
inode簡單理解 本文來源自網路文章,並針對文章內容加以批註和修改。希望能幫到你! 一. 磁碟設備 說到inode,首先必須要提及下《操作系統》中磁碟存儲器的管理一節。磁碟設備是一種相當複雜的機電設備(比較詳細的介紹可以參考blog硬碟內部硬體結構和工作原理詳解 )。 磁碟設備可以包括一個或多個物 ...
inode簡單理解
本文來源自網路文章,並針對文章內容加以批註和修改。希望能幫到你!
一. 磁碟設備
說到inode,首先必須要提及下《操作系統》中磁碟存儲器的管理一節。磁碟設備是一種相當複雜的機電設備(比較詳細的介紹可以參考blog硬碟內部硬體結構和工作原理詳解 )。 磁碟設備可以包括一個或多個物理碟片,每個磁碟片分一個或兩個存儲面(如圖(a)所示)。每個磁碟面被組織成若幹個同心環,這種環稱為磁軌track,各磁軌之間留有必要的間隙。每條磁軌又被邏輯上劃分成若幹個扇區sectors(批註:stat 命令中的Blocks項)。在不同扇區之間又保留必要的間隔, 圖(b)中顯示了顯示了一個有3個磁軌,每個磁軌又被分成 8 個扇區的磁碟片的一個存儲面。
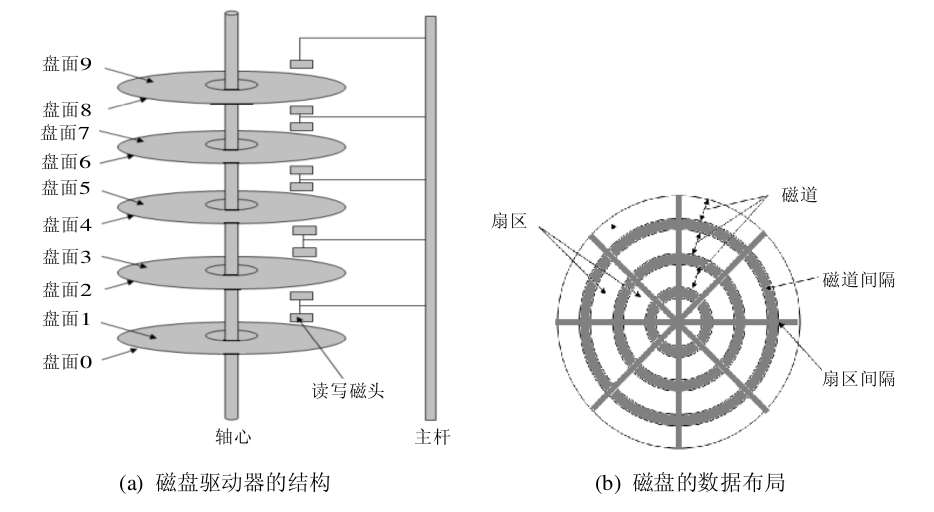
在操作系統中,信息一般以扇區(sectors)的形式存儲在硬碟上,而每個扇區包括512個位元組的數據和一些其他信息(即一個扇區包括兩個主要部分:存儲數據地點的標識符和存儲數據的數據段)。操作系統讀取硬碟的時候,不會一個個扇區地讀取,這樣效率太低,而是一次性連續讀取多個扇區,即一次性讀取一個塊(blocks)(批註:stat 命令中 IO Block 項)。這種由多個扇區組成的”塊”,是文件存取的最小單位。”塊”的大小,最常見的是4KB,即連續八個 sectors組成一個 blocks。(批註:這裡的塊是linux 系統一次讀取的粒度,linux 中一次讀取8個扇區)
二. inode的內容
既然文件數據都儲存在”塊”中,那麼對於操作系統而言,必須採用一種方式來找到這個存儲文件數據的“塊”,為此操作系統便引入了一個非常重要的概念”inode”,中文名為“索引結點” 。既然引進inode的目的是為了找到“塊”,那麼inode中必然包括像文件數據block位置這麼重要的信息,當然也不僅僅包括這麼一個信息,還包括比如文件的創建者、文件的創建日期、文件的大小等等。具體可以輸入stat指令查看某個文件的inode信息,這裡以example.txt為例。
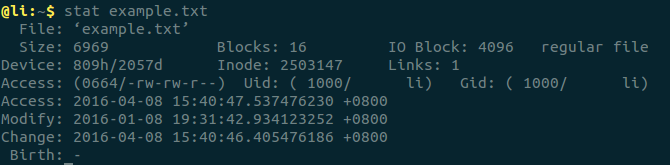
這裡便可以看到inode信息主要包括:
- 文件的位元組數,塊數
- 文件擁有者的User ID
- 文件的Group ID
- 文件的讀、寫、執行許可權
- 文件的時間戳,共有三個:ctime指inode上一次變動的時間,mtime指文件內容上一次變動的時間,atime指文件上一次打開的時間。
- 鏈接數,即有多少文件名指向這個inode
- 文件數據block的位置
- inode編號
Stat 命令補充:
我們重新創建一個ex.txt 文件,並輸入一些字元。
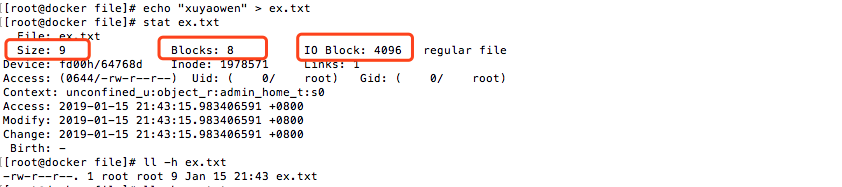
這就會產生一些疑問?(下麵是阮一峰博客下麵的一個問題)

所以這裡解答一下:通常的 Linux 塊大小為 512 位元組,一次讀取通常讀取的塊數為8個塊(扇區),所以 這裡 IO-Blocks為 4096(4k),表示一次讀取8個扇區,這樣可以提高效率。這裡的512就是磁碟上一個扇區的大小。
查看扇區大小:

測試:如果我們輸入4096個字元,應該還是8個塊,如果輸入4097個字元,那麼應該是16快。結果如下所示:
我們使用如下代碼生成4096大小的文件:
#!/bin/sh for i in {1..2048} do echo 'o' >> ex.txt done
結果:
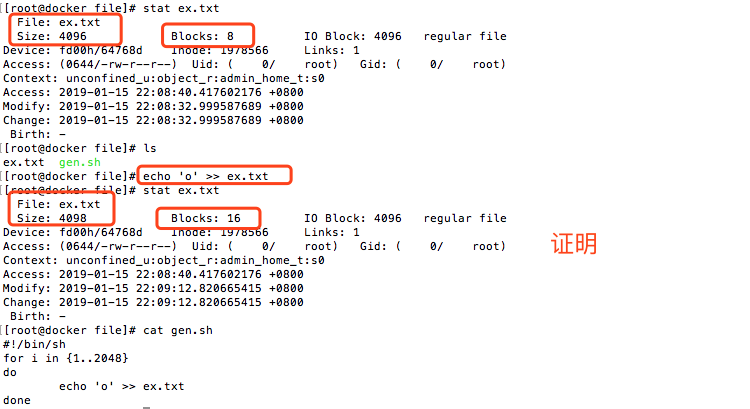
證明!
三. inode的大小
前面已經提到inode中包括關於某個文件的索引信息,那麼其中必然會存儲部分數據,在電腦中必然會占據一定的空間,所以硬碟格式化的時候,操作系統自動將硬碟分成兩個區域。一個是數據區,存放文件數據;另一個是inode區(inode table),存放inode所包含的信息。
每個inode節點的大小,一般是128位元組或256位元組。inode節點的總數,在格式化時就給定,一般是每1KB或每2KB就設置一個inode。
假定在一塊1GB的硬碟中,每個inode節點的大小為128位元組,每1KB就設置一個inode,那麼inode table的大小就會達到128MB,占整塊硬碟的12.8%。
查看每個硬碟分區的inode總數和已經使用的數量,可以使用df命令查看。
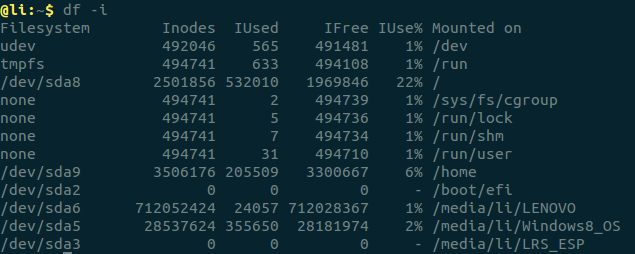
查看每個inode節點的大小,可以用如下命令:
sudo dumpe2fs -h /dev/sda9 | grep “Inode size”

由於每個文件都必須有一個inode,因此有可能會發生磁碟空間未滿而inode已經用完導致不能存入文件的情況。
四. inode編號
在Unix/Linux操作系統中,系統內部並不採用文件名查找文件,而是使用inode編號來識別文件。因此對於系統來說,文件名只是inode號碼便於識別的別稱或者綽號。而站在用戶角度,用戶通過文件名,打開文件,實際上,系統內部是獲取inode信息找到數據塊的,這個過程分成三步:
- 首先,系統找到這個文件名對應的inode號碼;
- 其次,通過inode號碼,獲取inode信息;
- 最後,根據inode信息,找到文件數據所在的block,讀出數據。
註:可以使用df -i或者ls -i均可以查看到文件名對應的inode號碼。

五. 目錄文件
Unix/Linux系統中,目錄(directory)也是一種文件。打開目錄,實際上就是打開目錄文件。
目錄文件的結構非常簡單,就是一系列目錄項(dirent)的列表。每個目錄項,由兩部分組成:所包含文件的文件名,以及該文件名對應的inode號碼。
對於目錄文件而言,其讀許可權(r)和寫許可權(w)並不難理解,都是針對目錄文件本身。由於目錄文件內只有文件名和inode號碼,所以如果只有讀許可權,只能獲取文件名,無法獲取其他信息,這主要是因為其他信息都儲存在inode節點中,而讀取inode節點內的信息需要目錄文件的執行許可權(x)。
六. 硬鏈接
一般情況下,文件名和inode號碼是”一一對應”關係,每個inode號碼對應一個文件名。但是Unix/Linux系統允許,多個文件名指向同一個inode號碼。這意味著,可以用不同的文件名訪問同樣的內容;對文件內容進行修改,會影響到所有文件名;但是,刪除一個文件名,不影響另一個文件名的訪問。這種情況就被稱為”硬鏈接”(hard link)。可以使用ln指令添加硬鏈接。
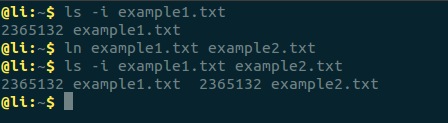
運行上面這條命令以後,源文件與目標文件的inode號碼相同,都指向同一個inode。inode信息中有一項叫做”鏈接數”,記錄指向該inode的文件名總數,這時就會增加1。反過來,刪除一個文件名,就會使得inode節點中的”鏈接數”減1。當這個值減到0,表明沒有文件名指向這個inode,系統就會回收這個inode號碼,以及其所對應block區域。
這裡順便說一下目錄文件的”鏈接數”。創建目錄時,預設會生成兩個目錄項:”.”和”..”。前者的inode號碼就是當前目錄的inode號碼,等同於當前目錄的”硬鏈接”;後者的inode號碼就是當前目錄的父目錄的inode號碼,等同於父目錄的”硬鏈接”。所以,任何一個目錄的”硬鏈接”總數,總是等於2加上它的子目錄總數(含隱藏目錄)。
七.軟鏈接
除了硬鏈接以外,還有一種特殊情況。
文件A和文件B的inode號碼雖然不一樣,但是文件A的內容是文件B的路徑。讀取文件A時,系統會自動將訪問者導向文件B。因此,無論打開哪一個文件,最終讀取的都是文件B。這時,文件A就稱為文件B的”軟鏈接”(soft link)或者”符號鏈接(symbolic link)。
這意味著,文件A依賴於文件B而存在,如果刪除了文件B,打開文件A就會報錯:”No such file or directory”。這是軟鏈接與硬鏈接最大的不同:文件A指向文件B的文件名,而不是文件B的inode號碼,文件B的inode”鏈接數”不會因此發生變化。ln -s命令可以創建軟鏈接。
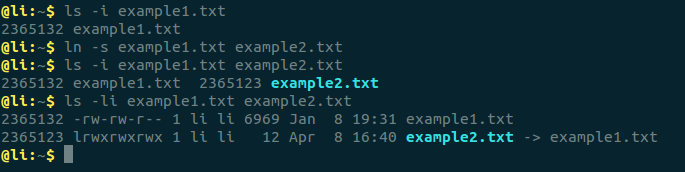
八、inode的特殊作用
由於inode號碼與文件名分離,這種機制導致了一些Unix/Linux系統特有的現象。
- 有時,文件名包含特殊字元,無法正常刪除。這時,直接刪除inode節點,就能起到刪除文件的作用。
- 移動文件或重命名文件,只是改變文件名,不影響inode號碼。
- 打開一個文件以後,系統就以inode號碼來識別這個文件,不再考慮文件名。因此,通常來說,系統無法從inode號碼得知文件名。
最後一點使得軟體更新變得簡單,可以在不關閉軟體的情況下進行更新,不需要重啟。因為系統通過inode號碼,識別運行中的文件,不通過文件名。更新的時候,新版文件以同樣的文件名,生成一個新的inode,不會影響到運行中的文件。等到下一次運行這個軟體的時候,文件名就自動指向新版文件,舊版文件的inode則被回收。
參考鏈接:
1. 硬碟內部硬體結構和工作原理詳解
2. 理解inode
3. https://blog.csdn.net/u013595419/article/details/51094360/
保持更新,轉載請註明出處。https://www.cnblogs.com/xuyaowen/p/inode-linux.html


