,則連接將被從池中去除.設置為true後如果要生效,validationQuery參數必須設置為非空字元串 |
|
minEvictableIdleTimeMillis |
1000 * 60 * 30 |
連接在池中保持空閑而不被空閑連接回收器線程(如果有)回收的最小時間值,單位毫秒 |
|
numTestsPerEvictionRun |
3 |
在每次空閑連接回收器線程(如果有)運行時檢查的連接數量 |
|
timeBetweenEvictionRunsMillis |
-1 |
在空閑連接回收器線程運行期間休眠的時間值,以毫秒為單位.如果設置為非正數,則不運行空閑連接回收器線程 |
|
validationQuery |
null |
SQL查詢,用來驗證從連接池取出的連接,在將連接返回給調用者之前.如果指定,則查詢必須是一個SQL SELECT並且必須返回至少一行記錄 |
|
testOnBorrow |
true |
是否在從池中取出連接前進行檢驗,如果檢驗失敗,則從池中去除連接並嘗試取出另一個. |
dbcp所依賴的jar包:
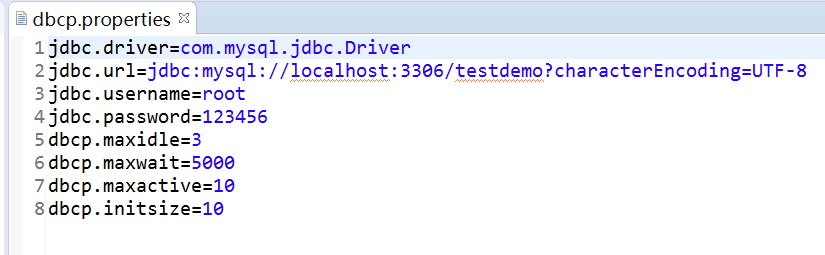
 對應的properties文件:
對應的properties文件:
 Druid配置參數:
Druid配置參數:
|
配置 |
預設值 |
說明 |
|
name |
|
配置這個屬性的意義在於,如果存在多個數據源,監控的時候可以通過名字來區分開來。 |
|
jdbcUrl |
|
連接資料庫的url,不同資料庫不一樣。例如: |
|
username |
|
連接資料庫的用戶名 |
|
password |
|
連接資料庫的密碼。如果你不希望密碼直接寫在配置文件中,可以使用ConfigFilter。詳細看這裡:https://github.com/alibaba/druid/wiki/%E4%BD%BF%E7%94%A8ConfigFilter |
|
driverClassName |
根據url自動識別 |
這一項可配可不配,如果不配置druid會根據url自動識別dbType,然後選擇相應的driverClassName(建議配置下) |
|
initialSize |
0 |
初始化時建立物理連接的個數。初始化發生在顯示調用init方法,或者第一次getConnection時 |
|
maxActive |
8 |
最大連接池數量 |
|
maxIdle |
8 |
已經不再使用,配置了也沒效果 |
|
minIdle |
|
最小連接池數量 |
|
maxWait |
|
獲取連接時最大等待時間,單位毫秒。配置了maxWait之後,預設啟用公平鎖,併發效率會有所下降,如果需要可以通過配置useUnfairLock屬性為true使用非公平鎖。 |
|
poolPreparedStatements |
false |
是否緩存preparedStatement,也就是PSCache。PSCache對支持游標的資料庫性能提升巨大,比如說oracle。在mysql下建議關閉。 |
|
maxOpenPreparedStatements |
-1 |
要啟用PSCache,必須配置大於0,當大於0時,poolPreparedStatements自動觸發修改為true。在Druid中,不會存在Oracle下PSCache占用記憶體過多的問題,可以把這個數值配置大一些,比如說100 |
|
validationQuery |
|
用來檢測連接是否有效的sql,要求是一個查詢語句。如果validationQuery為null,testOnBorrow、testOnReturn、testWhileIdle都不會其作用。 |
|
testOnBorrow |
true |
申請連接時執行validationQuery檢測連接是否有效,做了這個配置會降低性能。 |
|
testOnReturn |
false |
歸還連接時執行validationQuery檢測連接是否有效,做了這個配置會降低性能 |
|
testWhileIdle |
false |
建議配置為true,不影響性能,並且保證安全性。申請連接的時候檢測,如果空閑時間大於timeBetweenEvictionRunsMillis,執行validationQuery檢測連接是否有效。 |
|
timeBetweenEvictionRunsMillis |
|
有兩個含義: |
|
numTestsPerEvictionRun |
|
不再使用,一個DruidDataSource只支持一個EvictionRun |
|
minEvictableIdleTimeMillis |
|
|
|
connectionInitSqls |
|
物理連接初始化的時候執行的sql |
|
exceptionSorter |
根據dbType自動識別 |
當資料庫拋出一些不可恢復的異常時,拋棄連接 |
|
filters |
|
屬性類型是字元串,通過別名的方式配置擴展插件,常用的插件有: |
|
proxyFilters |
|
類型是List<com.alibaba.druid.filter.Filter>,如果同時配置了filters和proxyFilters,是組合關係,並非替換關係 |
所依賴的jar包:
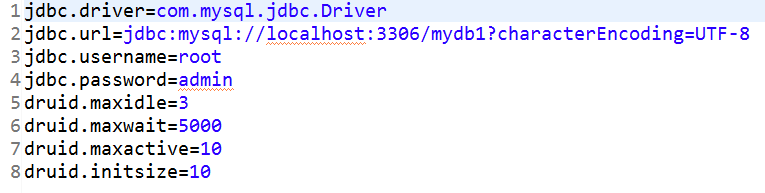
 對應的properties文件:
對應的properties文件:
 dbcp和druid代碼對比:
1.druid比dbcp少了一個最大空閑的參數
2.需註意properties文件里的5678行名字,對應改回來
dbcp和druid代碼對比:
1.druid比dbcp少了一個最大空閑的參數
2.需註意properties文件里的5678行名字,對應改回來
 相應代碼:
相應代碼:
public class JDBCUtil {
// 建立連接的驅動驅動名稱
public static String DRIVER_CLASS_NAME = "";
// 資料庫鏈接數據哭的url
public static String URL = "";
// 鏈接的資料庫賬號
public static String USERNAME = "";
// 鏈接的資料庫密碼
public static String PASSWORD = "";
// 醉的等待時間
private static long MAX_WAIT;
// 最大活動鏈接
private static int MAX_ACTIVE;
// 初始化時鏈接池的數量
private static int INITIAL_SIZE;
public static Properties properties = new Properties();
public static DruidDataSource druidDataSource = new DruidDataSource();
static {
InputStream ips = JDBCUtil.class.getClassLoader().getResourceAsStream("jdbc.properties");
try {
properties.load(ips);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
// 賦值操作
DRIVER_CLASS_NAME = properties.getProperty("jdbc.driver");
URL = properties.getProperty("jdbc.url");
USERNAME = properties.getProperty("jdbc.username");
PASSWORD = properties.getProperty("jdbc.password");
MAX_WAIT = Long.valueOf(properties.getProperty("druid.maxwait"));
MAX_ACTIVE = Integer.valueOf(properties.getProperty("druid.maxactive"));
INITIAL_SIZE = Integer.valueOf(properties.getProperty("druid.initsize"));
// 給連接池初始化參數
druidDataSource.setDriverClassName(DRIVER_CLASS_NAME);
druidDataSource.setUrl(URL);
druidDataSource.setUsername(USERNAME);
druidDataSource.setPassword(PASSWORD);
druidDataSource.setInitialSize(INITIAL_SIZE);
druidDataSource.setMaxActive(MAX_ACTIVE);
druidDataSource.setMaxWait(MAX_WAIT);
}
public static DruidDataSource getDataSources() {
return druidDataSource;
}
public static Connection getConnection() {
try {
return basicDataSource.getConnection();
} catch (SQLException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return null;
}
//測試連接
public static void main(String[] args) {
System.out.println(properties);
}
//測試連接是否成功的main方法
public static void main(String[] args) throws Exception {
Connection connection=druidDataSource.getConnection();
String sql="select * from t_user";
PreparedStatement statement=connection.prepareStatement(sql);
ResultSet rs=statement.executeQuery();
while(rs.next()) {
System.out.println(rs.getString("username"));
}
}
}


