
一. 概述 在大數據的靜態數據處理中,目前普遍採用的是用 Spark + Hdfs (Hive / Hbase) 的技術架構來對數據進行處理。 但有時候有其他的需求,需要從其他不同數據源不間斷得採集數據,然後存儲到 Hdfs 中進行處理。而追加(append)這種操作在 Hdfs 裡面明顯是比較麻煩 ...
一. 概述
在大數據的靜態數據處理中,目前普遍採用的是用 Spark + Hdfs (Hive / Hbase) 的技術架構來對數據進行處理。
但有時候有其他的需求,需要從其他不同數據源不間斷得採集數據,然後存儲到 Hdfs 中進行處理。而追加(append)這種操作在 Hdfs 裡面明顯是比較麻煩的一件事。所幸有了 Storm 這麼個流數據處理這樣的東西問世,可以幫我們解決這些問題。
不過光有 Storm 還不夠,我們還需要其他中間件來協助我們,讓所有其他數據源都歸於一個通道。這樣就能實現不同數據源以及 Hhdfs 之間的解耦。而這個中間件 Kafka 無疑是一個很好的選擇。
這樣我們就可以讓 Mysql 的增量數據不停得拋出到 Kafka ,而後再讓 storm 不停得從 Kafka 對應的 Topic 讀取數據並寫入到 Hdfs 中。
二. 基本知識
2.1 Mysql binlog 介紹
binlog 即 Mysql 的二進位日誌。它可以說是 Mysql 最重要的日誌了,它記錄了所有的DDL和DML(除了數據查詢語句)語句,以事件形式記錄,還包含語句所執行的消耗的時間,MySQL的二進位日誌是事務安全型的。
上面所說的提到了 DDL 和 DML ,可能有些同學不瞭解,這裡順便說一下:
- DDL:數據定義語言DDL用來創建資料庫中的各種對象-----表、視圖、索引、同義詞、聚簇等如:CREATE TABLE/VIEW/INDEX/SYN/CLUSTER...
- DML:數據操縱語言DML主要有三種形式:插入(INSERT), 更新(UPDATE),以及刪除(DELETE)。
在 Mysql 中,binlog 預設是不開啟的,因為有大約 1% (官方說法)的性能損耗,如果要手動開啟,流程如下:
- vi編輯打開mysql配置文件:
vi /usr/local/mysql/etc/my.cnf在[mysqld] 區塊設置/添加如下,
log-bin=mysql-bin 註意一定要在 [mysqld] 下。
- 重啟 Mysql
pkill mysqld
/usr/local/mysql/bin/mysqld_safe --user=mysql &2.2 kafka
這裡只對 Kafka 做一個基本的介紹,更多的內容可以度娘一波。
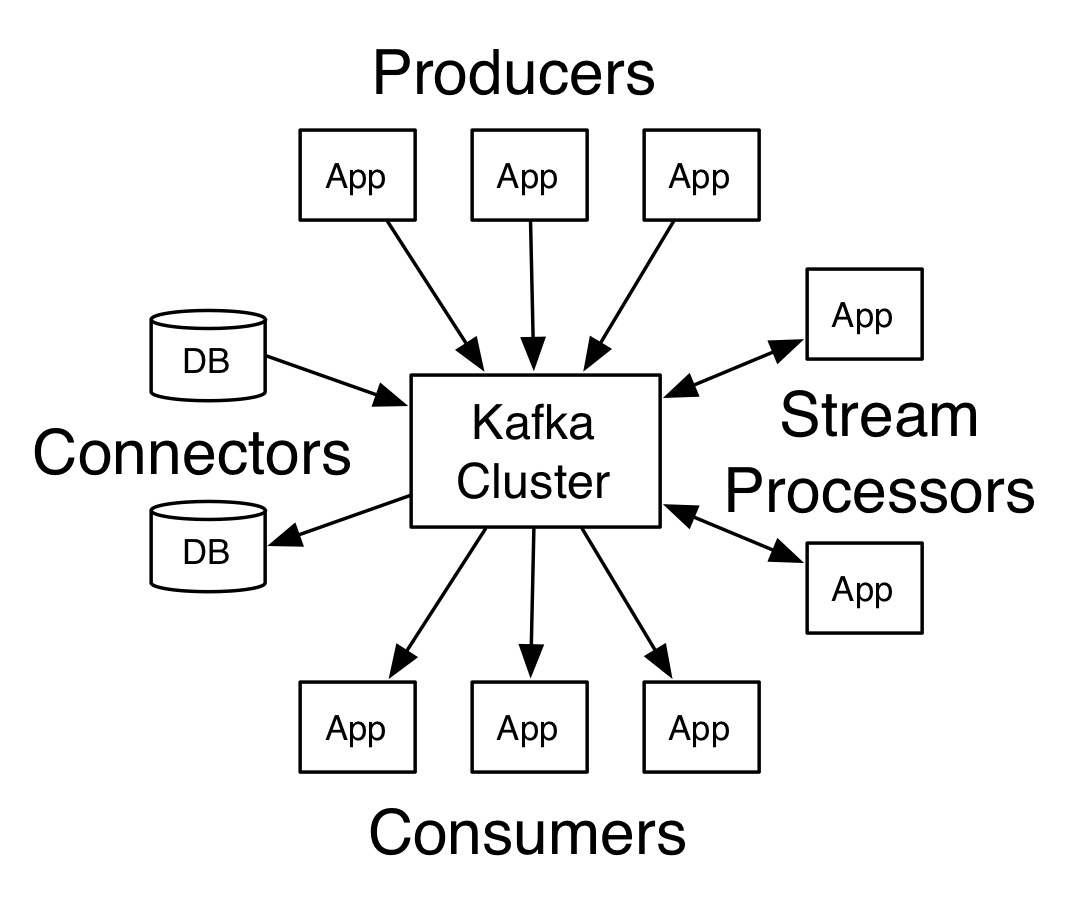
上面的圖片是 kafka 官方的一個圖片,我們目前只需要關註 Producers 和 Consumers 就行了。
Kafka 是一個分散式發佈-訂閱消息系統。分散式方面由 Zookeeper 進行協同處理。消息訂閱其實說白了吧,就是一個隊列,分為消費者和生產者,就像上圖中的內容,有數據源充當 Producer 生產數據到 kafka 中,而有數據充當 Consumers ,消費 kafka 中的數據。
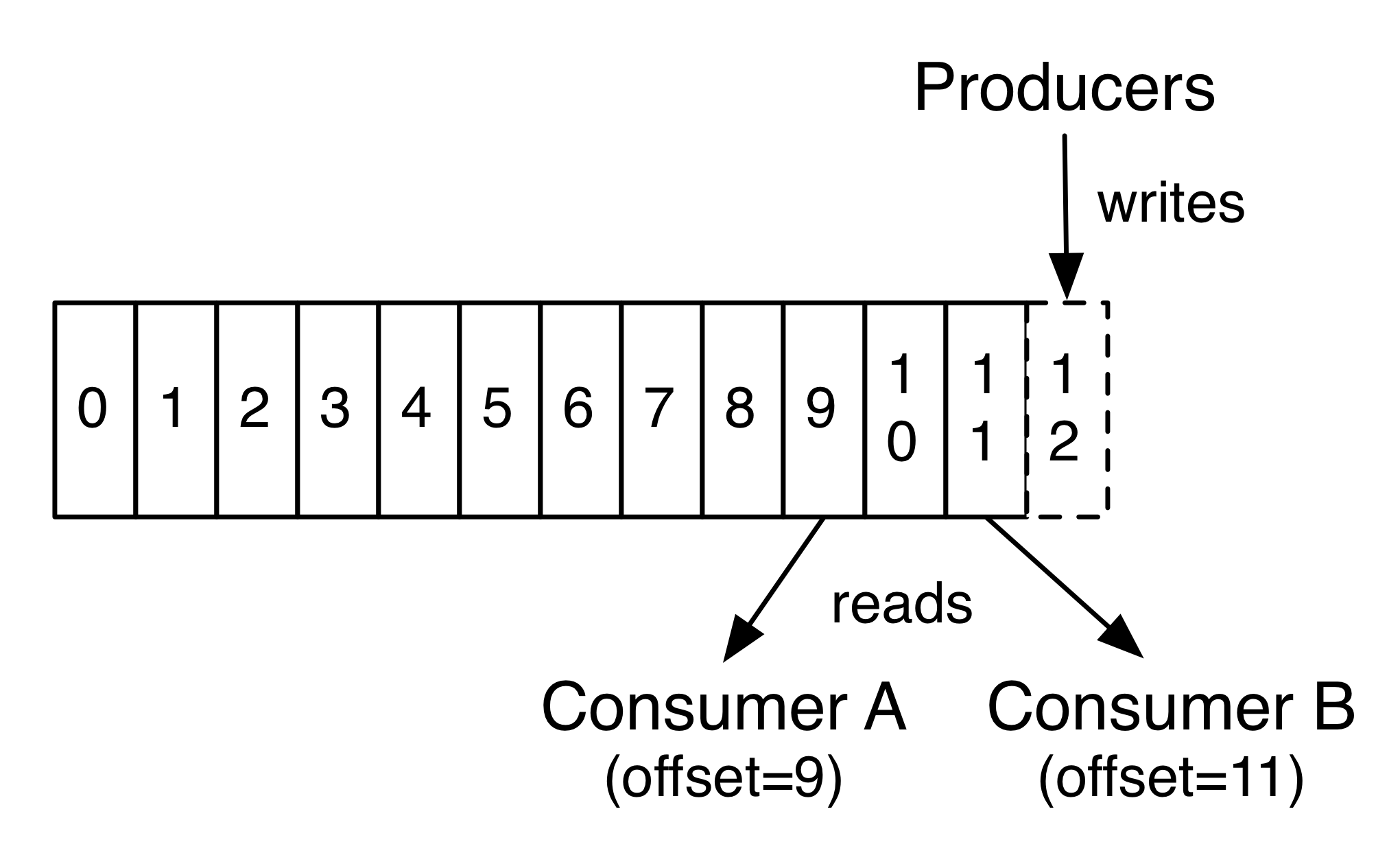
上圖中的 offset 指的是數據的寫入以及消費的位置的信息,這是由 Zookeeper 管理的。也就是說,當 Consumers 重啟或是怎樣,需要重新從 kafka 讀取消息時,總不能讓它從頭開始消費數據吧,這時候就需要有個記錄能告訴你從哪裡開始重新讀取。這就是 offset 。
kafka 中還有一個至關重要的概念,那就是 topic 。不過這個其實還是很好理解的,比如你要訂閱一些消息,你肯定是不會訂閱所有消息的吧,你只需要訂閱你感興趣的主題,比如攝影,編程,搞笑這些主題。而這裡主題的概念其實和 topic 是一樣的。總之,可以將 topic 歸結為通道,kafka 中有很多個通道,不同的 Producer 向其中一個通道生產數據,也就是拋數據進去這個通道,Comsumers 不停得消費通道中的數據。
而我們要做的就是將 Mysql binlog 產生的數據拋到 kafka 中充當作生產者,然後由 storm 充當消費者,不停得消費數據並寫入到 Hdfs 中。
至於怎麼將 binlog 的數據拋到 kafka ,別急,下麵我們就來介紹。
2.3 maxwell
maxwell 這個工具可以很方便得監聽 Mysql 的 binlog ,然後每當 binlog 發生變化時,就會以 json 格式拋出對應的變化數據到 Kafka 中。比如當向 mysql 一張表中插入一條語句的時候,maxwell 就會立刻監聽到 binlog 中有對應的記錄增加,然後將一些信息包括插入的數據都轉化成 json 格式,然後拋到 kafka 指定的 topic 中。
除了 Kafka 外,其實 maxwell 還支持寫入到其他各種中間件,比如 redis。
同時 maxwell 是比較輕量級的工具,只需要在 mysql 中新建一個資料庫供它記錄一些信息,然後就可以直接運行。
三. 使用 maxwell 監聽 binlog
接下來我們將的是如果使用 maxwell ,讓它監聽 mysql 的 binlog 並拋到 kafka 中。maxwell 主要有兩種運行方式。一種是使用配置文件,另一種則是在命令行中添加參數的方式運行。這裡追求方便,只使用命令行的方式進行演示。
這裡介紹一下簡單的將數據拋到 kafka 的命令行腳本吧。
bin/maxwell --user='maxwell' --password='XXXXXX' --host='127.0.0.1' \
--producer=kafka --kafka.bootstrap.servers=localhost:9092 --kafka_topic=maxwell --port=3306各項參數說明如下:
- user:mysql 用戶名
- password:mysql 密碼
- host:Mysql 地址
- producer:指定寫入的中間件類型,比如還有 redies
- kafka.bootstrap.servers:kafka 的地址
- kafka_topic:指明寫入到 kafka 哪個 topic
- port:mysql 埠
啟動之後,maxwell 便開始工作了,當然如果你想要讓這條命令可以在後臺運行的話,可以使用 Linux 的 nohup 命令,這裡就不多贅述,有需要百度即可。
這樣配置的話通常會將整個資料庫的增刪改都給拋到 kafka ,但這樣的需求顯然不常見,更常見的應該是具體監聽對某個庫的操作,或是某個表的操作。
在升級到 1.9.2(最新版本)後,maxwell 為我們提供這樣一個參數,讓我們可以輕鬆實現上述需求:--filter。
這個參數通常包含兩個配置項,exclude 和 include。意思就是讓你指定排除哪些和包含哪些。比如我只想監聽 Adatabase 庫下的 Atable 表的變化。我可以這樣。
--filter='exclude: *.*, include: Adatabase.Atable'這樣我們就可以輕鬆實現監聽 mysql binlog 的變化,並可以定製自己的需求。
OK,這一章我們介紹了 mysql binlog ,kafka 以及 maxwell 的一些內容,下一篇我們將會看到 storm 如何寫入 hdfs 以及定製一些策略。see you~~

