
追溯上一篇 CPU 使用率是什麼,並通過使用 top、vmstat、pidstat 等工具, 排查高 CPU 使用率的進程,然後再使用 perf top 工具,定位應用內部函數的問題。似乎感覺高 CPU 使用率的問題,還是挺容易排查的。 那是不是所有 CPU 使用率高的問題,都可以這麼分析呢?前面的 ...
追溯上一篇 CPU 使用率是什麼,並通過使用 top、vmstat、pidstat 等工具, 排查高 CPU 使用率的進程,然後再使用 perf top 工具,定位應用內部函數的問題。似乎感覺高 CPU 使用率的問題,還是挺容易排查的。 那是不是所有 CPU 使用率高的問題,都可以這麼分析呢?前面的內容,系統的 CPU 使用率,不僅包括進程用戶態和內核態的運行,還包 括中斷處理、等待 I/O 以及內核線程等。所以,當你發現系統的 CPU 使用率很高的時候,不一 定能找到相對應的高 CPU 使用率的進程。 今天,我就用一個 Nginx + PHP 的 Web 服務的案例,來分析這種情況。
你的準備
探究系統 CPU 使用率高的情況,所以這次實驗的準備工作,與之前準備工作基本 相同,差別在於案例所用的 Docker 鏡像不同。
本次案例還是基於 Ubuntu 18.04,同樣適用於其他的 Linux 系統。
我使用的案例環境如下所 示:
機器配置:2 CPU,8GB 記憶體
預先安裝 docker、sysstat、perf、ab 等工具,
如 apt install docker.io sysstat linuxtools-common apache2-utils
前面我們講到過,ab(apache bench)是一個常用的 HTTP 服務性能測試工具,這裡同樣用來 模擬 Nginx 的客戶端。
由於 Nginx 和 PHP 的配置比較麻煩,我把它們打包成了兩個 Docker 鏡像,這樣只需要運行兩個容器,就可以得到模擬環境。
註意,這個案例要用到兩台虛擬機,如下圖所示:
你可以看到,其中一臺用作 Web 伺服器,來模擬性能問題;另一臺用作 Web 伺服器的客戶 端,來給 Web 服務增加壓力請求。使用兩台虛擬機是為了相互隔離,避免“交叉感染”。
接下來,我們打開兩個終端,分別 SSH 登錄到兩台機器上,並安裝上述工具。
同樣註意,下麵所有命令都預設以 root 用戶運行,如果你是用普通用戶身份登陸系統,請運行 sudo su root 命令切換到 root 用戶。
走到這一步,準備工作就完成了。接下來,我們正式進入操作環節。
- 溫馨提示:案例中 PHP 應用的核心邏輯比較簡單,你可能一眼就能看出問題,但 實際生產環境中的源碼就複雜多了。
- 所以,我依舊建議,操作之前別看源碼,避免先入為主,而要把它當成一個黑盒來分析。這樣,你可以更好把握,怎麼從系統的 資源使用問題出發,分析出瓶頸所在的應用,以及瓶頸在應用中大概的位置。
操作和分析
首先,我們在第一個終端,執行下麵的命令運行 Nginx 和 PHP 應用:
$ docker run ‐‐name nginx ‐p 10000:80 ‐itd feisky/nginx:sp $ docker run ‐‐name phpfpm ‐itd ‐‐network container:nginx feisky/php‐fpm:sp
然後,在第二個終端,使用 curl 訪問 http://[VM1 的 IP]:10000,確認 Nginx 已正常啟動。你 應該可以看到 It works! 的響應。
# 192.168.0.10 是第一臺虛擬機的 IP 地址 $ curl http://192.168.0.10:10000/ It works!
接著,我們來測試一下這個 Nginx 服務的性能。在第二個終端運行下麵的 ab 命令。要註意, 與上次操作不同的是,這次我們需要併發 100 個請求測試 Nginx 性能,總共測試 1000 個請求。
# 併發 100 個請求測試 Nginx 性能,總共測試 1000 個請求 $ ab ‐c 100 ‐n 1000 http://192.168.0.10:10000/ This is ApacheBench, Version 2.3 <$Revision: 1706008 $> Copyright 1996 Adam Twiss, Zeus Technology Ltd, ... Requests per second: 87.86 [#/sec] (mean) Time per request: 1138.229 [ms] (mean) ...
從 ab 的輸出結果我們可以看到,Nginx 能承受的每秒平均請求數,只有 87 多一點,是不是感 覺它的性能有點差呀。那麼,到底是哪裡出了問題呢?我們再用 top 和 pidstat 來觀察一下。
這次,我們在第二個終端,將測試的併發請求數改成 5,同時把請求時長設置為 10 分鐘(-t 600)。這樣,當你在第一個終端使用性能分析工具時, Nginx 的壓力還是繼續的。
繼續在第二個終端運行 ab 命令:
$ ab ‐c 5 ‐t 600 http://192.168.0.10:10000/
然後,我們在第一個終端運行 top 命令,觀察系統的 CPU 使用情況:
$ top ... %Cpu(s): 80.8 us, 15.1 sy, 0.0 ni, 2.8 id, 0.0 wa, 0.0 hi, 1.3 si, 0.0 st ... PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 6882 root 20 0 8456 5052 3884 S 2.7 0.1 0:04.78 docker‐containe 6947 systemd+ 20 0 33104 3716 2340 S 2.7 0.0 0:04.92 nginx 7494 daemon 20 0 336696 15012 7332 S 2.0 0.2 0:03.55 php‐fpm 7495 daemon 20 0 336696 15160 7480 S 2.0 0.2 0:03.55 php‐fpm 10547 daemon 20 0 336696 16200 8520 S 2.0 0.2 0:03.13 php‐fpm 10155 daemon 20 0 336696 16200 8520 S 1.7 0.2 0:03.12 php‐fpm 10552 daemon 20 0 336696 16200 8520 S 1.7 0.2 0:03.12 php‐fpm 15006 root 20 0 1168608 66264 37536 S 1.0 0.8 9:39.51 dockerd 4323 root 20 0 0 0 0 I 0.3 0.0 0:00.87 kworker/u4:1 ...
觀察 top 輸出的進程列表可以發現,CPU 使用率最高的進程也只不過才 2.7%,看起來並不 高。
然而,再看系統 CPU 使用率( %Cpu )這一行,你會發現,系統的整體 CPU 使用率是比較高 的:用戶 CPU 使用率(us)已經到了 80%,系統 CPU 為 15.1%,而空閑 CPU (id)則只有 2.8%。
為什麼用戶 CPU 使用率這麼高呢?我們再重新分析一下進程列表,看看有沒有可疑進程:
- docker-containerd 進程是用來運行容器的,2.7% 的 CPU 使用率看起來正常;
- Nginx 和 php-fpm 是運行 Web 服務的,它們會占用一些 CPU 也不意外,並且 2% 的 CPU 使用率也不算高;
- 再往下看,後面的進程呢,只有 0.3% 的 CPU 使用率,看起來不太像會導致用戶 CPU 使用 率達到 80%。
那就奇怪了,明明用戶 CPU 使用率都 80% 了,可我們挨個分析了一遍進程列表,還是找不到 高 CPU 使用率的進程。看來 top 是不管用了,那還有其他工具可以查看進程 CPU 使用情況 嗎?不知道你記不記得我們的老朋友 pidstat,它可以用來分析進程的 CPU 使用情況。
接下來,我們還是在第一個終端,運行 pidstat 命令:
# 間隔 1 秒輸出一組數據(按 Ctrl+C 結束) $ pidstat 1 ... 04:36:24 UID PID %usr %system %guest %wait %CPU CPU Command 04:36:25 0 6882 1.00 3.00 0.00 0.00 4.00 0 docker‐containe 04:36:25 101 6947 1.00 2.00 0.00 1.00 3.00 1 nginx 04:36:25 1 14834 1.00 1.00 0.00 1.00 2.00 0 php‐fpm 04:36:25 1 14835 1.00 1.00 0.00 1.00 2.00 0 php‐fpm 04:36:25 1 14845 0.00 2.00 0.00 2.00 2.00 1 php‐fpm 04:36:25 1 14855 0.00 1.00 0.00 1.00 1.00 1 php‐fpm 04:36:25 1 14857 1.00 2.00 0.00 1.00 3.00 0 php‐fpm 04:36:25 0 15006 0.00 1.00 0.00 0.00 1.00 0 dockerd 04:36:25 0 15801 0.00 1.00 0.00 0.00 1.00 1 pidstat 04:36:25 1 17084 1.00 0.00 0.00 2.00 1.00 0 stress 04:36:25 0 31116 0.00 1.00 0.00 0.00 1.00 0 atopacctd ...
觀察一會兒,你是不是發現,所有進程的 CPU 使用率也都不高啊,最高的 Docker 和 Nginx 也 只有 4% 和 3%,即使所有進程的 CPU 使用率都加起來,也不過是 21%,離 80% 還差得遠 呢!
最早的時候,我碰到這種問題就完全懵了:明明用戶 CPU 使用率已經高達 80%,但我卻怎麼都 找不到是哪個進程的問題。到這裡,你也可以想想,你是不是也遇到過這種情況?還能不能再做 進一步的分析呢?
後來我發現,會出現這種情況,很可能是因為前面的分析漏了一些關鍵信息。你可以先暫停一 下,自己往上翻,重新操作檢查一遍。或者,我們一起返回去分析 top 的輸出,看看能不能有 新發現。
現在,我們回到第一個終端,重新運行 top 命令,並觀察一會兒:
$ top top ‐ 04:58:24 up 14 days, 15:47, 1 user, load average: 3.39, 3.82, 2.74 Tasks: 149 total, 6 running, 93 sleeping, 0 stopped, 0 zombie %Cpu(s): 77.7 us, 19.3 sy, 0.0 ni, 2.0 id, 0.0 wa, 0.0 hi, 1.0 si, 0.0 st KiB Mem : 8169348 total, 2543916 free, 457976 used, 5167456 buff/cache KiB Swap: 0 total, 0 free, 0 used. 7363908 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 6947 systemd+ 20 0 33104 3764 2340 S 4.0 0.0 0:32.69 nginx 6882 root 20 0 12108 8360 3884 S 2.0 0.1 0:31.40 docker‐containe 15465 daemon 20 0 336696 15256 7576 S 2.0 0.2 0:00.62 php‐fpm 15466 daemon 20 0 336696 15196 7516 S 2.0 0.2 0:00.62 php‐fpm 15489 daemon 20 0 336696 16200 8520 S 2.0 0.2 0:00.62 php‐fpm 6948 systemd+ 20 0 33104 3764 2340 S 1.0 0.0 0:00.95 nginx 15006 root 20 0 1168608 65632 37536 S 1.0 0.8 9:51.09 dockerd 15476 daemon 20 0 336696 16200 8520 S 1.0 0.2 0:00.61 php‐fpm 15477 daemon 20 0 336696 16200 8520 S 1.0 0.2 0:00.61 php‐fpm 24340 daemon 20 0 8184 1616 536 R 1.0 0.0 0:00.01 stress 24342 daemon 20 0 8196 1580 492 R 1.0 0.0 0:00.01 stress 24344 daemon 20 0 8188 1056 492 R 1.0 0.0 0:00.01 stress 24347 daemon 20 0 8184 1356 540 R 1.0 0.0 0:00.01 stress ...
這次從頭開始看 top 的每行輸出,咦?Tasks 這一行看起來有點奇怪,就緒隊列中居然有 6 個 Running 狀態的進程(6 running),是不是有點多呢?
回想一下 ab 測試的參數,併發請求數是 5。再看進程列表裡, php-fpm 的數量也是 5,再加 上 Nginx,好像同時有 6 個進程也並不奇怪。但真的是這樣嗎?
再仔細看進程列表,這次主要看 Running(R) 狀態的進程。你有沒有發現, Nginx 和所有的 php-fpm 都處於 Sleep(S)狀態,而真正處於 Running(R)狀態的,卻是幾個 stress 進 程。這幾個 stress 進程就比較奇怪了,需要我們做進一步的分析。
我們還是使用 pidstat 來分析這幾個進程,並且使用 -p 選項指定進程的 PID。首先,從上面 top 的結果中,找到這幾個進程的 PID。比如,先隨便找一個 24344,然後用 pidstat 命令看一 下它的 CPU 使用情況:
$ pidstat ‐p 24344 16:14:55 UID PID %usr %system %guest %wait %CPU CPU Command
奇怪,居然沒有任何輸出。難道是 pidstat 命令出問題了嗎?之前我說過,在懷疑性能工具出問 題前,最好還是先用其他工具交叉確認一下。那用什麼工具呢? ps 應該是最簡單易用的。我們 在終端里運行下麵的命令,看看 24344 進程的狀態:
# 從所有進程中查找 PID 是 24344 的進程 $ ps aux | grep 24344 root 9628 0.0 0.0 14856 1096 pts/0 S+ 16:15 0:00 grep ‐‐color=auto 24344
還是沒有輸出。現在終於發現問題,原來這個進程已經不存在了,所以 pidstat 就沒有任何輸 出。既然進程都沒了,那性能問題應該也跟著沒了吧。我們再用 top 命令確認一下:
$ top ... %Cpu(s): 80.9 us, 14.9 sy, 0.0 ni, 2.8 id, 0.0 wa, 0.0 hi, 1.3 si, 0.0 st ... PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 6882 root 20 0 12108 8360 3884 S 2.7 0.1 0:45.63 docker‐containe 6947 systemd+ 20 0 33104 3764 2340 R 2.7 0.0 0:47.79 nginx 3865 daemon 20 0 336696 15056 7376 S 2.0 0.2 0:00.15 php‐fpm 6779 daemon 20 0 8184 1112 556 R 0.3 0.0 0:00.01 stress ...
好像又錯了。結果還跟原來一樣,用戶 CPU 使用率還是高達 80.9%,系統 CPU 接近 15%,而 空閑 CPU 只有 2.8%,Running 狀態的進程有 Nginx、stress 等。
可是,剛剛我們看到 stress 進程不存在了,怎麼現在還在運行呢?再細看一下 top 的輸出,原 來,這次 stress 進程的 PID 跟前面不一樣了,原來的 PID 24344 不見了,現在的是 6779。
進程的 PID 在變,這說明什麼呢?在我看來,要麼是這些進程在不停地重啟,要麼就是全新的 進程,這無非也就兩個原因:
- 第一個原因,進程在不停地崩潰重啟,比如因為段錯誤、配置錯誤等等,這時,進程在退出 後可能又被監控系統自動重啟了。
- 第二個原因,這些進程都是短時進程,也就是在其他應用內部通過 exec 調用的外面命令。這 些命令一般都只運行很短的時間就會結束,你很難用 top 這種間隔時間比較長的工具發現 (上面的案例,我們碰巧發現了)。
至於 stress,我們前面提到過,它是一個常用的壓力測試工具。它的 PID 在不斷變化中,看起 來像是被其他進程調用的短時進程。要想繼續分析下去,還得找到它們的父進程。
要怎麼查找一個進程的父進程呢?沒錯,用 pstree 就可以用樹狀形式顯示所有進程之間的關 系:
$ pstree | grep stress |‐docker‐containe‐+‐php‐fpm‐+‐php‐fpm‐‐‐sh‐‐‐stress | |‐3*[php‐fpm‐‐‐sh‐‐‐stress‐‐‐stress]
從這裡可以看到,stress 是被 php-fpm 調用的子進程,並且進程數量不止一個(這裡是 3 個)。找到父進程後,我們能進入 app 的內部分析了。
首先,當然應該去看看它的源碼。運行下麵的命令,把案例應用的源碼拷貝到 app 目錄,然後 再執行 grep 查找是不是有代碼再調用 stress 命令:
# 拷貝源碼到本地 $ docker cp phpfpm:/app . # grep 查找看看是不是有代碼在調用 stress 命令 $ grep stress ‐r app app/index.php:// fake I/O with stress (via write()/unlink()). app/index.php:$result = exec("/usr/local/bin/stress ‐t 1 ‐d 1 2>&1", $output, $status);
找到了,果然是 app/index.php 文件中直接調用了 stress 命令。
再來看看 app/index.php 的源代碼:
$ cat app/index.php <?php // fake I/O with stress (via write()/unlink()). $result = exec("/usr/local/bin/stress ‐t 1 ‐d 1 2>&1", $output, $status); if (isset($_GET["verbose"]) && $_GET["verbose"]==1 && $status != 0) { echo "Server internal error: "; print_r($output); } else { echo "It works!"; } ?>
可以看到,源碼里對每個請求都會調用一個 stress 命令,模擬 I/O 壓力。從註釋上看,stress 會通過 write() 和 unlink() 對 I/O 進程進行壓測,看來,這應該就是系統 CPU 使用率升高的根 源了。
不過,stress 模擬的是 I/O 壓力,而之前在 top 的輸出中看到的,卻一直是用戶 CPU 和系統 CPU 升高,並沒見到 iowait 升高。這又是怎麼回事呢?stress 到底是不是 CPU 使用率升高的 原因呢?
我們還得繼續往下走。從代碼中可以看到,給請求加入 verbose=1 參數後,就可以查看 stress 的輸出。你先試試看,在第二個終端運行:
$ curl http://192.168.0.10:10000?verbose=1 Server internal error: Array ( [0] => stress: info: [19607] dispatching hogs: 0 cpu, 0 io, 0 vm, 1 hdd [1] => stress: FAIL: [19608] (563) mkstemp failed: Permission denied [2] => stress: FAIL: [19607] (394) <‐‐ worker 19608 returned error 1 [3] => stress: WARN: [19607] (396) now reaping child worker processes [4] => stress: FAIL: [19607] (400) kill error: No such process [5] => stress: FAIL: [19607] (451) failed run completed in 0s )
看錯誤消息 mkstemp failed: Permission denied ,以及 failed run completed in 0s。原來 stress 命令並沒有成功,它因為許可權問題失敗退出了。看來,我們發現了一個 PHP 調用外部 stress 命令的 bug:沒有許可權創建臨時文件。
從這裡我們可以猜測,正是由於許可權錯誤,大量的 stress 進程在啟動時初始化失敗,進而導致 用戶 CPU 使用率的升高。
分析出問題來源,下一步是不是就要開始優化了呢?當然不是!既然只是猜測,那就需要再確認 一下,這個猜測到底對不對,是不是真的有大量的 stress 進程。該用什麼工具或指標呢?
我們前面已經用了 top、pidstat、pstree 等工具,沒有發現大量的 stress 進程。那麼,還有什 麽其他的工具可以用嗎?
還記得上一期提到的 perf 嗎?它可以用來分析 CPU 性能事件,用在這裡就很合適。依舊在第 一個終端中運行 perf record -g 命令 ,並等待一會兒(比如 15 秒)後按 Ctrl+C 退出。然後再 運行 perf report 查看報告:
# 記錄性能事件,等待大約 15 秒後按 Ctrl+C 退出 $ perf record ‐g # 查看報告 $ perf report
這樣,你就可以看到下圖這個性能報告:
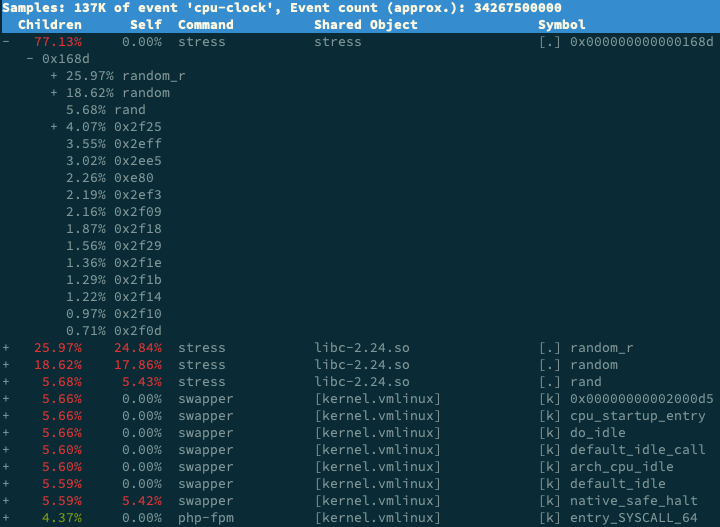
你看,stress 占了所有 CPU 時鐘事件的 77%,而 stress 調用調用棧中比例最高的,是隨機數 生成函數 random(),看來它的確就是 CPU 使用率升高的元凶了。隨後的優化就很簡單了,只 要修複許可權問題,並減少或刪除 stress 的調用,就可以減輕系統的 CPU 壓力。
當然,實際生產環境中的問題一般都要比這個案例複雜,在你找到觸發瓶頸的命令行後,卻可能 發現,這個外部命令的調用過程是應用核心邏輯的一部分,並不能輕易減少或者刪除。
這時,你就得繼續排查,為什麼被調用的命令,會導致 CPU 使用率升高或 I/O 升高等問題。這 些複雜場景的案例,我會在後面的綜合實戰里詳細分析。
最後,在案例結束時,不要忘了清理環境,執行下麵的 Docker 命令,停止案例中用到的 Nginx 進程:
$ docker rm ‐f nginx phpfpm
execsnoop
在這個案例中,我們使用了 top、pidstat、pstree 等工具分析了系統 CPU 使用率高的問題, 併發現 CPU 升高是短時進程 stress 導致的,但是整個分析過程還是比較複雜的。對於這類問 題,有沒有更好的方法監控呢?
execsnoop 就是一個專為短時進程設計的工具。它通過 ftrace 實時監控進程的 exec() 行為, 並輸出短時進程的基本信息,包括進程 PID、父進程 PID、命令行參數以及執行的結果。
比如,用 execsnoop 監控上述案例,就可以直接得到 stress 進程的父進程 PID 以及它的命令 行參數,並可以發現大量的 stress 進程在不停啟動:
# 按 Ctrl+C 結束 $ execsnoop PCOMM PID PPID RET ARGS sh 30394 30393 0 stress 30396 30394 0 /usr/local/bin/stress ‐t 1 ‐d 1 sh 30398 30393 0 stress 30399 30398 0 /usr/local/bin/stress ‐t 1 ‐d 1 sh 30402 30400 0 stress 30403 30402 0 /usr/local/bin/stress ‐t 1 ‐d 1 sh 30405 30393 0 stress 30407 30405 0 /usr/local/bin/stress ‐t 1 ‐d 1 ...
execsnoop 所用的 ftrace 是一種常用的動態追蹤技術,一般用於分析 Linux 內核的運行時行 為,後面課程我也會詳細介紹並帶你使用。
小結
碰到常規問題無法解釋的 CPU 使用率情況時,首先要想到有可能是短時應用導致的問題,比如 有可能是下麵這兩種情況。
第一,應用里直接調用了其他二進位程式,這些程式通常運行時間比較短,通過 top 等工具 也不容易發現。
第二,應用本身在不停地崩潰重啟,而啟動過程的資源初始化,很可能會占用相當多的 CPU。
對於這類進程,我們可以用 pstree 或者 execsnoop 找到它們的父進程,再從父進程所在的應 用入手,排查問題的根源。
思考
最後,我想邀請你一起來聊聊,你所碰到的 CPU 性能問題。有沒有哪個印象深刻的經歷可以跟 我分享呢?或者,在今天的案例操作中,你遇到了什麼問題,又解決了哪些呢?你可以結合我的 講述,總結自己的思路。


