
針對在項目中碰到的一些容錯設計問題,團隊最近進行了一次技術沙龍,討論了以下話題。為什麼需要應用層的容錯設計?一個完整的系統在內部是由很多小服務構成,服務之間以及服務與資源之間會存在遠程調用。每個系統的可用性不可能達到100%各種網路及硬體問題,如網路擁堵、網路中斷、硬體故障……遠程服務平均響應速度變...
針對在項目中碰到的一些容錯設計問題,團隊最近進行了一次技術沙龍,討論了以下話題。
為什麼需要應用層的容錯設計?
一個完整的系統在內部是由很多小服務構成,服務之間以及服務與資源之間會存在遠程調用。
-
每個系統的可用性不可能達到100%
-
各種網路及硬體問題,如網路擁堵、網路中斷、硬體故障……
-
遠程服務平均響應速度變慢
伺服器平均響應速度如果慢下來,慢慢消耗掉系統所有資源,進而導致整個系統不可用。因此在分散式系統中,除了遠程服務本身需要有容錯設計之外,在應用層的遠程調用的環節,需要有良好的容錯設計。
應用層的容錯設計有哪些方法?以下是微博團隊使用過的一些實踐。
訪問MySQL的容錯設計
-
寫操作:如果master異常,直接拋異常。
-
讀操作:如果slave有多個,先選擇其中一個slave,如果獲取連接失敗,再選擇其他的slave,如果全部不可用,最後選擇master。
訪問Memcached/Redis的容錯設計
首先設置so_timeout,避免無限制等待;伺服器連接如果IO異常,設置錯誤標誌,一段時間停止訪問;出錯後定期主動(比如ping Redis)或被動(當被再次訪問時)探測服務是否恢復。
Failover機制:
如果連接某個node失敗, 當前pool啟用一致性hash切換到backup node;如果backup node沒有數據,則通過另外一個服務池(數據副本)獲取數據。
訪問遠程HTTP API的容錯設計
設置so_timeout;部分場景:短超時,重試一次;另外由於HTTP service情況的多樣性,業務層面還有通用的降級機制。
訪問不同資源使用不同方法存在的問題
從上面列舉的部分場景來看,在訪問不同資源時候,每種client訪問都有一些相通的原理,但卻要使用不同的重覆實現。由於各個client獨立實現,實現時候由於各個遠程服務協議及行為的差異,導致這些容錯原理無法直接復用。另外在代碼層面,不同的client也使用了不同年代的一些底層庫,一些早期client的實現,數據層,連接層,協議層全部耦合在一起,也造成維護成本進一步加大。
比如之前一些服務開發中碰到的類似如下的問題:
-
hbase-client由於沒有實現容錯設計,導致訪問出現了抖動,影響了同一服務池的其他調用,需要增加類似MySQL client的容錯及快速失敗策略;
-
MySQL slave流量出現不均衡了,由於多個slave IP之間沒有使用公用的負載均衡策略,因此需要重新添加、上線及驗證。
另外目前分散式系統中大部分遠程資源都是IO bound而不是CPU bound,而client大部分又是同步調用,造成大部分調用都在等待遠程返回,同時也消耗了工作線程資源,以及大量線程context switch。
有沒有可能統一的client?
這些策略原理上是可以公用的,能否出一個統一的client層來一勞永逸?不過這個需求不是twitter乾過嗎?
Finagle,不僅是平時理解的RPC框架,還有目標是想成為一個commons client,從另外一個層面,廣義上訪問遠程資源也都可以理解成RPC,所以Finagle也常稱為RPC框架。
Finagle implements uniform client and server APIs for several protocols, and is designed for high performance and concurrency.
在Twitter體系,分散式服務可以從future, service, filter三個層次理解,容錯、超時、授權、tracing、重試等機制都是體現在filter中;而future則將client從多線程、隊列、連接池、資源管理釋放出來,從關註控制流到關註數據流。並且預設變成非同步方式。
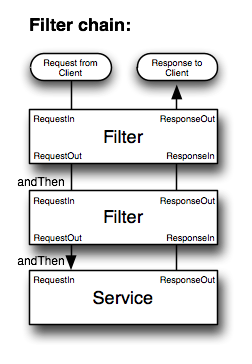
Finagle的FailFast模塊會避免分發請求到出現問題的服務,它通過來記錄到每個host的錯誤來進行標記,當出錯以後,Finagle會通過一個後臺線程定期重連以檢查是否恢復。當host宕機時,相關的service會標記成不可用。
如果來redisign一個通用的網路client,它應該包括哪些元素?
-
具有服務的分層設計,借鑒Future/Service/Filter概念
-
具有網路的分層設計,區分協議層、數據層、傳輸層、連接層
-
獨立的可適配的codec層,可以靈活增加HTTP,Memcache,Redis,MySQL/JDBC,Thrift等協議的支持。
-
將多年各種遠程調用High availability的經驗融入在實現中,如負載均衡,failover,多副本策略,開關降級等。
-
通用的遠程調用實現,採用async方式來減少業務服務的開銷,並通過future分離遠程調用與數據流程的關註。
-
具有狀態查看及統計功能
-
當然,最終要的是,具備以下通用的遠程容錯處理能力,超時、重試、負載均衡、failover……


