
從昨天下午接到新任務,要採集一個法院網站得所有公告,大概是需要採集這個網站得所有公告列表裡得所有txt內容,txt文件裡邊是一件件赤裸裸得案件,記錄這案由,原告被告等相關屬性(不知道該叫什麼就稱之為屬性吧,汗),把這些文件放到本地某個目錄,並把一個案件作為一條數據放入資料庫中。本以為很輕鬆得用Jso ...
從昨天下午接到新任務,要採集一個法院網站得所有公告,大概是需要採集這個網站得所有公告列表裡得所有txt內容,txt文件裡邊是一件件赤裸裸得案件,記錄這案由,原告被告等相關屬性(不知道該叫什麼就稱之為屬性吧,汗),把這些文件放到本地某個目錄,並把一個案件作為一條數據放入資料庫中。本以為很輕鬆得用Jsoup就可以完成,但是我還是低估了政府部門填寫數據得人得不規範性,你妹啊,一會英文冒號,一會中文冒號,一會當事人,一會原告人得。。。。。。氣死我了,昨天晚回家了一個鐘頭,今天又忙活到下午3點才算採集完畢,總算所有得數據和txt文件都完整無誤得採集完畢了,然後聽負責人說要開始用kafk+strom搭個什麼東西,讓我可以先學學這方面東西,到時候可以一塊參與進來,我一聽可以學新得技術,那是兩眼冒光啊,可算不用天天頂著javaweb後天開發那點事兒了(雖然也不是很精通),下午就開始著手先學習kafka,好了廢話就到這了,下麵事正文。
研究大約半天得kafka,總得來說還是一頭霧水啊!!。不過對kafka得一些基礎知識已經基本掌握,也寫好了一個java測試程式,還是有點成就感得吧。我覺得學習一個新技術,必須先從基礎看,必須先從基礎看,必須先從基礎看,重要得話說三遍!從網上找了很多關於基礎得說明,我覺得有一篇寫的還算清楚,我複製過來供大家學習。嘿嘿,你們一定要一行不喇得看,讀不懂得地方一直讀,實在讀不懂寫個程式之後再來體會,你會發現豁然開朗,哈哈哈。下邊是基礎,明天抽時間把windows下得kafk和zookeeper安裝和部署更新上來,還有測試代碼。
1、簡介 Kafka is a distributed,partitioned,replicated commit logservice。它提供了類似於JMS的特性,但是在設計實現上完全不同,此外它並不是JMS規範的實現。kafka對消息保存時根據Topic進行歸類,發送消息者成為Producer,消息接受者成為Consumer,此外kafka集群有多個kafka實例組成,每個實例(server)成為broker。無論是kafka集群,還是producer和consumer都依賴於zookeeper來保證系統可用性集群保存一些meta信息。 <ignore_js_op>
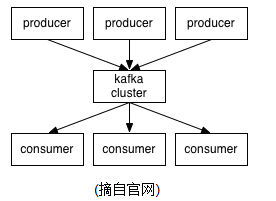 2、Topics/logs
一個Topic可以認為是一類消息,每個topic將被分成多個partition(區),每個partition在存儲層面是append log文件。任何發佈到此partition的消息都會被直接追加到log文件的尾部,每條消息在文件中的位置稱為offset(偏移量),offset為一個long型數字,它是唯一標記一條消息。它唯一的標記一條消息。kafka並沒有提供其他額外的索引機制來存儲offset,因為在kafka中幾乎不允許對消息進行“隨機讀寫”。
2、Topics/logs
一個Topic可以認為是一類消息,每個topic將被分成多個partition(區),每個partition在存儲層面是append log文件。任何發佈到此partition的消息都會被直接追加到log文件的尾部,每條消息在文件中的位置稱為offset(偏移量),offset為一個long型數字,它是唯一標記一條消息。它唯一的標記一條消息。kafka並沒有提供其他額外的索引機制來存儲offset,因為在kafka中幾乎不允許對消息進行“隨機讀寫”。
<ignore_js_op>
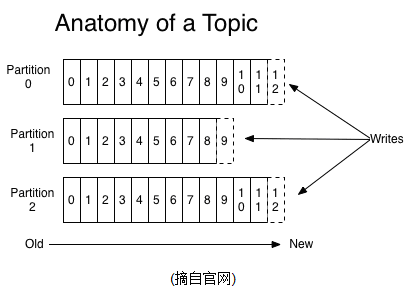
kafka和JMS(Java Message Service)實現(activeMQ)不同的是:即使消息被消費,消息仍然不會被立即刪除.日誌文件將會根據broker中的配置要求,保留一定的時間之後刪除;比如log文件保留2天,那麼兩天後,文件會被清除,無論其中的消息是否被消費.kafka通過這種簡單的手段,來釋放磁碟空間,以及減少消息消費之後對文件內容改動的磁碟IO開支. 對於consumer而言,它需要保存消費消息的offset,對於offset的保存和使用,有consumer來控制;當consumer正常消費消息時,offset將會"線性"的向前驅動,即消息將依次順序被消費.事實上consumer可以使用任意順序消費消息,它只需要將offset重置為任意值..(offset將會保存在zookeeper中,參見下文) kafka集群幾乎不需要維護任何consumer和producer狀態信息,這些信息有zookeeper保存;因此producer和consumer的客戶端實現非常輕量級,它們可以隨意離開,而不會對集群造成額外的影響. partitions的設計目的有多個.最根本原因是kafka基於文件存儲.通過分區,可以將日誌內容分散到多個server上,來避免文件尺寸達到單機磁碟的上限,每個partiton都會被當前server(kafka實例)保存;可以將一個topic切分多任意多個partitions,來消息保存/消費的效率.此外越多的partitions意味著可以容納更多的consumer,有效提升併發消費的能力.(具體原理參見下文). 3、Distribution 一個Topic的多個partitions,被分佈在kafka集群中的多個server上;每個server(kafka實例)負責partitions中消息的讀寫操作;此外kafka還可以配置partitions需要備份的個數(replicas),每個partition將會被備份到多台機器上,以提高可用性. 基於replicated方案,那麼就意味著需要對多個備份進行調度;每個partition都有一個server為"leader";leader負責所有的讀寫操作,如果leader失效,那麼將會有其他follower來接管(成為新的leader);follower只是單調的和leader跟進,同步消息即可..由此可見作為leader的server承載了全部的請求壓力,因此從集群的整體考慮,有多少個partitions就意味著有多少個"leader",kafka會將"leader"均衡的分散在每個實例上,來確保整體的性能穩定. Producers Producer將消息發佈到指定的Topic中,同時Producer也能決定將此消息歸屬於哪個partition;比如基於"round-robin"方式或者通過其他的一些演算法等. Consumers 本質上kafka只支持Topic.每個consumer屬於一個consumer group;反過來說,每個group中可以有多個consumer.發送到Topic的消息,只會被訂閱此Topic的每個group中的一個consumer消費. 如果所有的consumer都具有相同的group,這種情況和queue模式很像;消息將會在consumers之間負載均衡. 如果所有的consumer都具有不同的group,那這就是"發佈-訂閱";消息將會廣播給所有的消費者. 在kafka中,一個partition中的消息只會被group中的一個consumer消費;每個group中consumer消息消費互相獨立;我們可以認為一個group是一個"訂閱"者,一個Topic中的每個partions,只會被一個"訂閱者"中的一個consumer消費,不過一個consumer可以消費多個partitions中的消息.kafka只能保證一個partition中的消息被某個consumer消費時,消息是順序的.事實上,從Topic角度來說,消息仍不是有序的. kafka的設計原理決定,對於一個topic,同一個group中不能有多於partitions個數的consumer同時消費,否則將意味著某些consumer將無法得到消息. Guarantees 1) 發送到partitions中的消息將會按照它接收的順序追加到日誌中 2) 對於消費者而言,它們消費消息的順序和日誌中消息順序一致. 3) 如果Topic的"replicationfactor"為N,那麼允許N-1個kafka實例失效. 二、使用場景 1、Messaging 對於一些常規的消息系統,kafka是個不錯的選擇;partitons/replication和容錯,可以使kafka具有良好的擴展性和性能優勢.不過到目前為止,我們應該很清楚認識到,kafka並沒有提供JMS中的"事務性""消息傳輸擔保(消息確認機制)""消息分組"等企業級特性;kafka只能使用作為"常規"的消息系統,在一定程度上,尚未確保消息的發送與接收絕對可靠(比如,消息重發,消息發送丟失等) 2、Websit activity tracking kafka可以作為"網站活性跟蹤"的最佳工具;可以將網頁/用戶操作等信息發送到kafka中.並實時監控,或者離線統計分析等
3、Log Aggregation kafka的特性決定它非常適合作為"日誌收集中心";application可以將操作日誌"批量""非同步"的發送到kafka集群中,而不是保存在本地或者DB中;kafka可以批量提交消息/壓縮消息等,這對producer端而言,幾乎感覺不到性能的開支.此時consumer端可以使hadoop等其他系統化的存儲和分析系統. 三、設計原理 kafka的設計初衷是希望作為一個統一的信息收集平臺,能夠實時的收集反饋信息,並需要能夠支撐較大的數據量,且具備良好的容錯能力. 1、持久性 kafka使用文件存儲消息,這就直接決定kafka在性能上嚴重依賴文件系統的本身特性.且無論任何OS下,對文件系統本身的優化幾乎沒有可能.文件緩存/直接記憶體映射等是常用的手段.因為kafka是對日誌文件進行append操作,因此磁碟檢索的開支是較小的;同時為了減少磁碟寫入的次數,broker會將消息暫時buffer起來,當消息的個數(或尺寸)達到一定閥值時,再flush到磁碟,這樣減少了磁碟IO調用的次數.
2、性能 需要考慮的影響性能點很多,除磁碟IO之外,我們還需要考慮網路IO,這直接關係到kafka的吞吐量問題.kafka並沒有提供太多高超的技巧;對於producer端,可以將消息buffer起來,當消息的條數達到一定閥值時,批量發送給broker;對於consumer端也是一樣,批量fetch多條消息.不過消息量的大小可以通過配置文件來指定.對於kafka broker端,似乎有個sendfile系統調用可以潛在的提升網路IO的性能:將文件的數據映射到系統記憶體中,socket直接讀取相應的記憶體區域即可,而無需進程再次copy和交換. 其實對於producer/consumer/broker三者而言,CPU的開支應該都不大,因此啟用消息壓縮機制是一個良好的策略;壓縮需要消耗少量的CPU資源,不過對於kafka而言,網路IO更應該需要考慮.可以將任何在網路上傳輸的消息都經過壓縮.kafka支持gzip/snappy等多種壓縮方式. 3、生產者 負載均衡: producer將會和Topic下所有partition leader保持socket連接;消息由producer直接通過socket發送到broker,中間不會經過任何"路由層".事實上,消息被路由到哪個partition上,有producer客戶端決定.比如可以採用"random""key-hash""輪詢"等,如果一個topic中有多個partitions,那麼在producer端實現"消息均衡分發"是必要的. 其中partition leader的位置(host:port)註冊在zookeeper中,producer作為zookeeper client,已經註冊了watch用來監聽partition leader的變更事件. 非同步發送:將多條消息暫且在客戶端buffer起來,並將他們批量的發送到broker,小數據IO太多,會拖慢整體的網路延遲,批量延遲發送事實上提升了網路效率。不過這也有一定的隱患,比如說當producer失效時,那些尚未發送的消息將會丟失。
4、消費者 consumer端向broker發送"fetch"請求,並告知其獲取消息的offset;此後consumer將會獲得一定條數的消息;consumer端也可以重置offset來重新消費消息. 在JMS實現中,Topic模型基於push方式,即broker將消息推送給consumer端.不過在kafka中,採用了pull方式,即consumer在和broker建立連接之後,主動去pull(或者說fetch)消息;這中模式有些優點,首先consumer端可以根據自己的消費能力適時的去fetch消息並處理,且可以控制消息消費的進度(offset);此外,消費者可以良好的控制消息消費的數量,batch fetch. 其他JMS實現,消息消費的位置是有prodiver保留,以便避免重覆發送消息或者將沒有消費成功的消息重發等,同時還要控制消息的狀態.這就要求JMS broker需要太多額外的工作.在kafka中,partition中的消息只有一個consumer在消費,且不存在消息狀態的控制,也沒有複雜的消息確認機制,可見kafka broker端是相當輕量級的.當消息被consumer接收之後,consumer可以在本地保存最後消息的offset,並間歇性的向zookeeper註冊offset.由此可見,consumer客戶端也很輕量級. <ignore_js_op>

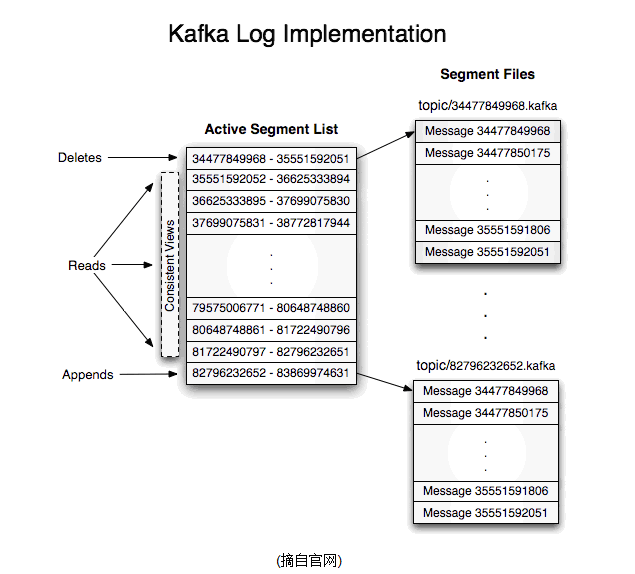 其中每個partiton中所持有的segments列表信息會存儲在zookeeper中.
當segment文件尺寸達到一定閥值時(可以通過配置文件設定,預設1G),將會創建一個新的文件;當buffer中消息的條數達到閥值時將會觸發日誌信息flush到日誌文件中,同時如果"距離最近一次flush的時間差"達到閥值時,也會觸發flush到日誌文件.如果broker失效,極有可能會丟失那些尚未flush到文件的消息.因為server意外實現,仍然會導致log文件格式的破壞(文件尾部),那麼就要求當server啟東是需要檢測最後一個segment的文件結構是否合法併進行必要的修複.
獲取消息時,需要指定offset和最大chunk尺寸,offset用來表示消息的起始位置,chunk size用來表示最大獲取消息的總長度(間接的表示消息的條數).根據offset,可以找到此消息所在segment文件,然後根據segment的最小offset取差值,得到它在file中的相對位置,直接讀取輸出即可.
日誌文件的刪除策略非常簡單:啟動一個後臺線程定期掃描log file列表,把保存時間超過閥值的文件直接刪除(根據文件的創建時間).為了避免刪除文件時仍然有read操作(consumer消費),採取copy-on-write方式.
8、分配
kafka使用zookeeper來存儲一些meta信息,並使用了zookeeper watch機制來發現meta信息的變更並作出相應的動作(比如consumer失效,觸發負載均衡等)
1) Broker node registry: 當一個kafkabroker啟動後,首先會向zookeeper註冊自己的節點信息(臨時znode),同時當broker和zookeeper斷開連接時,此znode也會被刪除.
格式: /broker/ids/[0...N] -->host:port;其中[0..N]表示broker id,每個broker的配置文件中都需要指定一個數字類型的id(全局不可重覆),znode的值為此broker的host:port信息.
2) Broker Topic Registry: 當一個broker啟動時,會向zookeeper註冊自己持有的topic和partitions信息,仍然是一個臨時znode.
格式: /broker/topics/[topic]/[0...N] 其中[0..N]表示partition索引號.
3) Consumer and Consumer group: 每個consumer客戶端被創建時,會向zookeeper註冊自己的信息;此作用主要是為了"負載均衡".
一個group中的多個consumer可以交錯的消費一個topic的所有partitions;簡而言之,保證此topic的所有partitions都能被此group所消費,且消費時為了性能考慮,讓partition相對均衡的分散到每個consumer上.
4) Consumer id Registry: 每個consumer都有一個唯一的ID(host:uuid,可以通過配置文件指定,也可以由系統生成),此id用來標記消費者信息.
格式:/consumers/[group_id]/ids/[consumer_id]
仍然是一個臨時的znode,此節點的值為{"topic_name":#streams...},即表示此consumer目前所消費的topic + partitions列表.
5) Consumer offset Tracking: 用來跟蹤每個consumer目前所消費的partition中最大的offset.
格式:/consumers/[group_id]/offsets/[topic]/[broker_id-partition_id]-->offset_value
此znode為持久節點,可以看出offset跟group_id有關,以表明當group中一個消費者失效,其他consumer可以繼續消費.
6) Partition Owner registry: 用來標記partition被哪個consumer消費.臨時znode
格式:/consumers/[group_id]/owners/[topic]/[broker_id-partition_id]-->consumer_node_id當consumer啟動時,所觸發的操作:
A) 首先進行"Consumer id Registry";
B) 然後在"Consumer id Registry"節點下註冊一個watch用來監聽當前group中其他consumer的"leave"和"join";只要此znode path下節點列表變更,都會觸發此group下consumer的負載均衡.(比如一個consumer失效,那麼其他consumer接管partitions).
C) 在"Broker id registry"節點下,註冊一個watch用來監聽broker的存活情況;如果broker列表變更,將會觸發所有的groups下的consumer重新balance.
<ignore_js_op>
其中每個partiton中所持有的segments列表信息會存儲在zookeeper中.
當segment文件尺寸達到一定閥值時(可以通過配置文件設定,預設1G),將會創建一個新的文件;當buffer中消息的條數達到閥值時將會觸發日誌信息flush到日誌文件中,同時如果"距離最近一次flush的時間差"達到閥值時,也會觸發flush到日誌文件.如果broker失效,極有可能會丟失那些尚未flush到文件的消息.因為server意外實現,仍然會導致log文件格式的破壞(文件尾部),那麼就要求當server啟東是需要檢測最後一個segment的文件結構是否合法併進行必要的修複.
獲取消息時,需要指定offset和最大chunk尺寸,offset用來表示消息的起始位置,chunk size用來表示最大獲取消息的總長度(間接的表示消息的條數).根據offset,可以找到此消息所在segment文件,然後根據segment的最小offset取差值,得到它在file中的相對位置,直接讀取輸出即可.
日誌文件的刪除策略非常簡單:啟動一個後臺線程定期掃描log file列表,把保存時間超過閥值的文件直接刪除(根據文件的創建時間).為了避免刪除文件時仍然有read操作(consumer消費),採取copy-on-write方式.
8、分配
kafka使用zookeeper來存儲一些meta信息,並使用了zookeeper watch機制來發現meta信息的變更並作出相應的動作(比如consumer失效,觸發負載均衡等)
1) Broker node registry: 當一個kafkabroker啟動後,首先會向zookeeper註冊自己的節點信息(臨時znode),同時當broker和zookeeper斷開連接時,此znode也會被刪除.
格式: /broker/ids/[0...N] -->host:port;其中[0..N]表示broker id,每個broker的配置文件中都需要指定一個數字類型的id(全局不可重覆),znode的值為此broker的host:port信息.
2) Broker Topic Registry: 當一個broker啟動時,會向zookeeper註冊自己持有的topic和partitions信息,仍然是一個臨時znode.
格式: /broker/topics/[topic]/[0...N] 其中[0..N]表示partition索引號.
3) Consumer and Consumer group: 每個consumer客戶端被創建時,會向zookeeper註冊自己的信息;此作用主要是為了"負載均衡".
一個group中的多個consumer可以交錯的消費一個topic的所有partitions;簡而言之,保證此topic的所有partitions都能被此group所消費,且消費時為了性能考慮,讓partition相對均衡的分散到每個consumer上.
4) Consumer id Registry: 每個consumer都有一個唯一的ID(host:uuid,可以通過配置文件指定,也可以由系統生成),此id用來標記消費者信息.
格式:/consumers/[group_id]/ids/[consumer_id]
仍然是一個臨時的znode,此節點的值為{"topic_name":#streams...},即表示此consumer目前所消費的topic + partitions列表.
5) Consumer offset Tracking: 用來跟蹤每個consumer目前所消費的partition中最大的offset.
格式:/consumers/[group_id]/offsets/[topic]/[broker_id-partition_id]-->offset_value
此znode為持久節點,可以看出offset跟group_id有關,以表明當group中一個消費者失效,其他consumer可以繼續消費.
6) Partition Owner registry: 用來標記partition被哪個consumer消費.臨時znode
格式:/consumers/[group_id]/owners/[topic]/[broker_id-partition_id]-->consumer_node_id當consumer啟動時,所觸發的操作:
A) 首先進行"Consumer id Registry";
B) 然後在"Consumer id Registry"節點下註冊一個watch用來監聽當前group中其他consumer的"leave"和"join";只要此znode path下節點列表變更,都會觸發此group下consumer的負載均衡.(比如一個consumer失效,那麼其他consumer接管partitions).
C) 在"Broker id registry"節點下,註冊一個watch用來監聽broker的存活情況;如果broker列表變更,將會觸發所有的groups下的consumer重新balance.
<ignore_js_op>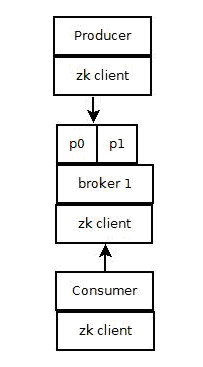 1) Producer端使用zookeeper用來"發現"broker列表,以及和Topic下每個partition leader建立socket連接併發送消息.
2) Broker端使用zookeeper用來註冊broker信息,已經監測partitionleader存活性.
3) Consumer端使用zookeeper用來註冊consumer信息,其中包括consumer消費的partition列表等,同時也用來發現broker列表,並和partition leader建立socket連接,並獲取消息.
四、主要配置
1、Broker配置
1) Producer端使用zookeeper用來"發現"broker列表,以及和Topic下每個partition leader建立socket連接併發送消息.
2) Broker端使用zookeeper用來註冊broker信息,已經監測partitionleader存活性.
3) Consumer端使用zookeeper用來註冊consumer信息,其中包括consumer消費的partition列表等,同時也用來發現broker列表,並和partition leader建立socket連接,並獲取消息.
四、主要配置
1、Broker配置
<ignore_js_op>

2.Consumer主要配置
<ignore_js_op>
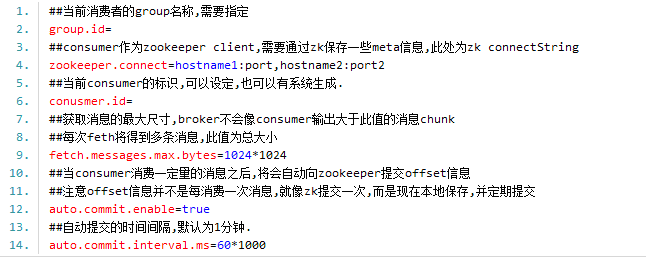
3.Producer主要配置
<ignore_js_op>

以上是關於kafka一些基礎說明,在其中我們知道如果要kafka正常運行,必須配置zookeeper,否則無論是kafka集群還是客戶端的生存者和消費者都無法正常的工作的,以下是對zookeeper進行一些簡單的介紹:
五、zookeeper集群 zookeeper是一個為分散式應用提供一致性服務的軟體,它是開源的Hadoop項目的一個子項目,並根據google發表的一篇論文來實現的。zookeeper為分散式系統提供了高笑且易於使用的協同服務,它可以為分散式應用提供相當多的服務,諸如統一命名服務,配置管理,狀態同步和組服務等。zookeeper介面簡單,我們不必過多地糾結在分散式系統編程難於處理的同步和一致性問題上,你可以使用zookeeper提供的現成(off-the-shelf)服務來實現來實現分散式系統額配置管理,組管理,Leader選舉等功能。 zookeeper集群的安裝,準備三台伺服器server1:192.168.0.1,server2:192.168.0.2, server3:192.168.0.3. 1)下載zookeeper 到http://zookeeper.apache.org/releases.html去下載最新版本Zookeeper-3.4.5的安裝包zookeeper-3.4.5.tar.gz.將文件保存server1的~目錄下 2)安裝zookeeper 先在伺服器server分別執行a-c步驟 a)解壓 tar -zxvf zookeeper-3.4.5.tar.gz 解壓完成後在目錄~下會發現多出一個目錄zookeeper-3.4.5,重新命令為zookeeper b)配置 將conf/zoo_sample.cfg拷貝一份命名為zoo.cfg,也放在conf目錄下。然後按照如下值修改其中的配置: # The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/home/wwb/zookeeper /data dataLogDir=/home/wwb/zookeeper/logs # the port at which the clients will connect clientPort=2181 # # Be sure to read the maintenance section of the # administrator guide before turning on autopurge. #http://zookeeper.apache.org/doc/ ... html#sc_maintenance # # The number of snapshots to retain in dataDir #autopurge.snapRetainCount=3 # Purge task interval in hours # Set to "0" to disable auto purge feature #autopurge.purgeInterval=1 server.1=192.168.0.1:3888:4888 server.2=192.168.0.2:3888:4888 server.3=192.168.0.3:3888:4888 tickTime:這個時間是作為 Zookeeper 伺服器之間或客戶端與伺服器之間維持心跳的時間間隔,也就是每個 tickTime 時間就會發送一個心跳。 dataDir:顧名思義就是 Zookeeper 保存數據的目錄,預設情況下,Zookeeper 將寫數據的日誌文件也保存在這個目錄里。 clientPort:這個埠就是客戶端連接 Zookeeper 伺服器的埠,Zookeeper 會監聽這個埠,接受客戶端的訪問請求。 initLimit:這個配置項是用來配置 Zookeeper 接受客戶端(這裡所說的客戶端不是用戶連接 Zookeeper 伺服器的客戶端,而是 Zookeeper 伺服器集群中連接到 Leader 的 Follower 伺服器)初始化連接時最長能忍受多少個心跳時間間隔數。當已經超過 5個心跳的時間(也就是 tickTime)長度後 Zookeeper 伺服器還沒有收到客戶端的返回信息,那麼表明這個客戶端連接失敗。總的時間長度就是 5*2000=10 秒 syncLimit:這個配置項標識 Leader 與Follower 之間發送消息,請求和應答時間長度,最長不能超過多少個 tickTime 的時間長度,總的時間長度就是2*2000=4 秒 server.A=B:C:D:其中 A 是一個數字,表示這個是第幾號伺服器;B 是這個伺服器的 ip 地址;C 表示的是這個伺服器與集群中的 Leader 伺服器交換信息的埠;D 表示的是萬一集群中的 Leader 伺服器掛了,需要一個埠來重新進行選舉,選出一個新的 Leader,而這個埠就是用來執行選舉時伺服器相互通信的埠。如果是偽集群的配置方式,由於 B 都是一樣,所以不同的 Zookeeper 實例通信埠號不能一樣,所以要給它們分配不同的埠號 註意:dataDir,dataLogDir中的wwb是當前登錄用戶名,data,logs目錄開始是不存在,需要使用mkdir命令創建相應的目錄。並且在該目錄下創建文件myid,serve1,server2,server3該文件內容分別為1,2,3。 針對伺服器server2,server3可以將server1複製到相應的目錄,不過需要註意dataDir,dataLogDir目錄,並且文件myid內容分別為2,3 3)依次啟動server1,server2,server3的zookeeper. /home/wwb/zookeeper/bin/zkServer.sh start,出現類似以下內容 JMX enabled by default Using config: /home/wwb/zookeeper/bin/../conf/zoo.cfg Starting zookeeper ... STARTED 4) 測試zookeeper是否正常工作,在server1上執行以下命令 /home/wwb/zookeeper/bin/zkCli.sh -server192.168.0.2:2181,出現類似以下內容 JLine support is enabled 2013-11-27 19:59:40,560 - INFO [main-SendThread(localhost.localdomain:2181):ClientCnxn$SendThread@736]- Session establishmentcomplete on server localhost.localdomain/127.0.0.1:2181, sessionid = 0x1429cdb49220000, negotiatedtimeout = 30000 WATCHER:: WatchedEvent state:SyncConnected type:None path:null [zk: 127.0.0.1:2181(CONNECTED) 0] [root@localhostzookeeper2]# 即代表集群構建成功了,如果出現錯誤那應該是第三部時沒有啟動好集群, 運行,先利用 ps aux | grep zookeeper查看是否有相應的進程的,沒有話,說明集群啟動出現問題,可以在每個伺服器上使用 ./home/wwb/zookeeper/bin/zkServer.sh stop。再依次使用./home/wwb/zookeeper/binzkServer.sh start,這時在執行4一般是沒有問題,如果還是有問題,那麼先stop再到bin的上級目錄執行./bin/zkServer.shstart試試。 註意:zookeeper集群時,zookeeper要求半數以上的機器可用,zookeeper才能提供服務。 六、kafka集群 (利用上面server1,server2,server3,下麵以server1為實例) 1)下載kafka0.8(http://kafka.apache.org/downloads.html),保存到伺服器/home/wwb目錄下kafka-0.8.0-beta1-src.tgz(kafka_2.8.0-0.8.0-beta1.tgz) 2)解壓 tar -zxvf kafka-0.8.0-beta1-src.tgz,產生文件夾kafka-0.8.0-beta1-src更改為kafka01 3)配置 修改kafka01/config/server.properties,其中broker.id,log.dirs,zookeeper.connect必鬚根據實際情況進行修改,其他項根據需要自行斟酌。大致如下: broker.id=1 port=9091 num.network.threads=2 num.io.threads=2 socket.send.buffer.bytes=1048576 socket.receive.buffer.bytes=1048576 socket.request.max.bytes=104857600 log.dir=./logs num.partitions=2 log.flush.interval.messages=10000 log.flush.interval.ms=1000 log.retention.hours=168 #log.retention.bytes=1073741824 log.segment.bytes=536870912 num.replica.fetchers=2 log.cleanup.interval.mins=10 zookeeper.connect=192.168.0.1:2181,192.168.0.2:2182,192.168.0.3:2183 zookeeper.connection.timeout.ms=1000000 kafka.metrics.polling.interval.secs=5 kafka.metrics.reporters=kafka.metrics.KafkaCSVMetricsReporter kafka.csv.metrics.dir=/tmp/kafka_metrics kafka.csv.metrics.reporter.enabled=false 4)初始化因為kafka用scala語言編寫,因此運行kafka需要首先準備scala相關環境。 > cd kafka01 > ./sbt update > ./sbt package > ./sbt assembly-package-dependency 在第二個命令時可能需要一定時間,由於要下載更新一些依賴包。所以請大家 耐心點。 5) 啟動kafka01 >JMX_PORT=9997 bin/kafka-server-start.sh config/server.properties & a)kafka02操作步驟與kafka01雷同,不同的地方如下 修改kafka02/config/server.properties broker.id=2 port=9092 ##其他配置和kafka-0保持一致 啟動kafka02 JMX_PORT=9998 bin/kafka-server-start.shconfig/server.properties & b)kafka03操作步驟與kafka01雷同,不同的地方如下 修改kafka03/config/server.properties broker.id=3 port=9093 ##其他配置和kafka-0保持一致 啟動kafka02 JMX_PORT=9999 bin/kafka-server-start.shconfig/server.properties & 6)創建Topic(包含一個分區,三個副本) >bin/kafka-create-topic.sh--zookeeper 192.168.0.1:2181 --replica 3 --partition 1 --topicmy-replicated-topic 7)查看topic情況 >bin/kafka-list-top.sh --zookeeper 192.168.0.1:2181 topic: my-replicated-topic partition: 0 leader: 1 replicas: 1,2,0 isr: 1,2,0 8)創建發送者 >bin/kafka-console-producer.sh--broker-list 192.168.0.1:9091 --topic my-replicated-topic my test message1 my test message2 ^C 9)創建消費者 >bin/kafka-console-consumer.sh --zookeeper127.0.0.1:2181 --from-beginning --topic my-replicated-topic ... my test message1 my test message2 ^C 10)殺掉server1上的broker >pkill -9 -f config/server.properties 11)查看topic >bin/kafka-list-top.sh --zookeeper192.168.0.1:2181 topic: my-replicated-topic partition: 0 leader: 1 replicas: 1,2,0 isr: 1,2,0 發現topic還正常的存在 11)創建消費者,看是否能查詢到消息 >bin/kafka-console-consumer.sh --zookeeper192.168.0.1:2181 --from-beginning --topic my-replicated-topic ... my test message 1 my test message 2 ^C 說明一切都是正常的。 OK,以上就是對Kafka個人的理解,不對之處請大家及時指出。 補充說明: 1、public Map<String, List<KafkaStream<byte[], byte[]>>> createMessageStreams(Map<String, Integer> topicCountMap),其中該方法的參數Map的key為topic名稱,value為topic對應的分區數,譬如說如果在kafka中不存在相應的topic時,則會創建一個topic,分區數為value,如果存在的話,該處的value則不起什麼作用
2、關於生產者向指定的分區發送數據,通過設置partitioner.class的屬性來指定向那個分區發送數據,如果自己指定必須編寫相應的程式,預設是kafka.producer.DefaultPartitioner,分區程式是基於散列的鍵。
3、在多個消費者讀取同一個topic的數據,為了保證每個消費者讀取數據的唯一性,必須將這些消費者group_id定義為同一個值,這樣就構建了一個類似隊列的數據結構,如果定義不同,則類似一種廣播結構的。
4、在consumerapi中,參數設計到數字部分,類似Map<String,Integer>, numStream,指的都是在topic不存在的時,會創建一個topic,並且分區個數為Integer,numStream,註意如果數字大於broker的配置中num.partitions屬性,會以num.partitions為依據創建分區個數的。
5、producerapi,調用send時,如果不存在topic,也會創建topic,在該方法中沒有提供分區個數的參數,在這裡分區個數是由服務端broker的配置中num.partitions屬性決定的 關於kafka說明可以參考:http://kafka.apache.org/documentation.html 今天我老婆有事請假回家了,這樣我家裡有兩台筆記本可以讓我做kafk集群了(2以上就是複數了,複數就可以稱之為集群了,恩,邏輯沒問題),要抓緊利用這3,5天把kafka得理解加運用再上一個檔次,順便要加快和strom集成速度!好了明天還要上班,各位慢慢看把,晚安! 對了,如果有kafka相關得學習建議,務必告訴我哦,我會很感激你得!


