Zookeeper是一個開源的分散式的,為分散式應用提供協調服務的Apache項目。 1. Zookerper工作機制 2. Zookeeper工作特點 3. Zookeeper文件系統:znode不區分文件與文件夾 4. Zookeeper配置文件參數: tickTime =2000:通信心跳數, ...
Zookeeper是一個開源的分散式的,為分散式應用提供協調服務的Apache項目。
1. Zookerper工作機制

2. Zookeeper工作特點
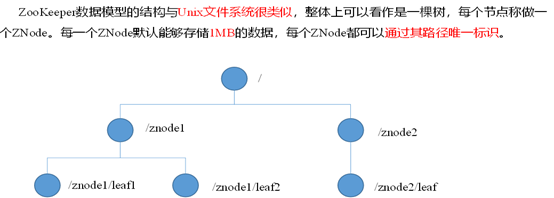
3. Zookeeper文件系統:znode不區分文件與文件夾
4. Zookeeper配置文件參數:
tickTime =2000:通信心跳數,Zookeeper伺服器與客戶端心跳時間,單位毫秒
Zookeeper使用的基本時間,伺服器之間或客戶端與伺服器之間維持心跳的時間間隔,也就是每個tickTime時間就會發送一個心跳,時間單位為毫秒。
它用於心跳機制,並且設置最小的session超時時間為兩倍心跳時間。(session的最小超時時間是2*tickTime)
initLimit =10:LF初始通信時限
集群中的Follower跟隨者伺服器與Leader領導者伺服器之間初始連接時能容忍的最多心跳數(tickTime的數量),用它來限定集群中的Zookeeper伺服器連接到Leader的時限。
syncLimit =5:LF同步通信時限
集群中Leader與Follower之間的最大響應時間單位,假如響應超過syncLimit * tickTime,Leader認為Follwer死掉,從伺服器列表中刪除Follwer。
dataDir:數據文件目錄+數據持久化路徑
主要用於保存Zookeeper中的數據。
clientPort =2181:客戶端連接埠
監聽客戶端連接的埠。
5. Zookeeper分散式安裝
1. 集群規劃
2. 解壓安裝
解壓Zookeeper安裝包到/opt/module/目錄下
同步/opt/module/zookeeper-3.4.10目錄內容
3.配置伺服器編號
(1)在/opt/module/zookeeper-3.4.10/這個目錄下創建zkData
(2)在/opt/module/zookeeper-3.4.10/zkData目錄下創建一個myid的文件
(3)編輯myid文件,在文件中添加與server對應的編號
(4)拷貝配置好的zookeeper到其他機器上,並修改myid
4.配置zoo.cfg文件
(1)重命名/opt/module/zookeeper-3.4.10/conf這個目錄下的zoo_sample.cfg為zoo.cfg
(2)打開zoo.cfg文件
修改數據存儲路徑配置
dataDir=/opt/module/zookeeper-3.4.10/zkData
增加如下配置
#######################cluster##########################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
(3)配置參數解讀
server.A=B:C:D。
A是一個數字,表示這個是第幾號伺服器;
集群模式下配置一個文件myid,這個文件在dataDir目錄下,這個文件裡面有一個數據就是A的值,Zookeeper啟動時讀取此文件,拿到裡面的數據與zoo.cfg裡面的配置信息比較從而判斷到底是哪個server。
B是這個伺服器的地址;
C是這個伺服器Follower與集群中的Leader伺服器交換信息的埠;
D是萬一集群中的Leader伺服器掛了,需要一個埠來重新進行選舉,選出一個新的Leader,而這個埠就是用來執行選舉時伺服器相互通信的埠。
6. 客戶端操作
Bin目錄 ./zkCli.sh 登錄客戶端
|
命令基本語法 |
功能描述 |
|
help |
顯示所有操作命令 |
|
ls path [watch] |
使用 ls 命令來查看當前znode中所包含的內容 |
|
ls2 path [watch] |
查看當前節點數據並能看到更新次數等數據 |
|
create |
普通創建 -s 含有序列 -e 臨時(重啟或者超時消失) |
|
get path [watch] |
獲得節點的值 |
|
set |
設置節點的具體值 |
|
stat |
查看節點狀態 |
|
delete |
刪除節點 |
|
rmr |
遞歸刪除節點 |
7.
- Stat結構體
1)czxid-創建節點的事務zxid
每次修改ZooKeeper狀態都會收到一個zxid形式的時間戳,也就是ZooKeeper事務ID。
事務ID是ZooKeeper中所有修改總的次序。每個修改都有唯一的zxid,如果zxid1小於zxid2,那麼zxid1在zxid2之前發生。
2)ctime - znode被創建的毫秒數(從1970年開始)
3)mzxid - znode最後更新的事務zxid
4)mtime - znode最後修改的毫秒數(從1970年開始)
5)pZxid-znode最後更新的子節點zxid
6)cversion - znode子節點變化號,znode子節點修改次數
7)dataversion - znode數據變化號
8)aclVersion - znode訪問控制列表的變化號
9)ephemeralOwner- 如果是臨時節點,這個是znode擁有者的session id。如果不是臨時節點則是0。
10)dataLength- znode的數據長度
11)numChildren - znode子節點數量
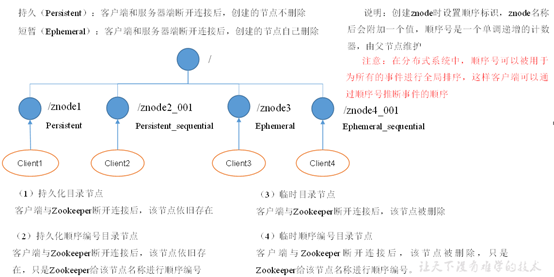
8. 四種節點類型
9. 監聽器原理
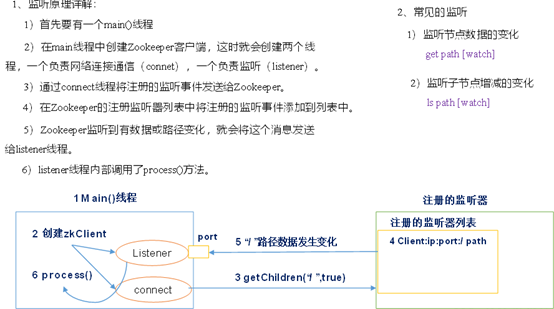 。
。
10. Paxos演算法
11. 選舉機制
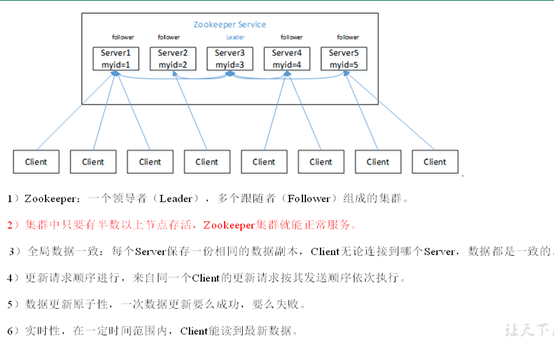
1)半數機制:集群中半數以上機器存活,集群可用。所以Zookeeper適合安裝奇數台伺服器
2)Zookeeper雖然在配置文件中並沒有指定Master和Slave。但是,Zookeeper工作時,是有一個節點為Leader,其他則為Follower,Leader是通過內部的選舉機制臨時產生的。
3)以一個簡單的例子來說明整個選舉的過程。
假設有五台伺服器組成的Zookeeper集群,它們的id從1-5,同時它們都是最新啟動的,也就是沒有歷史數據,在存放數據量這一點上,都是一樣的。假設這些伺服器依序啟動

(1)伺服器1啟動,發起一次選舉。伺服器1投自己一票。此時伺服器1票數一票,不夠半數以上(3票),選舉無法完成,伺服器1狀態保持為LOOKING;
(2)伺服器2啟動,再發起一次選舉。伺服器1和2分別投自己一票並交換選票信息:此時伺服器1發現伺服器2的ID比自己目前投票推舉的(伺服器1)大,更改選票為推舉伺服器2。此時伺服器1票數0票,伺服器2票數2票,沒有半數以上結果,選舉無法完成,伺服器1,2狀態保持LOOKING
(3)伺服器3啟動,發起一次選舉。此時伺服器1和2都會更改選票為伺服器3。此次投票結果:伺服器1為0票,伺服器2為0票,伺服器3為3票。此時伺服器3的票數已經超過半數,伺服器3當選Leader。伺服器1,2更改狀態為FOLLOWING,伺服器3更改狀態為LEADING;
(4)伺服器4啟動,發起一次選舉。此時伺服器1,2,3已經不是LOOKING狀態,不會更改選票信息。交換選票信息結果:伺服器3為3票,伺服器4為1票。此時伺服器4服從多數,更改選票信息為伺服器3,並更改狀態為FOLLOWING;
(5)伺服器5啟動,同4一樣當小弟。
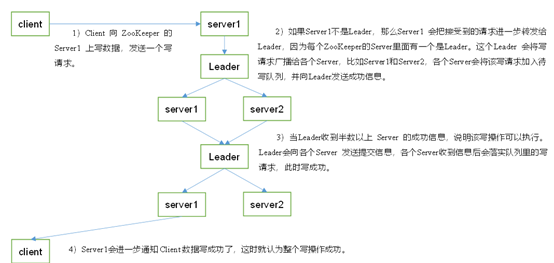
12. Zookeeper寫數據