
在上篇文章 淺談SQL Server內部運行機制 中,與大家分享了SQL Server內部運行機制,通過上次的分享,相信大家已經能解決如下幾個問題: 1.SQL Server 體繫結構由哪幾部分組成? 2.SQL Server 體繫結構各模塊之間關係是怎樣的? 3.SQL Server 體繫結構內部 ...
在上篇文章 淺談SQL Server內部運行機制 中,與大家分享了SQL Server內部運行機制,通過上次的分享,相信大家已經能解決如下幾個問題:
1.SQL Server 體繫結構由哪幾部分組成?
2.SQL Server 體繫結構各模塊之間關係是怎樣的?
3.SQL Server 體繫結構內部運行機制是怎樣的?
4.簡單的一條SELECT語句,在SQL Server中是如何一步一步執行的?
然而,僅僅能解決如上幾個問題,是不具有SQL Server資料庫優化能力的,為什麼這麼說,我們先提出如下幾個問題:
1.為什麼會記憶體溢出?(上篇文章開篇提出的)
2.為什麼會產生死鎖,閂鎖?
3.什麼叫執行計劃,如何分析執行計劃?
4. Index Scan 與Index Seek區別?

5.什麼叫聚集索引和非聚集索引?
6.什麼叫堆和B-數?
7.優化SQL Server,應該建立怎樣的一套優化理念?
8.SQL Server優化時,常用的檢測工具,優化工具和優化手段都有哪些?
9.你瞭解這些表與函數嗎?
Sys.dm_exec_requests,Sys.dm_exec_sql_text,Sys.dm_exec_session,Sys.dm_exec_connections,Sys.dm_exec_query_stats,Sys.dm_exec_query_resource_semaphores
10.為什麼磁碟臂是I/O的最大開銷?
11.什麼叫碎片,為什麼會產生碎片?
12.什麼叫跨域,什麼叫主從同步?
13.為什麼要分區,為什麼要拆表(水平拆分,垂直拆分)?
..........
如上的這些基礎問題,若不能很好地解決,就急忙去研究SQL Server優化,甚至去實戰,是會繞很多彎路的,且學得一知半解。我們就拿索引舉個例子,一張UserInfo(UserName,Address,Sex)有1000萬條數據,
當我們查詢時,非常緩慢,為了提高查詢速度,我們優先想到的是建立索引(其他條件不變情況下,如不增加CPU,不增加記憶體,不改變磁碟等),有經驗的DBA和資料庫優化高手,是不會選擇Addresss和sex作為索引字
段的,想想為什麼?
基於如上的種種問題,本篇文章還是繼續從理論角度分析SQL Server的一些基本理論,為後續的SQL Server優化實戰打好良好的功底,至於具體的優化實戰,應該會在第四篇或第五篇文章開始講解(本篇文章
為SQL Server資料庫優化系列第二篇),本篇文章大致包括如下內容。(當然,本篇文章未必能全部解決如上提出的問題,但在SQL Server理論性問題介紹結束,大家應該知道如何解決,然後再去實戰)
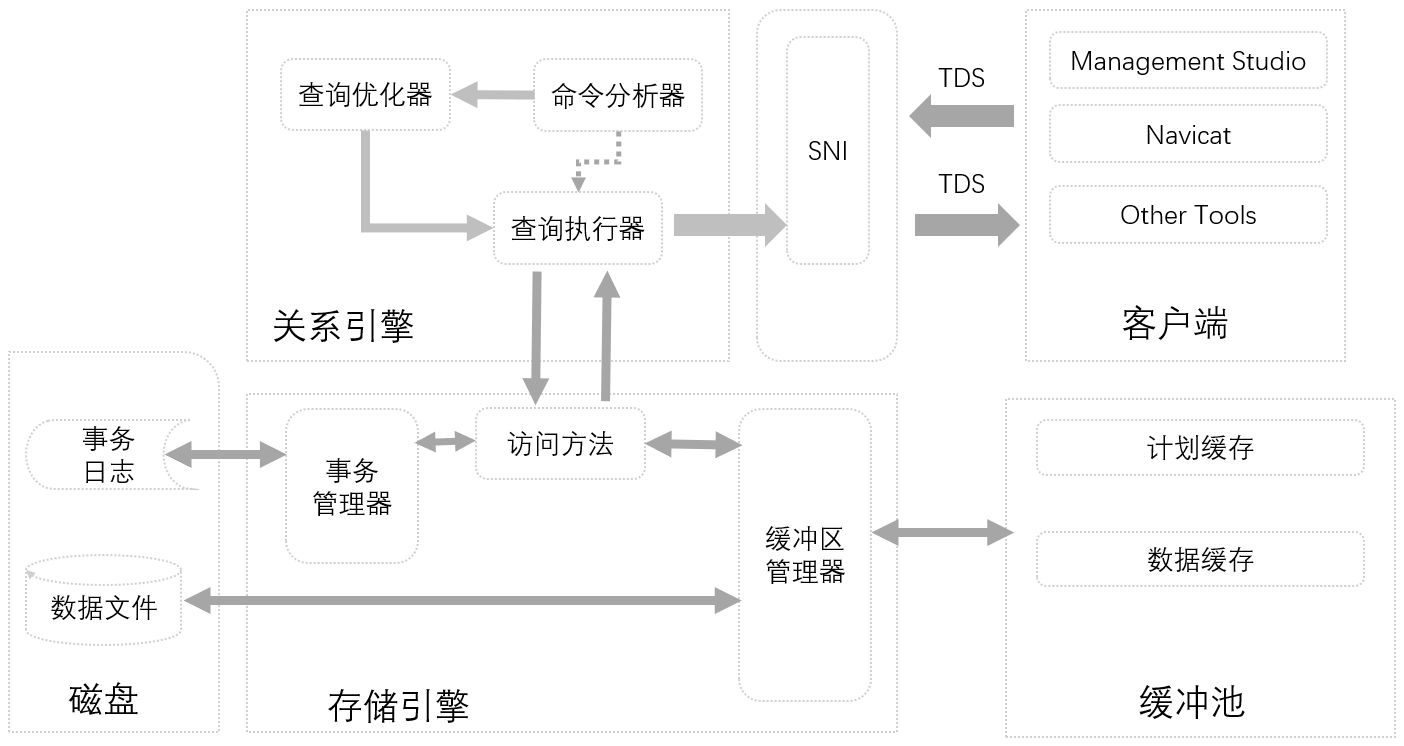
- SQL Server引擎及集群
- SQL Server數據文件存儲
- SQL Server table表數據的存儲形式
- Page的基本構成
- 若幹基本概念:堆(Heap)、分區、B-Tree、行數據溢出、Master-Slave等
一 SQL Server引擎及集群
首先,我們要知道什麼叫做SQL Server伺服器?SQL Server伺服器部署在伺服器端,用來存儲數據的,如系統數據(如系統資料庫master,tempdb等)、用戶數據(如自定義資料庫數據)和日誌數據(如Log Files)等。
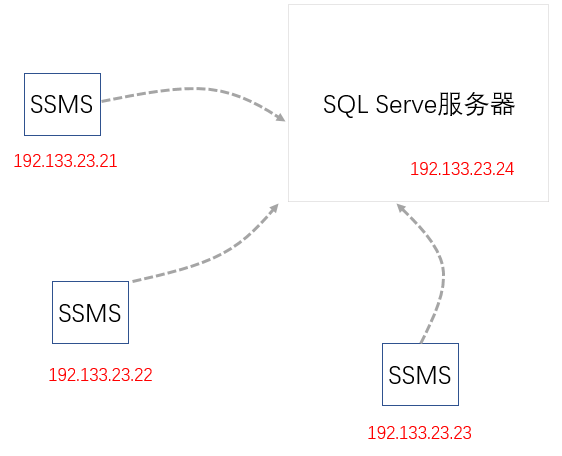
一般地,SQL Server為我們提供了客戶端訪問工具SSMS(Microsoft SQL Server Management Studio),通過該工具,我們能訪問SQL Server伺服器,從而通過客戶端SQL語句,獲取我們想要的數據,SQL Server最為簡
單的模式是:客戶端《=》伺服器模式,即只有一臺SQL Server伺服器,供一個或多個客戶端訪問,這種架構是最為簡單的,也是大部分小公司常用的架構。下圖為三個不同IP的SQL Server客戶端工具SSMS訪問同一個
SQL Server伺服器。
其次,對於具有一定規模,有一定數據量的公司,單台SQL Server服務滿足不了業務需求,如系統訪問速度慢(一般用戶能容忍的時間是3秒,時間超過3秒,用戶就感覺不良好)、數據量大(單台SQL Server伺服器無法支撐)等,
這時,就需要2台及以上SQL Server伺服器(當然,實際的架構中,不僅僅是SQL Server伺服器之間集群,還有可能是SQL Server伺服器,Oracle伺服器、MySQL伺服器之間跨伺服器、跨域的集群),通過多台SQL Server伺服器集群,
形成一個龐大的中央伺服器,來處理高併發,大數據量、訪問速度等性能問題,常見的是一個例子就是讀寫分離,主從同步。

下圖是在四個IP不同的伺服器上分別部署一臺SQL Server伺服器引擎和每台伺服器的SQL Server引擎包括的基本內容。
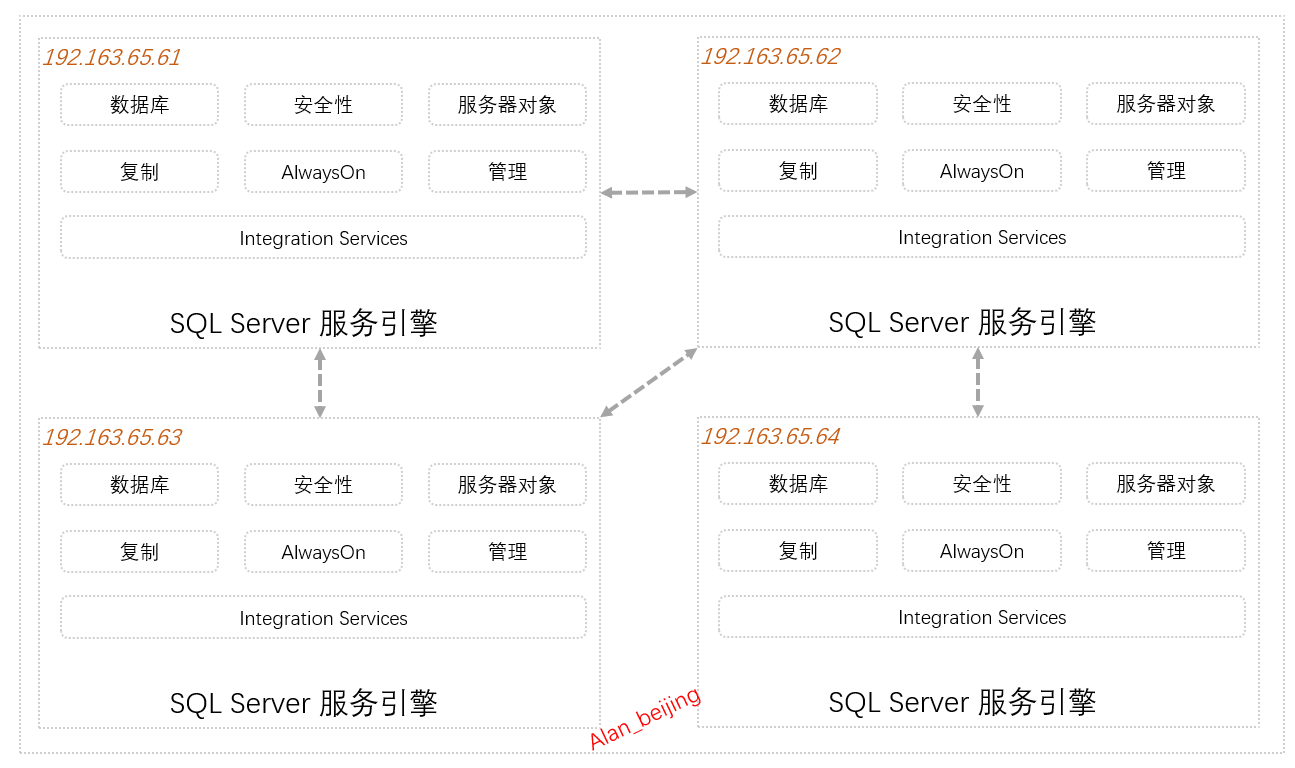
(一)SQL Server 引擎基本內容
1.資料庫
2.安全性
3.伺服器對象
4.複製
5.AlwaysON
6.管理
7.Integration Services
(二)SQL Server引擎之間關係
1.跨域
2.跨域數據主從同步
二 SQL Server 數據文件存儲
在瞭解SQL Server伺服器基本構成,SQL Server伺服器部署,SQL Server伺服器集群和客戶端訪問工具SSMS如何訪問SQL Server伺服器後,接下來,我們將目標定位在單個SQL Server伺服器上,研究
SQL Server單個伺服器,通過第一部分,我們知道單個SQL Server伺服器的基本組成,接下來,我們來分析SQL Server伺服器都有哪些文件,且它們分別以什麼樣的形式存儲,存儲在哪?
對於SQL Server,資料庫文件和日誌文件是其兩大類核心文件。

數據文件主要用來存儲相關數據的,如系統資料庫(master,model,msdb,tempdb)文件,用戶自定義資料庫文件,日誌文件等。
1.資料庫文件主要包括兩個核心文件(.mdf-文件為主要文件,.ndf-文件為次要文件),當創建資料庫時,系統預設會創建.mdf文件和.ndf文件,這兩個文件是以頁(page)的
方式存儲的,它們用來保存一些資料庫對象,如保存表數據,索引數據,約束等;
2.日誌文件(Virtual Log Files,簡稱VLF),這種文件不是按照頁的方式存儲的,換句說,他們存儲的大小是不確定的,是任意的。
三 Table表數據的存儲形式
通過第二部分,我們知道了SQL Server伺服器主要有兩大類資源文件,即資料庫文件和日誌文件,其中,對於用戶或者一般開發人員來說,資料庫文件應該算是他們最關心的文件,
然而,資料庫文件有很多資源對象,如實體表(table),視圖(View),索引(Index),約束(Constraint)等等,面對這麼多資料庫對象,我們該如何研究呢?是全部研究,還是選擇重點研究?當然是選擇重點研究,
我們將選擇用戶或開發人員使用頻率最多的實體表(table)作為研究對象。
本小節,我們主要討論幾個問題:table是如何存儲的,什麼是分區,什麼是堆,什麼是B-樹,以及它們之間的關係是怎樣的?
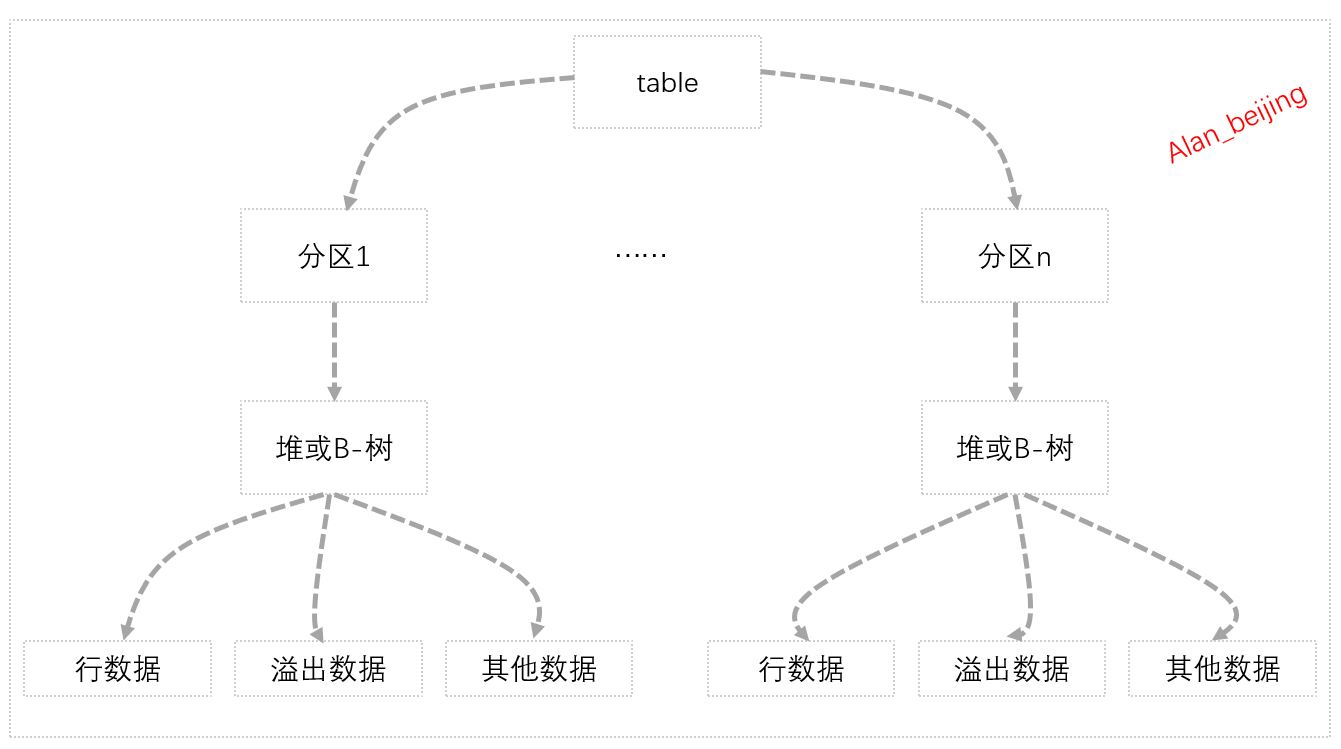
(一)實體表的兩種存儲方式
對於SQL Server中的實體表數據,在SQL Server中的存儲形式表現為堆存儲(Heap)和B樹存儲(B-Tree,B+Tree)。
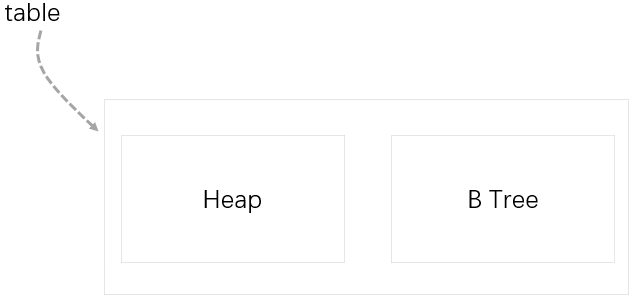
(二)Heap
1.堆,指不含有聚集索引的表,之所以稱為堆,是因為它的數據不按任何順序進行組織,而是按分區組對數據進行組織。
2.在堆中,用於保存數據之間關係的唯一索引結構是索引分配映射(IAM,Index Allocation Map)的點陣圖,對於混合區(mixed extent)分配的前8個頁,這個點陣圖中有指向這些頁的指針,
它還包括一個大點陣圖(每個位代表文件中的4G範圍內的一個區)。
3.堆不是按照特定順序來維護的,所以新增加到列表中的行可以保存到任何數據頁上。SQL Server使用頁可用空間頁(PFS,Page Free Space)的點陣圖來跟蹤數據頁中的可用空間,以
便可以快速地找到有足夠空間能夠容納新行的頁面,如果這樣的頁面不存在,則分配一個新頁面,對於長度可變的列進行更新時,行的大小就會擴展,頁可能會因為沒有空間而無法容納
新增加的行,此時,SQL Server 會把擴展後的行移動到具有足夠空間的頁上,而在原來的位置上保留一個所謂的正向指針(forwarding pointer),,通過它指向行的新位置。
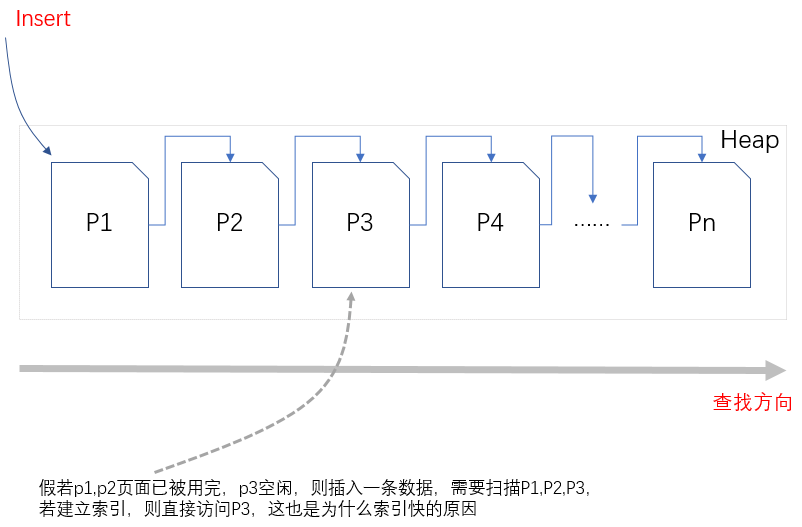
(三)區
區是由8個物理連續的頁組成的單元。當表或索引需要更多的空間以存儲數據時,SQL Server為對象分配一個完整的區。

1.對於包含少量數據的對象,當對象不足64KB時,SQL Server通常只分配一個單獨的頁,而不是整個區
2.區按存儲是否為同一對象,可分為混合區(區8個連續的頁存儲不同對象)和非混合區(區8個連續的頁存儲相同的對象)
3.當刪除(delete)或清空(Truncate)表時,將會釋放區
4.一些讀操作,如大型表或索引掃描的預讀(read-ahead),可以在區級別,或更高的快級別讀取數據
5.I/O操作最大的開銷是磁碟臂的移動,而真正的磁碟讀寫操作開銷要小得多,因此,讀取一個頁和讀取一個區所用得時間幾乎一樣
(四)B Tree
B樹是一種存儲結構,如B+Tree,B-Tree,其中,B-Tree是我們重點關心的,B-Tree是一種平衡樹,主要用來存儲聚集索引相關數據的,在這裡不重點論述,只要知道有這麼個概念即可,
在索引(Index)章節,我會重點論述。
(五)行數據、溢出數據和其他數據
詳見本篇博文第四部分。
四 頁的基本構成
通過前面幾節介紹,我們知道,頁是存儲的最小單位(其實,頁也是IO的最小單位,每次從磁碟DB中讀取數據到緩衝池,都是以頁為單位讀取的),那麼SQL Server中的Page又是什麼呢?它
的基本結構又是怎樣的呢?下圖為SQL Server中,一個Page的基本構成。
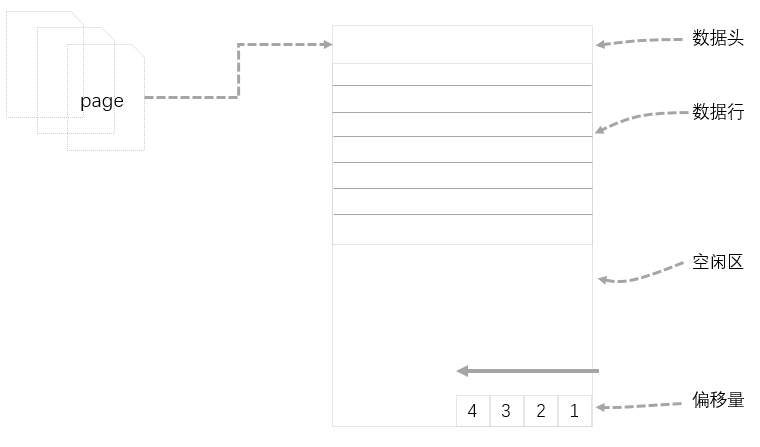
(一)頁描述
頁是SQL Server存儲數據的基本單位,大小為8KB,它可以包含表或索引數據、分配點陣圖、可用空間信息等。在SQL Server中,頁是數據存儲的最小單位,也是數據讀取的最小IO。
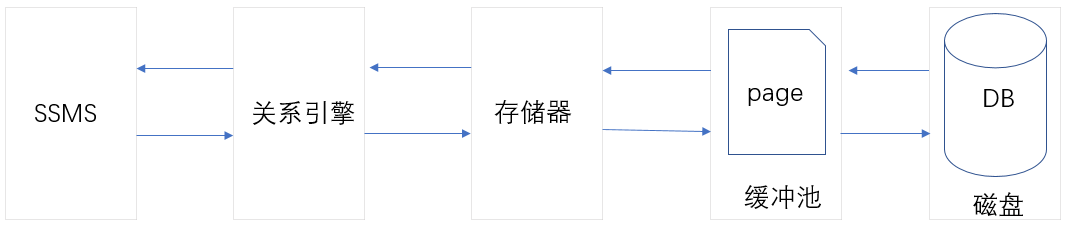
(二)頁的基本構成
SQL Server Page主要由四部分構成,頁頭(Page Header),數據行(Data Row),空閑區(Free)和偏移量(Offset)。
1.頁是數據存儲的最小單位,頁是數據讀取的最小IO;
2.一個頁的大小為8KB,其中頁頭占據96B(96個位元組),頁尾維護的行指針占據2B(2個位元組),還有其他保留欄位以備後用。
3.SQL Server 2005後,為了滿足VARCHAR,NVARCHAR,VARBINARY,SQL_VARIANT和CLR用戶定義類型,放寬了對行大小的限制,這個技術就叫做行溢出數據。
4.行溢出數據,指當行超過8060位元組時,這些類型的值將被移動到一個成為行溢出分配單元中的頁中,而在原始頁上保留一個24位元組的指針,指向行外的數據,如此,行就
可以跨多個頁,但行內數據任然在8060位元組限制內。如果類型值在8000位元組以內,它們的值將被移動到行溢出頁中;如果超過8000位元組,這些值在內部將被存儲為一個大類型
對象,而在原始行上維護一個16位元組的指針,指向該大型對象值。
五 參考文獻
【01】《SQL Server 2012 深入解析與性能優化 第3版》Christian Bolton,Justin Langford,Glenn Berry,Gavin Payne,Amit Banerjee,Rob Farley著
【02】《SQL Server 2008查詢性能優化》Grant Fritchey,Sajal Dam著
【03】《Microsoft SQL Server 2008 技術內幕:T-SQL查詢》ltzik Ben-Gran,Lubor Kollar,Dejan Sarka,Steve Kass著
六 版權區
- 感謝您的閱讀,若有不足之處,歡迎指教,共同學習、共同進步。
- 博主網址:http://www.cnblogs.com/wangjiming/。
- 極少部分文章利用讀書、參考、引用、抄襲、複製和粘貼等多種方式整合而成的,大部分為原創。
- 如您喜歡,麻煩推薦一下;如您有新想法,歡迎提出,郵箱:[email protected]。
- 可以轉載該博客,但必須著名博客來源。

