
讓應用程式在運行時適應客戶需求最常用的方法之一就是使用腳本。但是事物總有兩面性,無一例外。腳本這種方法並非只有好的一面,我們需要在靈活性和可管理性之間權衡。本文不是在理論上討論優缺點的文章,而是從實際出發,展示使用腳本的幾種不同方式,並介紹了一個Spring庫,這個庫提供了方便的腳本基礎設施和一些其... ...
原文:In any incomprehensible situation go scripting
翻譯:CUBA China
CUBA-Platform:https://cuba-platform.com
CUBA-China:http://cuba-platform.cn
讓應用程式在運行時適應客戶需求最常用的方法之一就是使用腳本。但是事物總有兩面性,無一例外。腳本這種方法並非只有好的一面,我們需要在靈活性和可管理性之間權衡。本文不是在理論上討論優缺點的文章,而是從實際出發,展示使用腳本的幾種不同方式,並介紹了一個Spring庫,這個庫提供了方便的腳本基礎設施和一些其他的有用功能。
介紹
腳本(也稱為插件架構)是使應用程式在運行時可自定義的最直接的方法。很多時候,腳本並不是設計到應用程式中的,只是偶爾會用到。比如說,在功能描述中有一部分描述地非常模糊,我們不能再耗費額外一天時間去分析這個描述模糊的業務。這時我們決定創建一個擴展點並調用一個腳本存根,然後在晚些時候再詳細定義這個腳本的業務邏輯。
使用這種方法有很多眾所周知的優點和缺點:例如可以非常靈活地在運行時定義業務邏輯並且可以在重新部署方面節省大量時間,但是使用腳本也會導致不能對系統進行全面地測試,因此,會給系統在安全性、性能等方面帶來不可預測的問題。
後續對使用腳本的方式的討論可能對已經決定在Java應用程式中堅持使用腳本插件的用戶或正在考慮將其添加到代碼中的用戶都會有所幫助。
直接編寫腳本
使用Java JSR-233 API在Java中執行腳本是很簡單的任務。有許多實現了此API的產品級腳本執行引擎,比如Nashorn、JRuby、Jython等。因此在java添加一些腳本的魔法很容易實現,如下所示:

顯然,如果你的代碼庫中的腳本文件很多,那麼將這些調用代碼分散在整個應用程式並不好。因此,你可能會將此代碼段提取到一個工具類的單獨方法中。也可能會考慮地更遠一些:創建一個專用的類(或一組類),根據業務領域對腳本化業務邏輯進行分組,比如:PricingScriptService類。這樣我們就可以將對evaluateGroovy() 方法的調用封裝到一個強類型的方法中,但這裡仍然存在一些重覆的代碼:所有方法都包含構建參數Map、載入腳本文本以及調用腳本引擎的代碼,類似於:

這種方法在瞭解參數類型和返回值類型方面有更大的透明度。但是別忘了,需要在編碼標準文檔中添加一條:禁止調用“解包”了的腳本引擎!
CUBA平臺中增強版的腳本引擎
儘管使用腳本引擎非常簡單,但如果代碼庫中有很多腳本,就可能會遇到一些性能問題。比如,在報表中使用groovy模板,並且同時運行大量報表。那麼,你遲早會發現“簡單”腳本成為性能瓶頸。
這就是為什麼有些框架在現有API上構建自己的腳本引擎 :添加一些功能來改善性能、監控腳本的執行、支持多種腳本語言,等等。
例如,在CUBA框架中,有一個相當複雜的Scripting引擎,提供一些用於改善腳本實現和執行的功能,例如:
- 對類進行緩存, 避免腳本的重覆編譯。
- 使開發人員能夠使用Groovy和Java語言編寫腳本。
- 提供用於腳本引擎管理的JMX bean。
所有這些都改善了性能和可用性,但這些還只是用於創建參數Map、獲取腳本文本等低級API,因此我們仍然需要將這些腳本分組到高階模塊,以便在應用程式中更高效地使用腳本。
在這裡,有必要提一下GraalVM引擎,這是一個由Oracle開源實驗性產品。GraalVM引擎及其多語言API允許開發人員使用其他語言擴展Java應用程式。所以,我們也許能看到Nashorn退役之時,我們也可以在同一個源文件中使用不同的編程語言。但是,這些還需要等待。
Spring 框架對腳本的支持
Spring框架在JDK API之上內置了對腳本的支持,可以在org.springframework.scripting.* 包中找到很多有用的類。有執行器(evaluators)、工廠(factories)等所有用於構建腳本支持所需的工具。
除了低級別API之外,Spring 框架還有一個可以在應用程式中簡化腳本處理的實現 - 可以使用動態語言定義Bean,文檔鏈接。
需要做的就是使用像Groovy這樣的動態語言實現一個類,併在配置XML中描述一個bean,如下所示:

之後,就可以使用XML配置將Messenger bean註入到應用程式的類中。由於AOP的幫助,在Bean對應的腳本文件發生變化時,這個Bean可以自動“刷新”。
這種方法看起來不錯,但是作為開發人員,如果想充分發揮動態語言的威力,應該為bean實現完整的類。在現實中,腳本可能是純函數,因此需要在腳本中添加一些額外的代碼使其與Spring相容。此外,現在一些開發人員認為XML配置與註解相比,已經“過時”,並且儘量避免使用它,因為會覺得bean的定義和註入分散在Java代碼和XML代碼中。雖然這更像是審美問題而不是性能/相容性/可讀性等問題,但我們也許會把它考慮在內。
腳本:挑戰和想法
任何事情都有代價,當為應用程式添加腳本支持功能時,可能會遇到一些挑戰:
- 可管理性 - 通常腳本分散在應用程式中,因此管理大量的evaluateGroovy(或類似的)調用會很困難。
- 可發現性 - 如果在調用的腳本中出現問題,很難在源代碼中找到實際的出錯點。但是在IDE中能很輕鬆地找到所有腳本調用點。
- 透明度 - 編寫腳本擴展並非是一件簡單的事情,因為沒有關於要傳遞給腳本的變數的信息,也沒有關於腳本返回的結果的信息。最終,腳本只能由開發人員通過查看源代碼完成。
- 更新 - 部署(更新)新腳本總是存在危險性,在用於生產環境之後很難進行回滾。
將對腳本方法的調用隱藏在常規Java方法下似乎可以解決大部分這種問題。更好的方法是註入“腳本化”bean並使用有意義的名稱調用其方法,而不是從通用類中調用另一個“eval”方法。這樣,我們的代碼將可以自描述,開發人員不需要查看文件“disc_10_cl.groovy”來確定參數名稱、類型等。
另一個優點 - 如果所有腳本都有與之關聯的唯一java方法,則可以使用IDE中的“Find Usages(查找用例)”功能輕鬆找到應用程式中的所有擴展點,同時也可以知道此腳本的參數和返回值是什麼。
這種編寫腳本的方式也使得測試變得更簡單 - 我們不僅可以“像往常一樣”測試這些類,而且如果需要也可以使用Mocking框架。
所有這些都再次提及本文開頭提到的方法 - 用於腳本化方法的“特殊”類。如果我們更進一步對開發人員隱藏對腳本引擎的調用、參數創建等操作用會怎麼樣?
腳本倉庫概念
這個想法很簡單,所有使用過Spring框架的開發人員都應該很熟悉。我們只是創建一個java介面,並以某種方式將其方法鏈接到腳本。舉例來說,Spring Data JPA使用的就是類似的方法,其中介面方法基於其名稱轉換為SQL查詢,然後由ORM引擎執行。
實現這個概念可能需要什麼?
可能需要一個類級別的註解來幫助我們檢測腳本倉庫介面併為它們構造一個特殊的Spring bean。
還有一個方法級別的註解,可以幫助我們將方法鏈接到具體的腳本實現。
如果給介面方法提供一個預設實現,這個實現不是簡單的存根,而是一部分有效的業務邏輯,這樣會更好。這樣的話,在業務分析人員實現演算法之前可以一直使用這個預設實現。或者我們可以讓他/她(業務專家)自己來編寫這個腳本 :-)。
假設需要創建根據用戶的個人資料計算折扣的服務。業務分析師表示,我們可以安全地假設預設情況下可以為所有註冊客戶提供10%的折扣。對於這種情況,我們可能會考慮以下概念代碼:
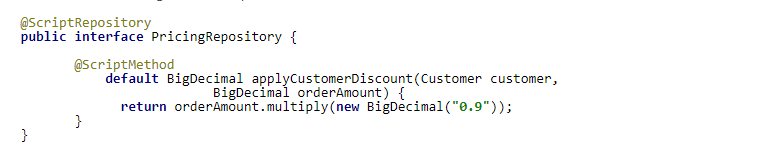
當有了合適的折扣演算法實現時,groovy腳本可以這樣寫:

這一切的最終目標是讓開發人員只實現一個介面和折扣演算法腳本,並且不需要笨拙地調用那些 “getEngine” 和 “eval”方法。腳本解決方案應處理所有的邏輯:當方法被調用時攔截調用,查找並載入腳本文本,執行它並返回結果(如果沒找到腳本文本,則執行預設方法)。理想的用法大概如下:
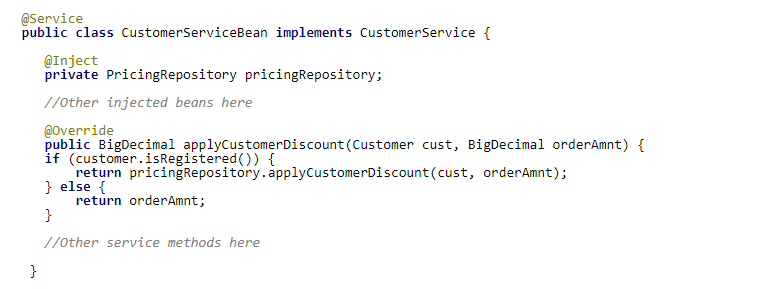
我想這種腳本調用具有可讀性,並且這種調用方式對java開發人員來說不會陌生。
這些是想法,並且用這些想法來基於 Spring Framework 創建腳本倉庫的實現庫。這個庫包含從不同來源載入並執行腳本的基礎設施,同時也提供了一些API, 開發人員可以使用這些API對這個庫進行擴展。
它如何工作
這個庫創建了一些註解(以及XML配置,有的開發人員可能偏好於使用XML配置),在上下文初始化期間,為使用@ScriptRepository註解的所有Repository介面初始化動態代理。這些代理髮布為實現Repository介面的單例bean,這意味著可以使用@Autowired或@Inject將這些代理註入到bean中,如上一節中的代碼片段所示。
在其中一個應用程式的配置類上使用@EnableScriptRepositories註解來激活腳本Repositories。這種方法類似於開發人員熟知的其它Spring 註解(如 @EnableJpaRepositories 或 @EnableMongoRepositories)。對於此註解,需要指定應與 JPA repository相似的掃描包名數組。

如前面所示,我們需要使用 @ScriptMethod 註解來標記腳本Repository中的每個方法(庫也提供 @GroovyScript 和 @JavaScript),為方法調用添加元數據並註明這些方法是腳本方法。當然,也支持腳本方法的預設實現。這個解決方案的所有組件都顯示在下圖中。藍色圖形與應用程式代碼相關,白色圖形與庫相關。Spring bean 有 Spring Logo 。
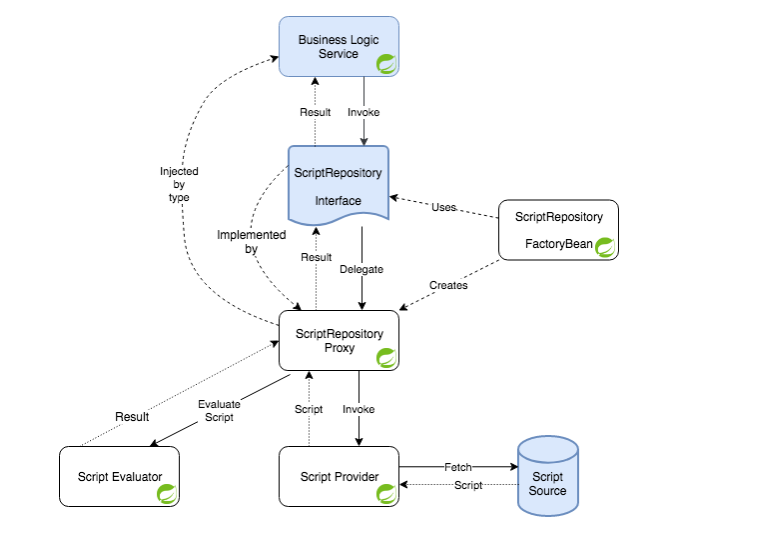
當調用介面的腳本方法時,它會被代理類攔截,代理類會查找兩個 bean - 一個是用於獲取實現腳本內容的provider,另一個是用於獲取執行結果的evaluator。在腳本執行之後,結果將返回給腳本的調用方。可以用 @ScriptMethod 註解屬性指定provider和evaluator以及執行超時(這個庫也為這些屬性提供了預設值):

你可能會註意到 @ScriptParam 註解 - 我們使用它們為方法的參數提供名稱,這些名稱應該用在腳本中,因為 Java 編譯器會在編譯時刪除實際的參數名稱。也可以不用這個註解,此時,需要以 “arg0”、“arg1” 等來命名腳本參數,只是這會影響代碼的可讀性。
預設情況下,這個庫提供可以從文件系統讀取 groovy 和 javascript 文件的provider以及用於兩種腳本語言的基於JSR-233 的 evaluator。可以為不同的腳本存儲和執行引擎創建自定義的provider和evaluator。所有這些設施都基於 Spring 框架介面(org.springframework.scripting.ScriptSource 和 org.springframework.scripting.ScriptEvaluator),因此可以復用所有基於 Spring 的類。例如,使用StandardScriptEvaluator代替預設的類。
Provider(以及evaluator)會作為 Spring bean 發佈,為了提高靈活性,腳本repository代理會按名稱解析 - 可以在不更改應用程式代碼的情況下將預設執行程式替換為另外一個,只是在應用程式上下文中替換一個 bean。
測試和版本控制
由於腳本很容易更改,因此我們需要確保在改變腳本時不會破壞生產伺服器。這個庫與 JUnit 測試框架相容,這裡沒有特殊之處。由於在基於 Spring 的應用程式中使用這個庫,因此在將腳本更新到生產環境之前,可以使用單元測試和集成測試將腳本作為應用程式的一部分來測試,測試中也支持模擬(mocking)框架。
此外,可以創建一個腳本provider,從資料庫甚至從 Git 或其它源代碼控制系統讀取不同版本的腳本文本。在這種情況下,如果生產環境中出現問題,可以很容易切換到新版本的腳本或回滾到之前版本的腳本。
結論
這個庫有助於在代碼中使用腳本,提供以下功能:
- 通過引入 java 介面,開發人員可以獲取到腳本參數及其類型信息。
- Provider和evaluator可以避免分散在飲用程式各處的腳本引擎調用。
- 我們可以使用 “Find usages (references)” IDE 命令或只通過方法名稱進行簡單的文本搜索就能輕鬆找到應用程式代碼中的所有腳本使用的地方。
另外,這個庫也支持Spring Boot自動配置,並且還可以使用熟悉的單元測試和模擬(mocking )技術在腳本部署到生產環境之前對其進行測試。
這個庫有一個用於在運行時獲取腳本元數據(方法名稱、參數等)的 API,也可以獲取封裝後的執行結果,如果不想編寫 try..catch 塊來處理腳本拋出的異常的話,另外,如果更習慣用XML格式來存儲配置的話,這個庫也支持。
此外,可以使用註解的超時時限參數對腳本執行時間進行限制。
這個庫的源碼:https://github.com/cuba-rnd/spring-script-repositories



