
列表(list) 基本操作 比如說我要整理一個近期熱映的電影列表: 列表很像數組,但功能超越數組。列表都是從0開始的,python中列表無需事先聲明類型。 從列表後面加上一個新的元素,比如說加個“無名之輩”,是 方法。 刪除列表最後一個元素: 方法。 兩個列表相銜接,用的是 方法。 我想在某個條件下 ...
列表(list)
基本操作
比如說我要整理一個近期熱映的電影列表:
movies = ["venom", "My Neighbor Totor", "Aquaman"]
print(movies)
# ['venom', 'My Neighbor Totor', 'Aquaman']
print(len(movies))
# 3
print(movies[1])
# My Neighbor Totor列表很像數組,但功能超越數組。列表都是從0開始的,python中列表無需事先聲明類型。
從列表後面加上一個新的元素,比如說加個“無名之輩”,是append方法。
movies.append('A Cool Fish')
print(movies)
# ['venom', 'My Neighbor Totor', 'Aquaman','A Cool Fish']刪除列表最後一個元素:pop方法。
movies.pop()
print(movies)
# ['venom', 'My Neighbor Totor']兩個列表相銜接,用的是extend方法。
movies.extend(['Dying To Survive', 'Detective Conan'])
print(movies)
# ['venom', 'My Neighbor Totor', 'Aquaman', 'Dying To Survive', 'Detective Conan']我想在某個條件下刪除一個元素,同時加上一個元素,涉及remove和insert方法。
movies.remove('venom')
print(movies)
# ['My Neighbor Totor', 'Aquaman']
movies.insert(len(movies),'venom')
print(movies)
# ['My Neighbor Totor', 'Aquaman','venom']python中列表可以放任何類型的數據。
迴圈
處理列表需要各種迭代方法。是時候用for...in迴圈了
for movie in movies:
print(movie)
# venom
# My Neighbor Totor
# Aquaman同理while迴圈也是可以的
count=0
while count<len(movies):
print(movies[count])
count+=1一般都推薦for迴圈
列表當然也能嵌套,我們可以用isinstance方法檢測之:
movies = ["venom", ["My Neighbor Totor", "Aquaman"]]
print(isinstance(movies,list))
# Trueif else
如果我想把這個嵌套列表單獨列印出來,可以這麼操作
movies = ["venom", ["My Neighbor Totor", "Aquaman"]]
for movie in movies:
if isinstance(movie, list):
for _movie in movie:
print(_movie)
else:
print(movie)
# venom
# My Neighbor Totor
# Aquaman函數與遞歸:多層嵌套的扁平化
給這個列表再加一層:
movies = ["venom", ["My Neighbor Totor", ["Aquaman"]]]用上節來處理多層嵌套,會導致大量重覆而不優雅的代碼。
首先使用函數讓代碼更加優雅:
movies = ["venom", ["My Neighbor Totor", ["Aquaman"]]]
def flatten(_list):
if(isinstance(_list, list)):
for _item in _list:
flatten(_item)
else:
print(_list)
flatten(movies)為了鞏固所學:再舉一個通過遞歸生成斐波拉契數列第N項的例子:
斐波那契數列(Fibonacci sequence),指的是這樣一個數列:1、1、2、3、5、8、13、21、34、……在數學上,斐波納契數列以如下被以遞推的方法定義:F(1)=1,F(2)=1, F(3)=2,F(n)=F(n-1)+F(n-2)(n>=4,n∈N*)
def fib(n):
if n < 1:
return 'error'
if n == 1 or n == 2:
return 1
else:
return fib(n-1)+fib(n-2)
print(fib(6))
# 8雖然很簡潔,但是n>100就報錯了。因為python的遞歸支持100層
函數
模塊化開發
把上一章的flatten函數單獨用base.py存起來,它就打包為一個模塊。
除了之前提到的,用#註釋,還可以用三重"""作為python的註釋。
再同一個命名文件夾下重新創建一個app.py文件:
import base as util
movies = ["venom", ["My Neighbor Totor", ["Aquaman"]]]
print(util.flatten(movies))
# 預期結果列表更多的內置方法
先學習以下內置的方法(BIF)
- list() :工廠函數,創建一個新的列表
- next() : 返回一個迭代結構(如列表)中的下一項
- id() :返回一個數據對象的唯一標識(記憶體地址)
>>> id(b)
140588731085608- int() :將一個字元串如
'5'轉化為5 - range() :返回一個迭代器,根據需要生成一個指定範圍的數字
>>>range(10) # 從 0 開始到 10
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> range(1, 11) # 從 1 開始到 11
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> range(0, 10, 3) # 步長為 3 , 迭代終點不超過10
[0, 3, 6, 9]- enumerate() :把單個數組創建為帶有索引號的成對列表
>>>seasons = ['Spring', 'Summer', 'Fall', 'Winter']
>>> list(enumerate(seasons))
[(0, 'Spring'), (1, 'Summer'), (2, 'Fall'), (3, 'Winter')]
>>> list(enumerate(seasons, start=1)) # 下標從 1 開始
[(1, 'Spring'), (2, 'Summer'), (3, 'Fall'), (4, 'Winter')]升級你的模塊:參數
扁平化列印只能看到每個數組最小的元素,考慮用縮進來體現彼此的關係。那怎麼做呢?
提示:用range方法實現。
事實上在列印時只需要知道每次迭代的深度,就好處理了。因此需要引入第二個參數
# base.py
def flatten(_list,level=0):
if(isinstance(_list, list)):
for _item in _list:
flatten(_item,level+1)
else:
for step in range(level):
print("\t", end='')
print(_list)# app.py
import base as util
movies = ["venom", ["My Neighbor Totor", ["Aquaman"]],
["My Neighbor Totor", ['000',["Aquaman"]]], 'aaa', ['Aquaman'],'sadas']
print(util.flatten(movies))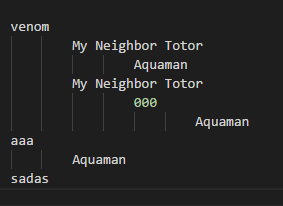
效果出來了。但還有不滿意的地方。如果要相容過去的寫法怎麼辦?
def flatten(_list, count=False, level=0):
if(isinstance(_list, list)):
for _item in _list:
flatten(_item,count,level+1)
else:
if count:
for step in range(level):
print("\t", end='')
print(_list)
else:
print(_list)調用時預設就是不縮進。


