前言 前段時間有幸接觸到Apache Carbondata,試用過程中發現了一個小小的問題,並且又很快的定位到了問題。然後在社區群里反映了下,負責人問願不願意提個JIRA,PR,然後我在沒有任何開源項目PR過的情況下竟然欣然答應了。(可能跟ZB心有關吧o(╥﹏╥)o)然後來說說這段美妙而又酸爽的經歷 ...
前言
前段時間有幸接觸到Apache Carbondata,試用過程中發現了一個小小的問題,並且又很快的定位到了問題。然後在社區群里反映了下,負責人問願不願意提個JIRA,PR,然後我在沒有任何開源項目PR過的情況下竟然欣然答應了。(可能跟ZB心有關吧o(╥﹏╥)o)然後來說說這段美妙而又酸爽的經歷吧【學習到了很多】!
簡介
CarbonData是首個由中國公司發起並捐獻給Apache基金會的開源項目,於2017年4月正式成為Apache頂級項目,由華為開源並支持Hadoop的高性能列式存儲文件格式,其目的是提供一種統一的數據存儲方案,以一份數據同時支持大數據分析的多種應用場景,All In One,並通過多級索引、字典編碼、列式存儲等特性提升 I/O 掃描和計算性能,實現百億數據級秒級響應。目前最新版是1.5.1,集成了spark 2.1.0,2.2.1,2.3.2和Hadoop2.7.2,如果是其它版本,則需要自己編譯源碼!
優勢
1. 規模比impala+kudu大,基於MPP架構的系統很難超過100節點。
2. 沒有進程,不需要單獨部署集群,在現有hadoop/spark/presto上即可以使用。
3. 有索引,對多維過濾查詢不用全掃描。
4. 有預匯聚,對OLAP
問題
先拋出來試用過程中出現的問題。carbondata版本:1.5.0,spark 2.3.2 模式:本地 spark-shell
例子:http://carbondata.apache.org/quick-start-guide.html
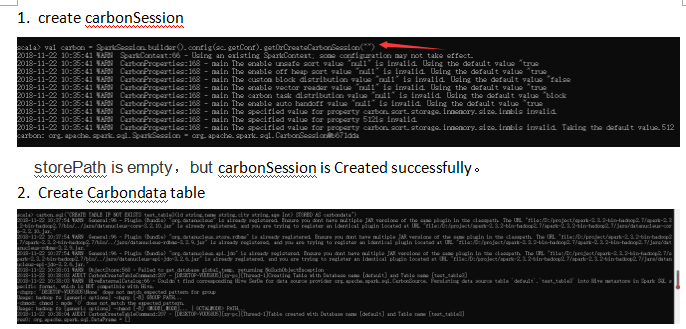
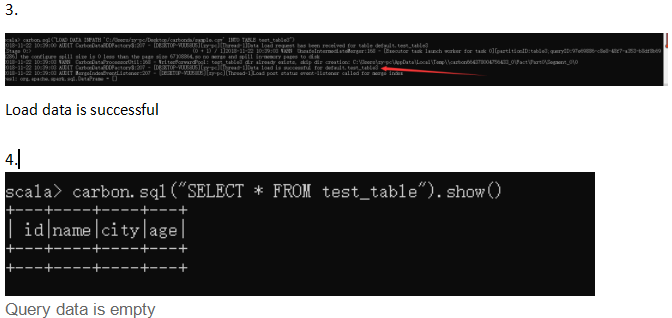
問題描述:
上面是提交JIRA的時候提交的bug再現流程,總的就是在創建 carbondata 的時候,getOrCreateCarbonSession方法預設有兩個參數 storePath(存儲table數據) metaStorePath(t存儲able元數據),不傳的話會預設創建,但可能好多人第一次使用的時候不清楚,然後會根據quick start 傳一個空字元串,造成的結果就是每一步都顯示成功,但最終carbondata表結果查詢卻是空。通過查看源碼,在carbondata\integration\spark2模塊中發現 getOrCreateCarbonSession 方法的storePath,metaStorePath參數都只是簡單的 null 的判斷,所以造成了本地創建storePath存儲在空字元串中,導致最終查詢不出來結果。
解決方案:
使用 StringUtils.isNotBlank 替代原來的簡單 null 判斷。
流程
1) 首先註冊Apache JIRA 賬號(沒有的話),註意在這一定要描述清楚你的問題的是什麼,屬於什麼類型(優先順序不一樣) 例子:https://issues.apache.org/jira/projects/CARBONDATA/issues/CARBONDATA-3119?filter=allopenissues
2)fork ,https://github.com/apache/carbondata。
3)a. git config:
$ git config --global user.email "[email protected]" --輸入自己的git郵箱
$ git config --global user.name "xxxxx" --輸入自己的git name
b. git clone
$ git clone https://github.com/apache/carbondata.git --把源碼下載到自己置頂的本地目錄
c.
git remote add XXXX https://github.com/XXXX/carbondata.git --跟fork下來的carbondata git倉庫關聯起來
d.
git fetch --all
git checkout -b master --直接使用master分支(當然也可以創建自己的分支)
e.
git add 修改的文件
git commit -m "本次commit說明"
git rebase -i 分支名字 -- 這個命令是用來修改 已提交的 commit 的說明的。就是開源項目都有自己嚴格的規範,不合格需要重新提交commit說明
f:
git push 遠程主機名 分支名 --提交到遠程倉庫 本地分支名和遠程分支名一致
當然遠程提交之前確保測試用例是通過的,然後就可以直接在fork下來的倉庫中 點擊 Pull request了,一般這的說明都會有嚴格的模板例子,所以不要擅自改格式。提交了PR之後,就註意郵件消息等回覆,需要修改或者不規範的地方需要回工,知道最終被merge。然後恭喜你就成為一名Apache carbondata 的contributors之一了。 那麼樓主我自己很榮幸也是拿到了獎勵的華為 小天鵝 藍牙音箱,最主要的是榮譽感滿滿(雖然是小小的一次修改,但畢竟是第一次嘛,第一次還是很值得留念的博友們)
項目編譯過程中遇到的問題:
1)在windows編譯的的時候 maven 命令:
clean -DskipTests -Pbuild-with-format -Pspark-2.3 -Pwindows install
2)首先需要本地安裝 thrift 0.93,並配置環境變數。 根據 thrift --version查看是否安裝成功
3)import scala 包是有分組和組內排序的,註釋也有嚴格的格式。 不然編譯的時候會報 代碼style不對,編譯通不過的。
Apache carbondata官方網站: http://carbondata.apache.org/