
1、Hadoop生態概況 Hadoop是一個由Apache基金會所開發的分散式系統集成架構,用戶可以在不瞭解分散式底層細節情況下,開發分散式程式,充分利用集群的威力來進行高速運算與存儲,具有可靠、高效、可伸縮的特點 Hadoop的核心是YARN,HDFS,Mapreduce,常用模塊架構如下 我 ...
1、Hadoop生態概況
Hadoop是一個由Apache基金會所開發的分散式系統集成架構,用戶可以在不瞭解分散式底層細節情況下,開發分散式程式,充分利用集群的威力來進行高速運算與存儲,具有可靠、高效、可伸縮的特點
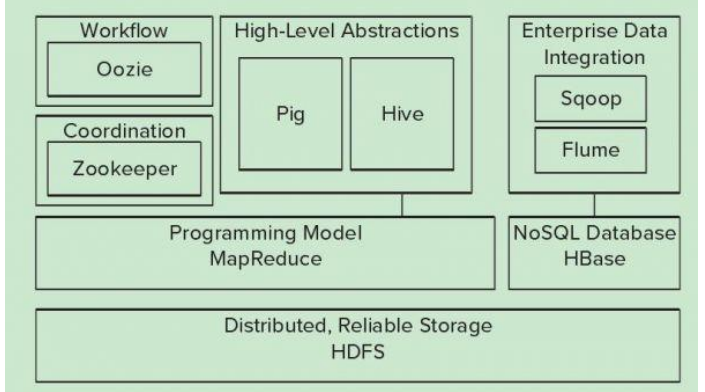
Hadoop的核心是YARN,HDFS,Mapreduce,常用模塊架構如下
![]()
我還是要推薦下我自己創建的大數據資料分享群142973723,這是大數據學習交流的地方,不管你是小白還是大牛,小編都歡迎,不定期分享乾貨,包括我整理的一份適合零基礎學習大數據資料和入門教程。
2、HDFS
源自谷歌的GFS論文,發表於2013年10月,HDFS是GFS的克隆版,HDFS是Hadoop體系中數據存儲管理的基礎,它是一個高度容錯的系統,能檢測和應對硬體故障
HDFS簡化了文件一致性模型,通過流式數據訪問,提供高吞吐量應用程式數據訪問功能,適合帶有大型數據集的應用程式,它提供了一次寫入多次讀取的機制,數據以塊的形式,同時分佈在集群不同物理機器
3、Mapreduce
源自於谷歌的MapReduce論文,用以進行大數據量的計算,它屏蔽了分散式計算框架細節,將計算抽象成map和reduce兩部分
4、HBASE(分散式列存資料庫)
源自谷歌的Bigtable論文,是一個建立在HDFS之上,面向列的針對結構化的數據可伸縮,高可靠,高性能分散式和麵向列的動態模式資料庫
5、zookeeper
解決分散式環境下數據管理問題,統一命名,狀態同步,集群管理,配置同步等
6、HIVE
由Facebook開源,定義了一種類似sql查詢語言,將SQL轉化為mapreduce任務在Hadoop上面執行
7、flume
日誌收集工具
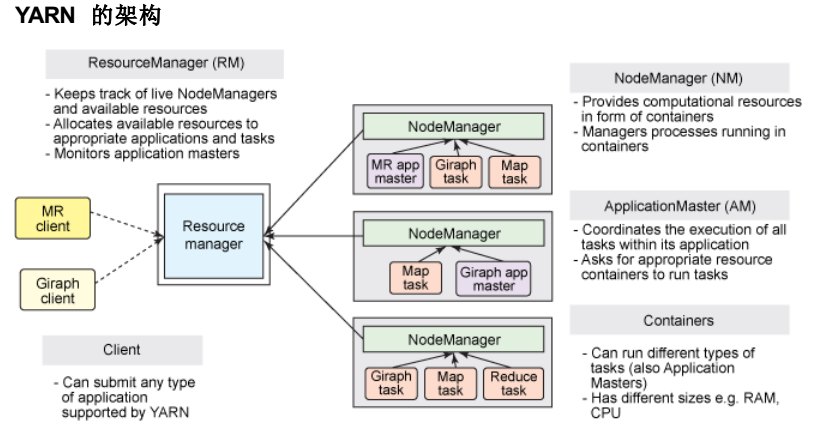
8、yarn分散式資源管理器
是下一代mapreduce,主要解決原始的Hadoop擴展性較差,不支持多種計算框架而提出的,架構如下
![]() 9、spark
9、spark
spark提供了一個更快更通用的數據處理平臺,和Hadoop相比,spark可以讓你的程式在記憶體中運行
10、kafka
分散式消息隊列,主要用於處理活躍的流式數據
11、Hadoop偽分散式部署
目前而言,不收費的Hadoop版本主要有三個,都是國外廠商,分別是
1、Apache原始版本
2、CDH版本,對於國內用戶而言,絕大多數選擇該版本
3、HDP版本
這裡我們選擇CDH版本hadoop-2.6.0-cdh5.8.2.tar.gz,環境是centos7.1,jdk需要1.7.0_55以上
[root@hadoop1 ~]# useradd hadoop
我的系統預設自帶的java環境如下
[root@hadoop1 ~]# ll /usr/lib/jvm/
total 12
lrwxrwxrwx. 1 root root 26 Oct 27 22:48 java -> /etc/alternatives/java_sdk
lrwxrwxrwx. 1 root root 32 Oct 27 22:48 java-1.6.0 -> /etc/alternatives/java_sdk_1.6.0
drwxr-xr-x. 7 root root 4096 Oct 27 22:48 java-1.6.0-openjdk-1.6.0.34.x86_64
lrwxrwxrwx. 1 root root 34 Oct 27 22:48 java-1.6.0-openjdk.x86_64 -> java-1.6.0-openjdk-1.6.0.34.x86_64
lrwxrwxrwx. 1 root root 32 Oct 27 22:44 java-1.7.0 -> /etc/alternatives/java_sdk_1.7.0
lrwxrwxrwx. 1 root root 40 Oct 27 22:44 java-1.7.0-openjdk -> /etc/alternatives/java_sdk_1.7.0_openjdk
drwxr-xr-x. 8 root root 4096 Oct 27 22:44 java-1.7.0-openjdk-1.7.0.75-2.5.4.2.el7_0.x86_64
lrwxrwxrwx. 1 root root 32 Oct 27 22:44 java-1.8.0 -> /etc/alternatives/java_sdk_1.8.0
lrwxrwxrwx. 1 root root 40 Oct 27 22:44 java-1.8.0-openjdk -> /etc/alternatives/java_sdk_1.8.0_openjdk
drwxr-xr-x. 7 root root 4096 Oct 27 22:44 java-1.8.0-openjdk-1.8.0.31-2.b13.el7.x86_64
lrwxrwxrwx. 1 root root 34 Oct 27 22:48 java-openjdk -> /etc/alternatives/java_sdk_openjdk
lrwxrwxrwx. 1 root root 21 Oct 27 22:44 jre -> /etc/alternatives/jre
lrwxrwxrwx. 1 root root 27 Oct 27 22:44 jre-1.6.0 -> /etc/alternatives/jre_1.6.0
lrwxrwxrwx. 1 root root 38 Oct 27 22:44 jre-1.6.0-openjdk.x86_64 -> java-1.6.0-openjdk-1.6.0.34.x86_64/jre
lrwxrwxrwx. 1 root root 27 Oct 27 22:44 jre-1.7.0 -> /etc/alternatives/jre_1.7.0
lrwxrwxrwx. 1 root root 35 Oct 27 22:44 jre-1.7.0-openjdk -> /etc/alternatives/jre_1.7.0_openjdk
lrwxrwxrwx. 1 root root 52 Oct 27 22:44 jre-1.7.0-openjdk-1.7.0.75-2.5.4.2.el7_0.x86_64 -> java-1.7.0-openjdk-1.7.0.75-2.5.4.2.el7_0.x86_64/jre
lrwxrwxrwx. 1 root root 27 Oct 27 22:44 jre-1.8.0 -> /etc/alternatives/jre_1.8.0
lrwxrwxrwx. 1 root root 35 Oct 27 22:44 jre-1.8.0-openjdk -> /etc/alternatives/jre_1.8.0_openjdk
lrwxrwxrwx. 1 root root 48 Oct 27 22:44 jre-1.8.0-openjdk-1.8.0.31-2.b13.el7.x86_64 -> java-1.8.0-openjdk-1.8.0.31-2.b13.el7.x86_64/jre
lrwxrwxrwx. 1 root root 29 Oct 27 22:44 jre-openjdk -> /etc/alternatives/jre_openjdk[root@hadoop1 ~]# cat /home/hadoop/.bashrc 增加如下環境變數
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.75-2.5.4.2.el7_0.x86_64
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_PREFIX=/opt/hadoop/current
export HADOOP_MAPRED_HOME=${HADOOP_PREFIX}
export HADOOP_COMMON_HOME=${HADOOP_PREFIX}
export HADOOP_HDFS_HOME=${HADOOP_PREFIX}
export HADOOP_YARN_HOME=${HADOOP_PREFIX}
export HTTPS_CATALINA_HOME=${HADOOP_PREFIX}/share/hadoop/httpfs/tomcat
export HADOOP_CONF_DIR=/etc/hadoop/conf
export YARN_CONF_DIR=/etc/hadoop/conf
export HTTPS_CONFIG=/etc/hadoop/conf
export PATH=$PATH:$HADOOP_PREFIX/bin:$HADOOP_PREFIX/sbin
我們將Hadoop安裝在/opt/hadoop目錄下麵,建立如下軟連接,配置文件放在/etc/hadoop/conf目錄下麵
[root@hadoop1 hadoop]# ll current
lrwxrwxrwx 1 root root 21 Oct 29 11:02 current -> hadoop-2.6.0-cdh5.8.2
做好如下授權
[root@hadoop1 hadoop]# chown -R hadoop.hadoop hadoop-2.6.0-cdh5.8.2
[root@hadoop1 hadoop]# chown -R hadoop.hadoop /etc/hadoop/conf
CDH5新版本的Hadoop啟動服務腳步位於$HADOOP_HOME/sbin目錄下麵,啟動服務有如下
namenode
secondarynamenode
datanode
resourcemanger
nodemanager
這裡以Hadoop用戶來進行管理和啟動Hadoop的各種服務
[root@hadoop1 etc]# cd /etc/hadoop/conf/
[root@hadoop1 conf]# vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1</value>
</property>
</configuration>
格式化namenode
[root@hadoop1 conf]# cd /opt/hadoop/current/bin
[root@hadoop1 bin]# hdfs namenode -format
啟動namenode服務
[root@hadoop1 bin]# cd /opt/hadoop/current/sbin/
[root@hadoop1 sbin]# ./hadoop-daemon.sh start namenode
[hadoop@hadoop1 sbin]$ ./hadoop-daemon.sh start datanode
查看服務啟動情況
![]()
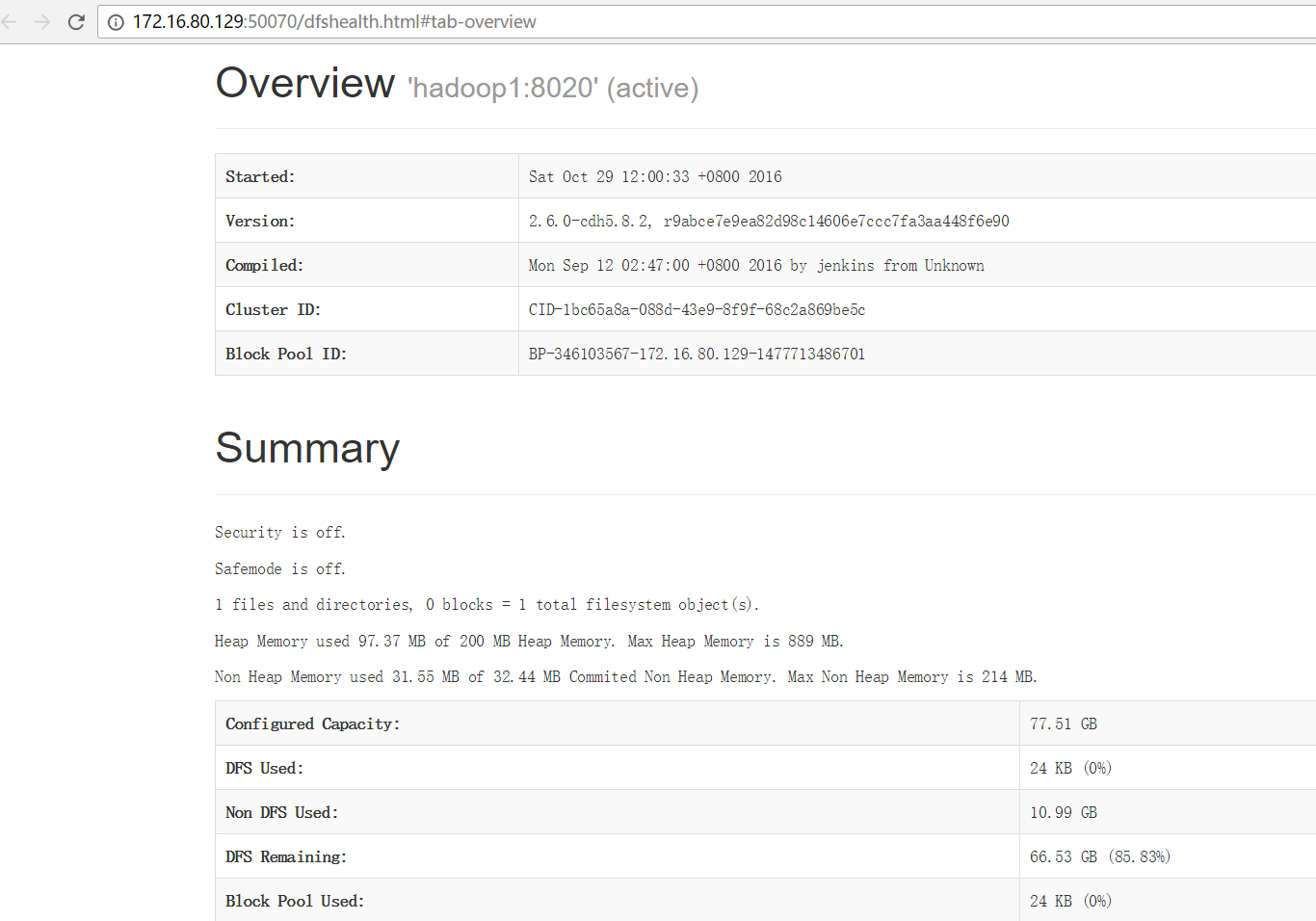
namenode啟動完成後,就可以通過web界面查看狀態了,預設埠是50070,我們訪問測試下
![]()


