
什麼是Hive? Hive是基於Hadoop HDFS之上的數據倉庫。 我們可以把數據存儲在這個基於數據的倉庫之中,進行分析和處理,完成我們的業務邏輯。 本質上就是一個資料庫 什麼是數據倉庫? 實際上就是一個資料庫。我們可以利用數據倉庫來保存我們的數據。 與一般意義上的資料庫不同。資料庫是一個面向主 ...
===什麼是Hive?
Hive是基於Hadoop HDFS之上的數據倉庫。
我們可以把數據存儲在這個基於數據的倉庫之中,進行分析和處理,完成我們的業務邏輯。
本質上就是一個資料庫
===什麼是數據倉庫?
實際上就是一個資料庫。我們可以利用數據倉庫來保存我們的數據。
與一般意義上的資料庫不同。資料庫是一個面向主題的、集成的、不可更新的、隨時間不變化的數據集合,它用於支持企業和組織的決策分析處理。
1)面向主題的:
數據倉庫中的數據是按照一定的主題來組織的。*主題:指的是用戶使用數據倉庫進行決策時所關心的重點方面。
2)集成的:
數據倉庫中的數據來自於分散的操作性的數據,我們把分散性的數據的操作性的數據從原來的數據中抽取出來進行加工和處理,然後滿足一定的要求才可以進入我們的數據倉庫。
原來的數據,可能來源於我們的Oracle、MySQL等關係型資料庫,文本文件,或者其他的系統。將不同的數據集成起來就形成了數據倉庫。
3)不可更新的
也就是說數據倉庫主要是為了決策分析所提供數據,所以涉及的操作主要是數據的查詢。我們一般都不會再數據倉庫中進行更新和刪除。
4)隨時間不變化
數據倉庫中的數據是不會隨時間產生變化的集合。
===數據倉庫的結構和建立過程
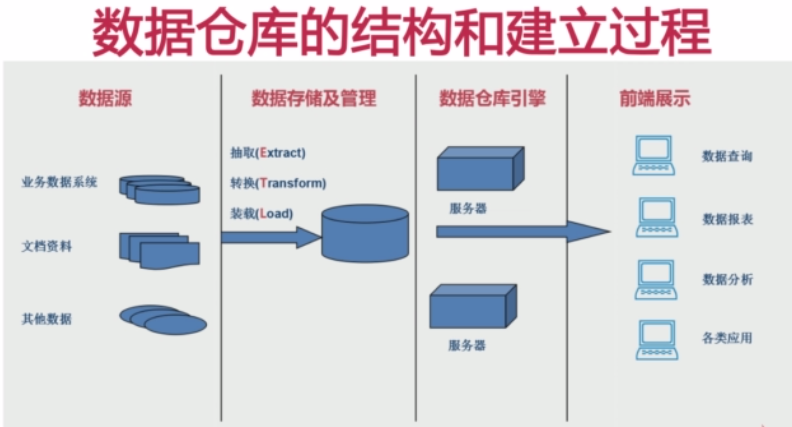
1)數據源:
有可能來自由業務數據系統(關係型資料庫),文檔資料(csv,txt等),其他數據
2)數據存儲和管理:
俗稱的ETL的過程。
•抽取(Extract):把數據源的數據按照一定的方式讀取出來
•轉換(Transform):不同數據源的數據它的格式是不一樣的,不一定滿足我們的要求,所以需要按照一定的規則進行轉換。
•裝在(Load):將滿足格式的數據存取到數據倉庫之中。
3)數據倉庫引擎:
建立了數據倉庫以後,當然是提供對外的數據服務,所以產生了數據倉庫引擎。
在數據倉庫引擎之中包含有不同的伺服器,不同的伺服器提供不同的服務。
4)前端展示:
前端展示的數據均來自數據倉庫引擎中的各個服務。而服務又讀物數據倉庫中的數據。
•數據查詢
•數據報表
•數據分析
•各類應用
===OLTP應用與OLAP應用
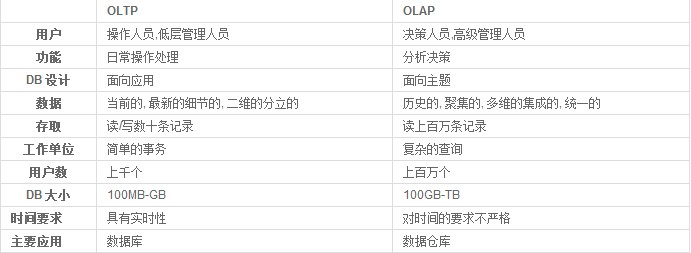
數據處理大致可以分成兩大類
聯機事務處理OLTP(on-line transaction processing):主要面向事務。
聯機分析處理OLAP(on-line analytical processing):主要面向查詢。
OLTP是傳統的關係型資料庫的主要應用。主要是基本的、氣場的事務處理,例如銀行交易。
OLAP是數據倉庫系統的主要應用,支持複雜的分析操作,側重決策支持,並且提供直觀易懂的查詢結果。
OLTP系統強調資料庫記憶體效率,強調記憶體各種指標的命令率,強調綁定變數,強調併發操作。
OLAP系統澤強調數據分析,強調SQL執行市場,強調磁碟I/O,強調分區等。
===數據倉庫中的數據模型
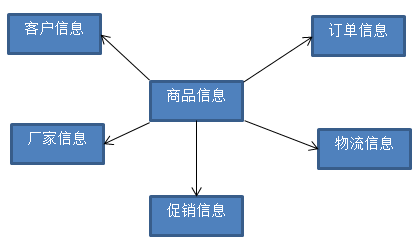
1)星型模型
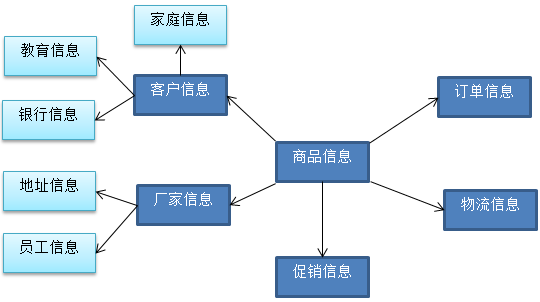
2)雪花模型
星型模型儘管反映了一定的數據倉庫的某種信息,但是在某些情況下可能滿足不了我們的要求。基於星型模型發展出了雪花模型。
比如從上述的星型模型中,我們可以以客戶信息為主題,關聯出其他信息。
這樣這個模型就回越發展越大,發展成為了雪花模型。
===什麼是Hive?
它可以來保存我們的數據,Hive的數據倉庫與傳統意義上的數據倉庫還有區別。
一般來說,我們也可以基於傳統方式(Oracle或者MySQL資料庫)來搭建這個數據倉庫,這個時候數據倉庫中的數據是保存在Oracle或者MySQL的資料庫當中的。
Hive跟傳統方式是不一樣的,Hive是建立在Hadoop HDFS基礎之上的數據倉庫基礎框架。也就是說
--Hive這個數據倉庫中的數據是保存在HDFS上。
--Hive可以用ETL的方式來進行數據提取轉化載入。
--Hive定義了簡單的類似SQL查詢語言,稱為HQL。
--Hive允許熟悉MapReduce開發者的開發自定義的mapper和reducer來處理內建的mapper和reducer無法完成的複雜的分析工作。
--Hive是SQL解析引擎,它將SQL語句轉移成M/R Job,然後在Hadoop上執行。把執行的結果最終反映給用戶。
--Hive的表其實就是HDFS的目錄,Hive的數據其實就是HDFS的文件
===Hive的體繫結構之元數據
Hive將元數據(meta data)存儲在資料庫中(meta store),支持mysql,oracle,derby(預設)等資料庫。
Hive中的元數據包括表的名字,表的列和分區以及屬性,表的屬性(是否為外部表等),表的數據所在目錄等。

===Hive的體繫結構之HQL的執行過程
一條HQL語句如何在Hive的數據倉庫當中中進行查詢的?
由解釋器、編譯器、優化器來共同完成HQL查詢語句從詞法解析、語法解析、編譯、優化以及查詢計劃(Plan)的生成。
生成的查詢計劃存儲在HDFS中,併在隨後又MapReduce調用執行。

*執行計劃:類似於我們的javac命令。
===Hive的體繫結構
--Hadoop:用HDFS進行存儲,利用MapReduce進行計算。
--元數據存儲(MetaStore):通常是存儲在關係資料庫中。
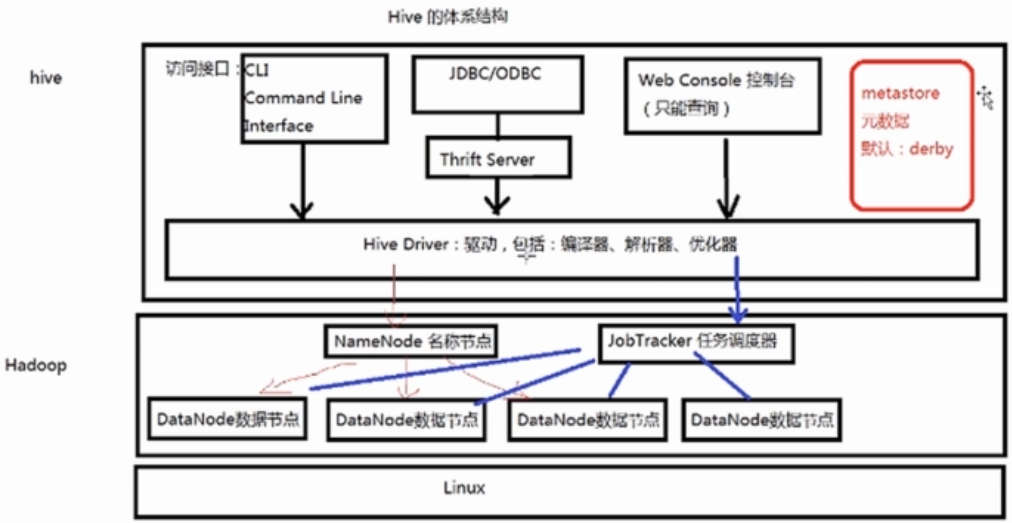
*CUI:與Oracle中的sqlplus類似。
*ThriftServer:可以使用不同(JDBC/ODBC)的語言連接到Thrift Server上進行訪問。
*Web控制台:可以經過Web工具來查詢數據。這個控制台只能進行查詢。
而且在Hive的0.13版本當中並沒集成在Hive的安裝包裡面,需要下載Hive的源代碼進行編譯打包,將打包後的Web控制台部署到Hive的安裝目錄下。
===Hive的安裝
下載最新Hive安裝文件的網址:http://hive.apache.org/
下載過去版本Hive安裝文件的網址:http://archive.apache.org/
由於Hive是基於Hadoop的,所以在安裝Hive之前,需要先安裝Hadoop。可以安裝單機、偽分佈、集群環境的Hadoop。
Hive的安裝有三種模式:嵌入模式、本地模式、遠程模式
1)嵌入模式:
--元數據信息被存儲在Hive自帶的Derby資料庫中。
--只允許創建一個連接
--多用於Demo(演示)
2)本地模式:
--元信息被存儲在MySQL資料庫中。
--MySQL資料庫與Hive運行在同一臺物理機器上。
--多用於開發和測試
3)遠程模式:
--元信息被存儲在MySQL資料庫中。
--MySQL資料庫與Hive運行不在同一臺物理機器上。
--多用於實際的生產運行環境。
===Hive安裝之嵌入模式
需要將安裝文件上傳到Linux操作系統之上。
使用tar -zxvf xxxx.tar.gz解壓縮文件。
執行hive命令,會自動創建Derby資料庫來保存我們的元信息。執行之後將進入命令行視窗。
執行之後會在bin目錄下增加一個metastore_db目錄,這就是Derby資料庫,用它來保存我們的元信息。
也就是說不需要進行任何的配置就可以進入到嵌入式的模式當中。
當然,最好是將我們的Hive路徑配置到配置文件當中,這樣就可以在任何地方執行我們的Hive命令。
配置文件路徑vi ~/.bash_profile,然後使用source ~/.bash_profile命令來使更改生效。
===Hive安裝之遠程模式
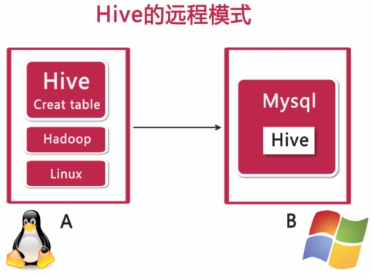
1)將安裝包上傳。
2)解壓縮安裝包:tar -zxvf apache-hive-0.13.0-bin.tar.gz
3)由於需要在Hive中訪問MySQL,所以需要把MySQL的驅動程式Jar包上傳至apache-hive-0.13.0/lib下。
驅動程式包下載地址:http://dev.mysql.com/downloads/connector/j/
4)更改apache-hive-0.13.0/conf的配置文件。在conf下麵追加hive-site.xml文件(註意文件名必須是這個)
具體需要配置哪些值可以去MySQL的官方網站進行查詢。
https://cwiki.apache.org/confluence/display/Hive/AdminManual+MetastoreAdmin#AdminManualMetastoreAdmin-RemoteMetastoreDatabase
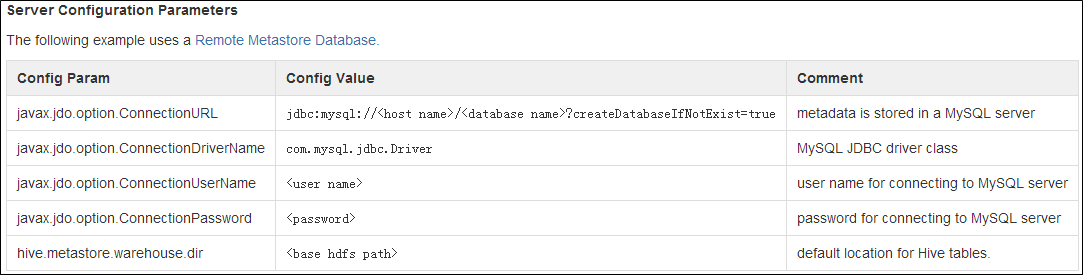
配置文件的內容大概如下:
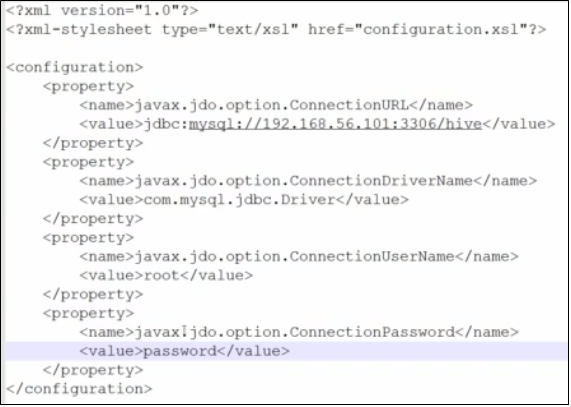
===Hive安裝之本地模式
與遠程模式基本類似,只需要將配置文件中的鏈接地址修改為localhost即可。
===Hive的管理
Hive的啟動方式
--CLI(命令行)方式
--Web界面方式
--遠程服務啟動方式
===Hive的管理之CLI方式(命令行方式)
啟動方式
--直接輸入#<HIVE_HOME>/bin/hive的執行程式
--或者輸入#hive --service cli
===常用的CLI命令
--清屏:Ctrl + L 或者!clear
--查看數據倉庫中的表:show tables;
--查看數據倉庫中的內置函數:show functions;
--查看表結構:desc 表名
--查看HDFS上的文件:dfs -ls 目錄,或者,dfs -lsr 目錄(以遞歸的方式查看目錄)
--執行操作系統的命令:!命令
--執行HQL語句:select * from test1;
註意:select * 的查詢語句並不會轉換成MapReduce作業。
--執行SQL的腳本:source SQL文件
*以上命令是在進入命令行模式下執行的,也可以不進入命令行模式來執行。hive -e 'show tables';
===CLI的靜默模式命令
通常在執行SQL等腳本的時候,會轉換成MapReduce作業,所以在控制臺中會出現大量的日誌信息。
如果不想關註這些日誌信息,就可以啟動CLI的靜默模式。
--啟動方法:hive -S(S為大寫)
===Hive的管理之Web界面方式
--預設埠號:9999
--通過瀏覽器訪問:http://<IP地址>:9999/hwi
--啟動方式:#hive --service hwi
如果執行命令出錯,可以編譯Hive源代碼,作成Jar包,如下:
1)解壓縮:tar -zxvf apache-hive-0.13.0-src.tar.gz
2)進入apache-hive-0.13.0-src/hwi目錄。下麵有個Web目錄,這裡面保存的就是Web管理界面的JSP頁面。
3)使用Jar命令打包:jar cvfM0 hive-hwi-0.13.0.war -C web/ .
4)將war包移動到hive的lib目錄下。
5)修改hive-site.xml配置文件。
<property>
<name>hive.hwi.listen.host</name> //
<value>0.0.0.0</value>
<description>This is the host address the Hive Web Interface will listen on</description>
</property>
<property>
<name>hive.hwi.listen.port</name>
<value>9999</value>
<description>This is the port the Hive Web Interface will listen on</description>
</property>
<property>
<name>hive.hwi.war.file</name>
<value>/usr/lib/hive/lib/hive_hwi.war</value>
<description>This is the WAR file with the jsp content for Hive Web Interface</description>
</property>
6)拷貝JDK的tools.jar:cd <JDK_HOME>/lib/tools.jar <HIVE_HOME>/lib/
如果不拷貝這個工具包,訪問Web界面時會出現500的錯誤。
6)重新啟動Web界面:hive --service hwi > hwi.log
===Hive的遠程服務
如果以JDBC或ODBC的程式登錄到hive中操作數據時,必須選用遠程服務啟動方式。
--埠號:10000
--啟動方式:#hive --service hiveserver
===Hive的數據類型之基本數據類型

--整數類型:tinyint/smallint/int/bigint
--浮點數類型:fload/double
--布爾類型:boolean
--字元串類型:string
每種類型的精度可以參考Hive的官方幫助文檔
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Types
===Hive的數據類型之複雜數據類型
--數組類型:Array,由一系列相同數據類型的元素組成。
create table student1 (
sid int,
sname string,
grade array<float>;
)
數據插入形式:(1, Tom, [80,90,75])
--集合類型:Map,包含key->value鍵值對,可以通過key來訪問元素。
create table student2 (
sid int,
sname string,
grade map<string, float>;
)
數據插入形式:(1, Tom, <'大學語文',85>)
create table student3 (
sid int,
sname string,
grades array<map<sring, float>>;
)
數據插入形式:(1, Tom, [<'大學語文',85>, <'高等數學',90>])
--結構類型:Struct,可以包含不同數據類型的元素,這些元素可以通過"點語法"的方式來得到所需要的元素。
create table student4 (
sid int,
info struct<name:string, age:int, sex:string>;
)
數據插入形式:(1, {'Tom', '20', '男'})
===Hive的數據類型之時間數據類型
--Data(從Hive0.12.0開始支持)
--Timestamp(從0.8.0開始支持)
兩者有區別,也可以使用日期函數進行相互轉換。
===Hive的數據存儲
--基於HDFS
--沒有專門的數據存儲格式
--存儲結構主要包括:資料庫、文件、表、視圖
--可以直接載入文本文件(.txt文件等)
--創建表時,指定Hive數據的列分隔符與行分隔符
===Hive的數據模型
1)表
--Table:內部表
--Partition:分區表
--External Table:外部表
--Bucket Table:桶表
2)視圖
是一個邏輯概念,類似於我們的表
===內部表
--與資料庫中的Table在概念上是類似的。
--每一個Table在Hive中都有一個相應的存儲數據。
--所有的Table數據(不包括External Table)都保存在這個目錄中。
--刪除表的時候,元數據與數據都會被刪除。
創建表的命令:
create table t1 (tid int, tname string, age int;)
可以指定HDFS的創建目錄:
create table t2 (tid int, tname string, age int;) location '/mytable/hive/t2';
可以志明列與列的分隔符:
create table t3 (tid int, tname string, age int;) row format delimited fields terminated by ',';
創建表的同事插入數據:
create table t4 as select * from sample_data;
變更表結構:如添加列
alter table t1 add columns (qnglish int);
刪除表:會將表移入到回收站當中。
drop table t1;
===分區表(Partition Table)
--Partition對應於資料庫中的Partition列的密集索引
--在Hive中,表中的一個Partition對應於表下的一個目錄,所有的Partition的數據都存儲在對應的目錄中。
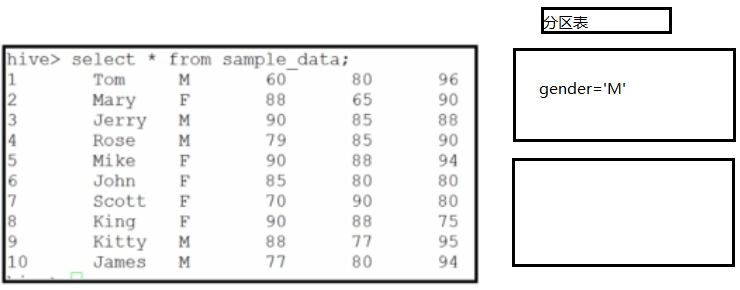
創建一張基於性別的分區表,以逗號分隔:
create table partition_table(sid int, sname string) partitioned by (gender string)
row format delimited fields terminated by ',';
創建之後,查詢一下表的結構可以看分區信息。

向分區表中插入數據
insert into table partition_table partition(gender='M') select sid, sname from sample_data where gender='M';
insert into table partition_table partition(gender='F') select sid, sname from sample_data where gender='F';
分區表是非常有用的,當我們的數據量非常大的時候,我們需要按照一定的條件將數據分區,
這樣在我們查詢操作的時候就能降低需要遍歷的記錄數,從而提高查詢的效率。
===外部表(External Table)
--指向已經在HDFS中存在的數據的表,它也可以來創建Partiton
--它和內部表在元數據的組織上是相同的,也就是說外部表依然是保存在我們的資料庫當中。而實際數據的存儲則有較大的差異。
--外部表"只是一個過程",載入數據和創建表同事完成,並不會移動到數據倉庫目錄中,只是與外部數據建立一個鏈接。當刪除一個外部表時,僅僅刪除該鏈接。
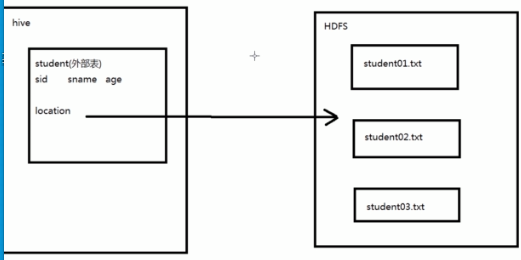
創建外部表
create external table external_student(sid int, sname string, age int) location '/input'
row format delimited fields terminated by ',';
*location是HDFS中的路徑。
===桶表(Bucket Table)
--桶表是對數據進行哈希取值,然後放到不同文件中存儲。
桶表中的數據是經過哈希運算之後,將之打散了存在文件當中。這樣的好處是可以避免造成“熱塊”。
創建桶表
create table bucket_table(sid int, sname string, age int) clustered by (sname) into 5 buckets
(有待細化)
===視圖(View)
--視圖是一種虛表,是一個邏輯概念;可以擴越多張表。
--視圖建立在已有表的基礎上,視圖賴以建立的這些表稱為基表。
--視圖可以簡化複雜的查詢。(最大的優點)
創建視圖
create view empinfo as <SQL語句>
===入門總結
數據倉庫的基本概念
搭建數據倉庫的基本過程
什麼是Hive?Hive的體繫結構
Hive的安裝和管理
Hive的數據模型
--END--


